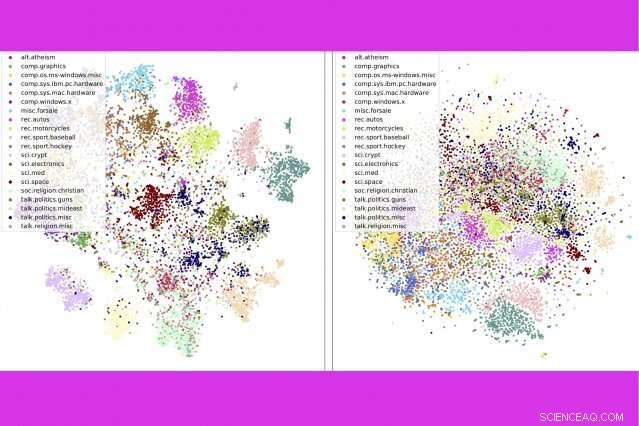
En un nuevo estudio, investigadores de MIT e IBM combinan tres herramientas populares de análisis de texto:modelado de temas, incrustaciones de palabras, y transporte óptimo:para comparar miles de documentos por segundo. Aquí, muestran que su método (izquierda) agrupa las publicaciones de los grupos de noticias por categoría más estrechamente que un método de la competencia. Crédito:Instituto de Tecnología de Massachusetts
Con miles de millones de libros noticias, y documentos en línea, nunca ha habido un mejor momento para leer, si tiene tiempo para examinar todas las opciones. "Hay un montón de mensajes de texto en Internet, "dice Justin Solomon, profesor asistente en el MIT. "Cualquier cosa que ayude a cortar todo ese material es extremadamente útil".
Con el MIT-IBM Watson AI Lab y su Grupo de procesamiento de datos geométricos en el MIT, Solomon presentó recientemente una nueva técnica para cortar grandes cantidades de texto en la Conferencia sobre Sistemas de Procesamiento de Información Neural (NeurIPS). Su método combina tres herramientas populares de análisis de texto:modelado de temas, incrustaciones de palabras, y transporte óptimo para ofrecer mejores Resultados más rápidos que los métodos de la competencia en un punto de referencia popular para clasificar documentos.
Si un algoritmo sabe lo que le gustó en el pasado, puede escanear millones de posibilidades en busca de algo similar. A medida que mejoran las técnicas de procesamiento del lenguaje natural, esas sugerencias de "también podría gustarle" son cada vez más rápidas y relevantes.
En el método presentado en NeurIPS, un algoritmo resume una colección de, decir, libros, en temas basados en palabras de uso común en la colección. Luego divide cada libro en sus cinco a 15 temas más importantes, con una estimación de cuánto contribuye cada tema al libro en general.
Para comparar libros, los investigadores utilizan otras dos herramientas:incrustaciones de palabras, una técnica que convierte palabras en listas de números para reflejar su similitud en el uso popular, y transporte óptimo, un marco para calcular la forma más eficiente de mover objetos (o puntos de datos) entre múltiples destinos.
Las incrustaciones de palabras permiten aprovechar el transporte óptimo dos veces:primero para comparar temas dentro de la colección en su conjunto, y luego, dentro de cualquier par de libros, para medir qué tan cerca se superponen los temas comunes.
La técnica funciona especialmente bien al escanear grandes colecciones de libros y documentos extensos. En el estudio, los investigadores ofrecen el ejemplo de "The Great War Syndicate, de Frank Stockton, "una novela estadounidense del siglo XIX que anticipó el auge de las armas nucleares. Si está buscando un libro similar, un modelo de tema ayudaría a identificar los temas dominantes compartidos con otros libros; en este caso, náutico, elemental, y marcial.
Pero un modelo temático por sí solo no identificaría la conferencia de 1863 de Thomas Huxley, "La condición pasada de la naturaleza orgánica, "como una buena combinación. El escritor fue un defensor de la teoría de la evolución de Charles Darwin, y su conferencia, salpicado de menciones de fósiles y sedimentación, reflejó ideas emergentes sobre geología. Cuando los temas de la conferencia de Huxley se combinan con la novela de Stockton a través de un transporte óptimo, surgen algunos motivos transversales:la geografía de Huxley, flora fauna, y los temas de conocimiento se relacionan estrechamente con la náutica de Stockton, elemental, y temas marciales, respectivamente.
Modelar libros por sus temas representativos, en lugar de palabras individuales, hace posible las comparaciones de alto nivel. "Si le pides a alguien que compare dos libros, dividen cada uno en conceptos fáciles de entender, y luego comparar los conceptos, "dice el autor principal del estudio, Mikhail Yurochkin, investigador de IBM.
El resultado es más rápido, comparaciones más precisas, el estudio muestra. Los investigadores compararon 1, 720 pares de libros en el conjunto de datos del Proyecto Gutenberg en un segundo, más de 800 veces más rápido que el siguiente mejor método.
La técnica también hace un mejor trabajo al clasificar documentos con precisión que los métodos rivales, por ejemplo, agrupar libros en el conjunto de datos de Gutenberg por autor, reseñas de productos en Amazon por departamento, e historias de deportes de la BBC por deporte. En una serie de visualizaciones, los autores muestran que su método agrupa cuidadosamente los documentos por tipo.
Además de clasificar los documentos de forma rápida y precisa, el método ofrece una ventana al proceso de toma de decisiones del modelo. A través de la lista de temas que aparecen, los usuarios pueden ver por qué el modelo recomienda un documento.
Esta historia se vuelve a publicar por cortesía de MIT News (web.mit.edu/newsoffice/), un sitio popular que cubre noticias sobre la investigación del MIT, innovación y docencia.