Crédito:CC0 Public Domain
El 3 de noviembre En 2020, y durante muchos días después, millones de personas mantuvieron una mirada cautelosa sobre los modelos de predicción de elecciones presidenciales administrados por varios medios de comunicación. Con apuestas tan altas en juego, cada tic de un recuento y cada contracción de un gráfico podría enviar ondas de choque de sobreinterpretación.
Un problema con los recuentos brutos de las elecciones presidenciales es que crean una narrativa falsa de que los resultados finales aún se están desarrollando de manera drástica. En realidad, en la noche de las elecciones no hay "ponerse al día desde atrás" o "perder el liderazgo" porque los votos ya están emitidos; el ganador ya ha ganado, pero todavía no lo sabemos. Más que ser simplemente impreciso, estas fascinantes descripciones del proceso de votación pueden hacer que los resultados parezcan excesivamente sospechosos o sorprendentes.
"Los modelos predictivos se utilizan para tomar decisiones que pueden tener enormes consecuencias para la vida de las personas, "dijo Emmanuel Candès, la Cátedra Barnum-Simons de Matemáticas y Estadística en la Facultad de Humanidades y Ciencias de la Universidad de Stanford. "Es extremadamente importante comprender la incertidumbre sobre estas predicciones, para que la gente no tome decisiones basadas en creencias falsas ".
Tal incertidumbre era exactamente lo que El Washington Post El científico de datos Lenny Bronner tenía como objetivo destacar en un nuevo modelo de predicción que comenzó a desarrollar para las elecciones locales de Virginia en 2019 y perfeccionó aún más para las elecciones presidenciales, con la ayuda de John Cherian, un Ph.D. actual estudiante de estadística en Stanford a quien Bronner conocía de sus estudios de pregrado.
"El modelo realmente se trataba de agregar contexto a los resultados que se mostraban, "dijo Bronner." No se trataba de predecir la elección. Se trataba de decirles a los lectores que los resultados que estaban viendo no reflejaban dónde pensábamos que terminarían las elecciones ".
Este modelo es la primera aplicación en el mundo real de una técnica estadística existente desarrollada en Stanford por Candès, el ex becario postdoctoral Yaniv Romano y el ex estudiante de posgrado Evan Patterson. La técnica es aplicable a una variedad de problemas y, como en el modelo de predicación del Post, podría ayudar a elevar la importancia de la incertidumbre honesta en los pronósticos. Si bien el Post continúa afinando su modelo para futuras elecciones, Candès está aplicando la técnica subyacente en otros lugares, incluidos los datos sobre COVID-19.
Evitando suposiciones
Para crear esta técnica estadística, Candès, Romano y Evan Patterson combinaron dos áreas de investigación (regresión cuantílica y predicción conforme) para crear lo que Candès llamó "el más informativo, rango bien calibrado de valores predichos que sé cómo construir ".
Si bien la mayoría de los modelos de predicción intentan pronosticar un solo valor, a menudo la media (promedio) de un conjunto de datos, La regresión cuantílica estima una variedad de resultados plausibles. Por ejemplo, una persona puede querer encontrar el cuantil 90, que es el umbral por debajo del cual se espera que el valor observado caiga el 90 por ciento del tiempo. Cuando se agrega a la regresión de cuantiles, La predicción conforme, desarrollada por el científico informático Vladimir Vovk, calibra los cuantiles estimados para que sean válidos fuera de una muestra. como para datos no vistos hasta ahora. Para el modelo electoral del Post, eso significaba usar los resultados de la votación de áreas demográficamente similares para ayudar a calibrar las predicciones sobre los votos que estaban pendientes.
Lo especial de esta técnica es que comienza con suposiciones mínimas integradas en las ecuaciones. Para que funcione, sin embargo, debe comenzar con una muestra representativa de datos. Eso es un problema para la noche de las elecciones porque los recuentos de votos iniciales, generalmente de comunidades pequeñas con más votaciones en persona, rara vez reflejan el resultado final.
Sin acceso a una muestra representativa de los votos actuales, Bronner y Cherian tuvieron que agregar una suposición. Calibraron su modelo utilizando los recuentos de votos de las elecciones presidenciales de 2016 para que cuando un área informara el 100 por ciento de sus votos, El modelo del Post supondría que cualquier cambio entre los votos de esa área en 2020 y sus votos en 2016 se reflejaría igualmente en condados similares. (El modelo luego se ajustaría aún más, reduciendo la influencia del supuesto, ya que más áreas informaron el 100 por ciento de sus votos). Para verificar la validez de este método, probaron el modelo con cada elección presidencial, a partir de 1992, y descubrió que sus predicciones coincidían estrechamente con los resultados del mundo real.
"Lo bueno de usar el enfoque de Emmanuel para esto es que las barras de error alrededor de nuestras predicciones son mucho más realistas y podemos mantener suposiciones mínimas, "dijo Cherian.
Visualizando la incertidumbre
En acción, La visualización del modelo en vivo del Post se diseñó minuciosamente para mostrar de manera destacada esas barras de error y la incertidumbre que representaban. El Post ejecutó el modelo para pronosticar el rango de resultados electorales probables en diferentes estados y tipos de condados; los condados se clasificaron según su demografía. En cada caso, cada nominado tenía su propia barra horizontal que se llenaba de color azul sólido para Joe Biden, rojo para Donald Trump:para mostrar los votos conocidos. Luego, el resto de la barra contenía un gradiente que representaba los resultados más probables para los votos pendientes, según el modelo. El área más oscura del gradiente fue el resultado más probable.
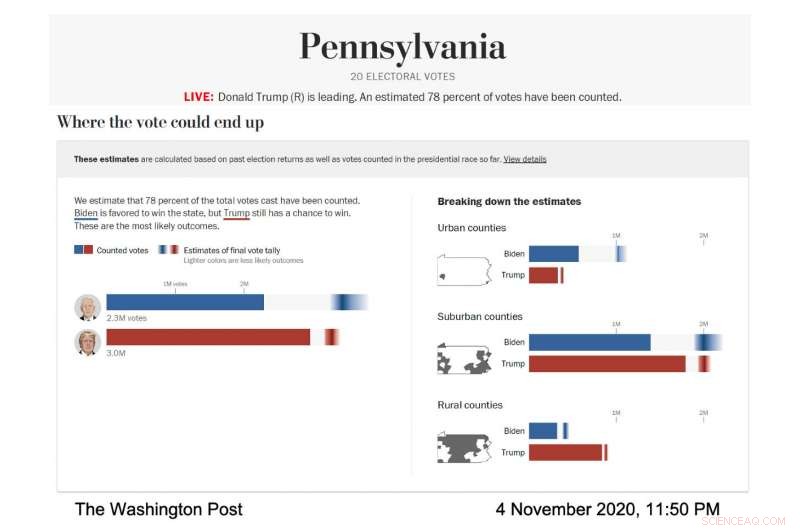
Captura de pantalla del modelo electoral de The Washington Post, mostrando la predicción de votación para Pensilvania el 4 de noviembre, 2020. (Crédito de la imagen:Cortesía de The Washington Post)
"Hablamos con los investigadores sobre la visualización de la incertidumbre y aprendimos que si le das a alguien una predicción promedio y luego le dices cuánta incertidumbre está involucrada, tienden a ignorar la incertidumbre, ", dijo Bronner." Así que hicimos una visualización que es muy 'incertidumbre hacia adelante ". Queríamos mostrar, esta es la incertidumbre y ni siquiera les vamos a decir cuál es nuestra predicción promedio ".
A medida que avanzaba la noche de las elecciones, la parte más oscura del gradiente de Biden en la visualización del voto total estaba más al lado derecho de la barra, lo que significaba que el modelo predijo que terminaría con más votos. Su gradiente también era más amplio y se extendía asimétricamente hacia el lado de votos más alto de la barra, lo que significaba que el modelo predijo que había muchos escenarios, con probabilidades decentes, donde obtendría más votos que el número más probable.
"En la noche de las elecciones, notamos que las barras de error eran muy cortas en el lado izquierdo de la barra de Biden y muy largas en el lado derecho, ", dijo Cherian. Esto se debió a que Biden tenía muchas ventajas para superar potencialmente nuestra proyección de una manera sustancial y no tenía muchas desventajas". Esta predicción asimétrica fue una consecuencia del enfoque de modelado particular utilizado por Cherian y Bronner . Debido a que los pronósticos del modelo se calibraron utilizando resultados de condados demográficamente similares que habían terminado de informar sus votos, quedó claro que Biden tenía una buena oportunidad de superar significativamente el voto demócrata de 2016 en los condados suburbanos, mientras que era extremadamente improbable que lo hiciera peor.
Por supuesto, mientras el recuento de votos se dirige hacia el final, los gradientes se redujeron y las predicciones inciertas del Post parecían cada vez más seguras, una situación estresante para los científicos de datos preocupados por exagerar conclusiones tan importantes.
"Estaba particularmente preocupado de que la carrera se redujera a un estado, y tendríamos una predicción en nuestra página para los días que al final no se hizo realidad, "dijo Bronner.
Y esa preocupación estaba bien fundada porque el modelo predijo fuerte y obstinadamente una victoria de Biden durante varios días, ya que los recuentos finales de votos no llegaron de un solo estado. pero tres:Wisconsin, Michigan y Pensilvania.
"Terminó ganando esos estados, so that ended up working well for the model, " added Bronner. "But at the time it was very, very stressful."
Following their commitment to transparency, Bronner and Cherian also made the code to their election model public, so people can run it themselves. They've also published technical reports on their methods (available for download here). The model will run again during Virginia state elections this year and the midterm elections in 2022.
"We wanted to make everything public. We want this to be a conversation with people who care about elections and people who care about data, " said Bronner.
Forcing honesty
The bigger picture for Candès is how honest and transparent statistical work can contribute to more reasonable and ethical outcomes in the real world. Statistics, después de todo, are foundational to artificial intelligence and algorithms, which are pervasive in our everyday lives. They orchestrate our search results, social media experience and streaming suggestions while also being used in decision-making tools in medical care, university admissions, the justice system and banking. The power—and perceived omnipotence—of algorithms troubles Candès.
Models like the one the Post used can address some of these concerns. By starting with fewer assumptions, the model provides a more honest—and harder to overlook—assessment of the uncertainty surrounding its predictions. And similar models could be developed for a wide variety of prediction problems. De hecho, Candès is currently working on a model, built on the same statistical technique as the Post's election model, to infer survival times after contracting COVID-19 on the basis of relevant factors such as age, sex and comorbidities.
The catch to an honest, assumption-free statistical model, sin embargo, is that the conclusions suffer if there isn't enough data. Por ejemplo, predictions about the consequences of different medical care decisions for women would have much wider error bars than predictions regarding men because we know far less about women, medically, than men.
This catch is a feature, aunque, not a bug. The uncertainty is glaringly obvious and so is the fix:We need more and better data before we start using it to inform important decisions.
"As statisticians, we want to inform decisions, but we're not decision makers, " Candès said. "So I like the way this model communicates the results of data analysis to decision makers because it's extremely honest reporting and avoids positioning the algorithm as the decision maker."