Un mapa del mundo que muestra puntos de datos, para los cuales los investigadores planean recopilar datos unificados (por ejemplo, datos que sean directamente comparables) utilizando las directrices dadas en el documento. Crédito:OpenStreetMap. Forkel y col. 2018. Formatos de datos interlingüísticos, promover el intercambio y la reutilización de datos en la lingüística comparada. Datos científicos .
Un equipo internacional de investigadores, miembros de la Iniciativa de Formatos de Datos Interlingüísticos (CLDF) dirigida por el Instituto Max Planck para la Ciencia de la Historia Humana, ha propuesto nuevas directrices sobre formatos de datos translingüísticos para facilitar el intercambio y la comparación de datos entre el creciente número de grandes bases de datos lingüísticas en todo el mundo. Este formato proporciona un paquete de software, una ontología básica y ejemplos de uso.
Existe un número creciente de bases de datos lingüísticas en todo el mundo, planteando la posibilidad de una amplia red para posibles estudios comparativos. Sin embargo, estas bases de datos se crean generalmente de forma independiente entre sí, ya menudo tienen un enfoque único y limitado. Esto significa que los formatos utilizados para codificar los datos suelen ser diferentes, creando dificultades para comparar datos entre bases de datos.
La Iniciativa de formatos de datos interlingüísticos (CLDF) es un esfuerzo para resolver estos problemas. En un artículo publicado en Datos científicos , el CLDF establece las directrices propuestas para un formato estandarizado para bases de datos lingüísticas, y también proporciona un paquete de software, una ontología básica y ejemplos de uso de las mejores prácticas. El objetivo de este esfuerzo es facilitar el intercambio y la reutilización de datos en lingüística comparada.
El CLDF proporciona un modelo de datos subyacente a sus recomendaciones que pretende ser simple, pero expresivo, y se basa en el modelo de datos desarrollado previamente para el proyecto Cross-Linguistic Data. Este modelo tiene cuatro entidades principales:(a) idiomas; (b) parámetros; (c) valores; y (d) fuentes. En el modelo, cada valor está relacionado con un parámetro y un idioma, y puede basarse en múltiples fuentes. Además, hay referencias de fuentes, y las referencias también pueden tener contextos (que, por ejemplo, para las referencias impresas serían los números de página).
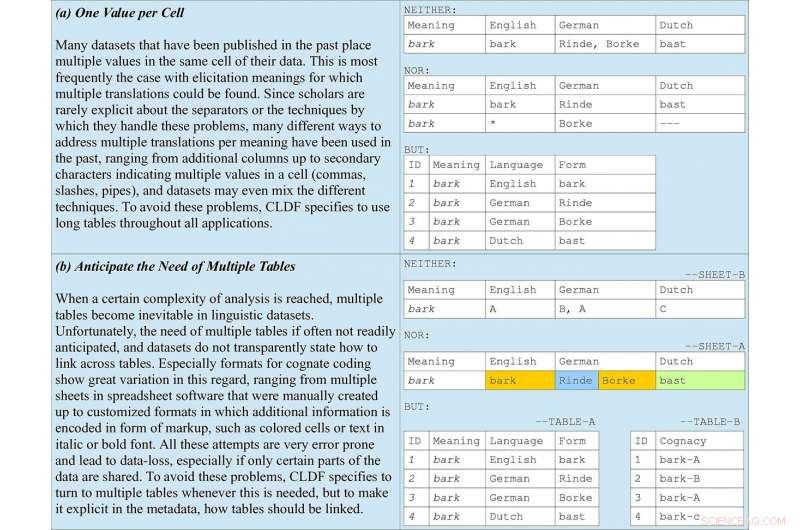
Reglas básicas de codificación de datos incluidas en las directrices, tomando como ejemplo la codificación análoga en listas de palabras. (a) ilustra por qué deberían favorecerse las tablas largas en todas las aplicaciones. (b) subraya la importancia de anticipar múltiples tablas junto con metadatos que indiquen cómo deben vincularse. Crédito:Forkel et al. 2018. Formatos de datos interlingüísticos, promover el intercambio y la reutilización de datos en la lingüística comparada. Datos científicos .
El modelo de datos CLDF es un formato de paquete en el que un conjunto de datos estaría formado por un conjunto de archivos de datos que contienen tablas, y un archivo descriptivo que define las relaciones entre las tablas. Cada tipo de datos lingüísticos tendría un módulo CLDF y componentes adicionales, cuáles serían los aspectos de los datos del módulo que se repiten en varios tipos de datos. Los módulos CLDF también contendrían términos de la ontología CLDF. La ontología es una lista de vocabulario que representa objetos y propiedades con semántica bien conocida en lingüística comparada. Esto hace posible que los usuarios hagan referencia a estos términos de manera uniforme.
Un paquete de software para permitir la validación y la manipulación.
Las especificaciones CLDF utilizan formatos de archivo comunes, como CSV, JSON y BibTeX, que son ampliamente compatibles, con el objetivo de que estos archivos se puedan leer y escribir fácilmente en muchas plataformas. Aún más importante, el formato estandarizado permitirá a los investigadores sin conocimientos de programación acceder y manipular los datos con herramientas preexistentes, para evitar restringir el paquete solo a investigadores con suficientes habilidades de programación para crear sus propias herramientas. Para facilitar esto, CLDF ha creado un repositorio de "libros de recetas" para scripts que se utilizarán con las especificaciones de CLDF.
"Queremos brindar acceso a estos datos y la capacidad de compararlos con tantos investigadores como sea posible, "dice Johann-Mattis List del Instituto Max Planck para la Ciencia de la Historia Humana. Robert Forkel, uno de los motores de la iniciativa CLDF, también señala que el formato CLDF no se limita solo a los datos lingüísticos, pero también puede incorporar bases de datos de datos culturales y geográficos, por ejemplo. "CLDF puede facilitar drásticamente la prueba de preguntas sobre la interacción entre lingüística, cultural, y factores ambientales en la evolución lingüística y cultural ".














