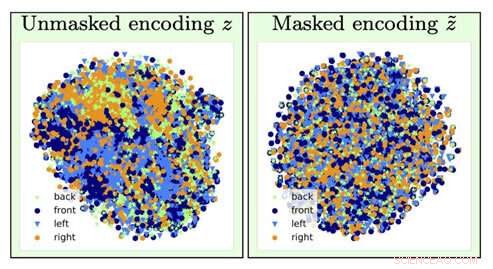
Para identificar el tipo de imagen de una silla, la información sobre la orientación de la silla (un factor de molestia) se pierde por la operación de olvido (pasando de la visualización izquierda a la derecha). Crédito:Universidad del Sur de California
Imagínese si la próxima vez que solicite un préstamo, un algoritmo informático determina que debe pagar una tarifa más alta en función principalmente de su raza, género o código postal.
Ahora, Imagine que fuera posible entrenar un modelo de aprendizaje profundo de IA para analizar esos datos subyacentes al inducir amnesia:olvida ciertos datos y solo se enfoca en otros.
Si estás pensando que esto suena a la versión de los informáticos de "El eterno resplandor de una mente impecable, "estarías bastante acertado. Y gracias a los investigadores de inteligencia artificial del Instituto de Ciencias de la Información (ISI) de la USC, este concepto, llamado olvido adversario, es ahora un mecanismo real.
La importancia de abordar y eliminar los sesgos en la IA es cada vez más importante a medida que la IA se vuelve cada vez más frecuente en nuestra vida diaria. señaló Ayush Jaiswal, autor principal del artículo y Ph.D. Candidato en la Escuela de Ingeniería de la USC Viterbi.
"AI y, más específicamente, Los modelos de aprendizaje automático heredan los sesgos presentes en los datos en los que están entrenados y son propensos a amplificar esos sesgos. ", explicó." La inteligencia artificial se está utilizando para tomar varias decisiones de la vida real que nos afectan a todos, [como] determinar los límites de crédito, aprobar préstamos, puntuación de solicitudes de empleo, etc. Si, por ejemplo, los modelos para tomar estas decisiones se entrenan ciegamente en datos históricos sin controlar los sesgos, aprenderían a tratar injustamente a las personas que pertenecen a sectores históricamente desfavorecidos de la población, como mujeres y personas de color ".
La investigación fue dirigida por Wael AbdAlmageed, líder del equipo de investigación en ISI y profesor asociado de investigación en el Departamento de Ingeniería Eléctrica e Informática Ming Hsieh de USC Viterbi, y el profesor asociado de investigación Greg Ver Steeg, así como Premkumar Natarajan, profesor investigador de informática y director ejecutivo de ISI (en excedencia). Bajo su dirección, Jaiswal y el coautor Daniel Moyer, Doctor., desarrolló el enfoque de olvido adversario, que enseña a los modelos de aprendizaje profundo a ignorar factores de datos no deseados para que los resultados que produzcan sean imparciales y más precisos.
El trabajo de investigación, titulado "Representaciones invariables a través del olvido adversario, "se presentó en la conferencia de la Asociación para el Avance de la Inteligencia Artificial en la ciudad de Nueva York el 10 de febrero, 2020.
Molestias y redes neuronales
El aprendizaje profundo es un componente central en la IA y puede enseñar a las computadoras cómo encontrar correlaciones y hacer predicciones con datos. ayudar a identificar personas u objetos, por ejemplo. Los modelos esencialmente buscan asociaciones entre diferentes características dentro de los datos y el objetivo que se supone que predice. Si a un modelo se le asignó la tarea de encontrar a una persona específica de un grupo, analizaría los rasgos faciales para diferenciar a todos y luego identificar a la persona objetivo. Sencillo, ¿Derecha?
Desafortunadamente, las cosas no siempre funcionan tan bien, ya que el modelo puede terminar aprendiendo cosas que pueden parecer contradictorias. Podría asociar su identidad con un fondo particular o una configuración de iluminación y no podrá identificarlo si la iluminación o el fondo fueron alterados; podría asociar tu letra a una determinada palabra, y confundirse si la misma palabra está escrita con la letra de otra persona. Estos factores molestos con un nombre adecuado no están relacionados con la tarea que está tratando de realizar, y asociarlos incorrectamente con el objetivo de predicción puede terminar siendo peligroso.
Los modelos también pueden conocer los sesgos en los datos que están correlacionados con el objetivo de la predicción, pero que no son deseados. Por ejemplo, en tareas realizadas por modelos que involucran datos socioeconómicos recopilados históricamente, como determinar puntajes de crédito, líneas de créditos, y elegibilidad para préstamos, el modelo puede hacer predicciones falsas y mostrar sesgos al establecer conexiones entre los sesgos y el objetivo de la predicción. Puede llegar a la conclusión de que, dado que analiza los datos de una mujer, debe tener un puntaje crediticio bajo; ya que analiza los datos de una persona de color, no deben ser elegibles para un préstamo. No faltan historias de bancos que están siendo criticados por las decisiones sesgadas de sus algoritmos sobre cuánto cobran a las personas que han obtenido préstamos en función de su raza. género, y educación, incluso si tienen exactamente el mismo perfil crediticio que alguien en un segmento de población socialmente más privilegiado.
Como explicó Jaiswal, el mecanismo de olvido adversario "arregla" las redes neuronales, que son potentes modelos de aprendizaje profundo que aprenden a predecir objetivos a partir de datos. ¿El límite de crédito que obtuvo en esa nueva tarjeta de crédito en la que se registró? Una red neuronal probablemente analizó sus datos financieros para llegar a ese número.
El equipo de investigación desarrolló el mecanismo de olvido adversario para que primero pudiera entrenar a la red neuronal para representar todos los aspectos subyacentes de los datos que está analizando y luego olvidar sesgos específicos. En el ejemplo del límite de la tarjeta de crédito, eso significaría que el mecanismo podría enseñar al algoritmo del banco a predecir el límite mientras se olvida, o siendo invariante a, los datos particulares relacionados con el género o la raza. "[El mecanismo] se puede utilizar para entrenar redes neuronales para que sean invariantes a los sesgos conocidos en los conjuntos de datos de entrenamiento, "Dijo Jaiswal." Esto, Sucesivamente, daría como resultado modelos entrenados que no estarían sesgados al tomar decisiones ".
Los algoritmos de aprendizaje profundo son excelentes para aprender cosas, pero es más difícil asegurarse de que los algoritmos no aprendan ciertas cosas. El desarrollo de algoritmos es un proceso muy basado en datos, y los datos tienden a contener sesgos.
¿Pero no podemos simplemente sacar todos los datos sobre la raza, género, y educación para eliminar los prejuicios?
No completamente. Hay muchos otros factores de datos que están correlacionados con estos factores sensibles que son importantes para que los analicen los algoritmos. La clave, como descubrieron los investigadores de ISI AI, está agregando restricciones en el proceso de entrenamiento del modelo para forzar al modelo a hacer predicciones mientras es invariante a factores específicos de datos, esencialmente, olvido selectivo.
Lucha contra los prejuicios
La invariancia se refiere a la capacidad de identificar un objeto específico incluso si su apariencia (es decir, datos) se altera de alguna manera, y Jaiswal y sus colegas comenzaron a pensar en cómo se podría aplicar este concepto para mejorar los algoritmos. "Mi coautor, Dan [Moyer], y de hecho se me ocurrió esta idea de forma algo natural basada en nuestras experiencias previas en el campo del aprendizaje de la representación invariante, ", comentó. Pero desarrollar el concepto no fue una tarea sencilla." Las partes más desafiantes fueron [la] comparación rigurosa con trabajos anteriores en este dominio en una amplia gama de conjuntos de datos (que requirieron ejecutar una gran cantidad de experimentos) y [ desarrollando] un análisis teórico del proceso de olvido, " él dijo.
El mecanismo de olvido adversario también se puede utilizar para ayudar a mejorar la generación de contenido en una variedad de campos. "El campo incipiente del aprendizaje automático justo busca formas de reducir el sesgo en la toma de decisiones algorítmicas basadas en datos del consumidor, ", dijo Ver Steeg." Un área más especulativa implica la investigación sobre el uso de la IA para generar contenido, incluidos los intentos de libros, música, Arte, juegos, e incluso recetas. Para que la generación de contenido tenga éxito, necesitamos nuevas formas de controlar y manipular las representaciones de redes neuronales y el mecanismo de olvido podría ser una forma de hacerlo ".
Entonces, ¿cómo se manifiestan los sesgos en el modelo en primer lugar?
La mayoría de los modelos utilizan datos históricos, cuales, Desafortunadamente, puede estar en gran medida sesgado hacia comunidades tradicionalmente marginadas como las mujeres, minorías, incluso ciertos códigos postales. Es costoso y engorroso recopilar datos, por lo que los científicos tienden a recurrir a datos que ya existen y a entrenar modelos basados en ellos, que es como los sesgos entran en escena.
La buena noticia es que se están reconociendo estos sesgos, y si bien el problema está lejos de resolverse, Se están logrando avances para comprender y abordar estos problemas. " n la comunidad investigadora, las personas definitivamente se están volviendo cada vez más conscientes de los sesgos de los conjuntos de datos, y diseñar y analizar protocolos de recolección para controlar los sesgos conocidos, ", dijo Jaiswal." El estudio de los sesgos y la equidad en el aprendizaje automático ha crecido rápidamente como campo de investigación en los últimos años ".
La determinación de qué factores deben considerarse irrelevantes o sesgados la realizan expertos en el campo y se basan en análisis estadísticos. "Hasta aquí, la invariancia se ha utilizado principalmente para eliminar factores que se consideran ampliamente no deseados / irrelevantes dentro de la comunidad de investigación según la evidencia estadística, "Dijo Jaiswal.
Sin embargo, dado que los investigadores determinan lo que es irrelevante o sesgado, puede existir la posibilidad de que esas determinaciones se conviertan en sesgos en sí mismas. Este es un factor en el que también están trabajando los investigadores. "Averiguar qué factores olvidar es un problema crítico que puede llevar fácilmente a consecuencias no deseadas, ", señaló Ver Steeg." Un artículo reciente de Nature sobre el aprendizaje justo señala que tenemos que comprender los mecanismos detrás de la discriminación si esperamos especificar correctamente las soluciones algorítmicas ".
El procesamiento de información humana es extremadamente complejo, y el mecanismo de olvido adversario nos ayuda a acercarnos un paso más al desarrollo de una IA que pueda pensar como nosotros. Como comentó Ver Steeg, los seres humanos tienden a separar diferentes formas de información sobre el mundo que los rodea mediante algoritmos instintivos para hacer lo mismo, es el desafío que tenemos por delante.
"Si alguien se para delante de tu coche, golpeas los descansos y el eslogan de su camisa ni siquiera entra en tu mente, ", dijo Ver Steeg." Pero si conociste a esa persona en un contexto social, esa información puede ser relevante y ayudarlo a entablar una conversación. Para la IA, diferentes tipos de información se mezclan. Si podemos enseñar a las redes neuronales a separar conceptos que son útiles para diferentes tareas, esperamos que lleve a la IA a una comprensión más humana del mundo ".
El procesamiento de información humana es extremadamente complejo, y el mecanismo de olvido adversario nos ayuda a acercarnos un paso más al desarrollo de una IA que pueda pensar como nosotros. Como comentó Ver Steeg, los seres humanos tienden a separar diferentes formas de información sobre el mundo que los rodea por instinto; conseguir que los algoritmos hagan lo mismo es el desafío que tenemos por delante.
"Si alguien se para delante de tu coche, golpeas los descansos y el eslogan de su camisa ni siquiera entra en tu mente, ", dijo Ver Steeg." Pero si conociste a esa persona en un contexto social, esa información puede ser relevante y ayudarlo a entablar una conversación. Para la IA, diferentes tipos de información se mezclan. Si podemos enseñar a las redes neuronales a separar conceptos que son útiles para diferentes tareas, esperamos que lleve a la IA a una comprensión más humana del mundo ".