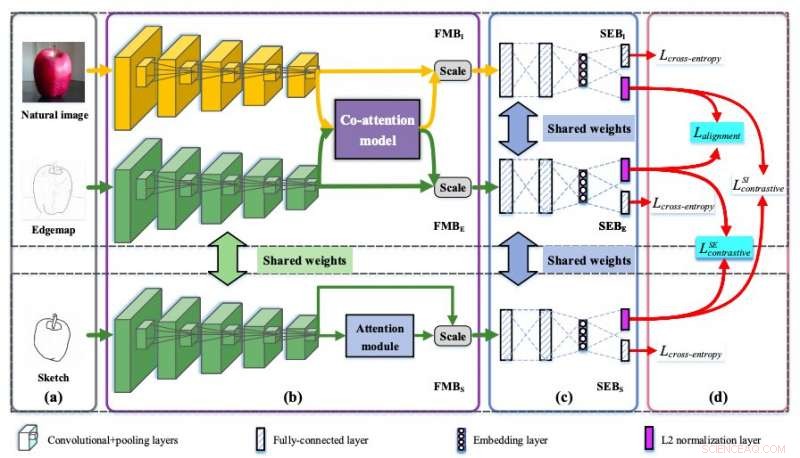
Ilustración de la arquitectura Semi3-Net. Crédito:Lei et al.
En años recientes, Los investigadores han estado desarrollando técnicas computacionales cada vez más avanzadas, como los algoritmos de aprendizaje profundo, para completar una variedad de tareas. Una tarea que han estado tratando de abordar se conoce como "recuperación de imágenes basada en bocetos" (SBIR).
Las tareas de SBIR implican recuperar imágenes de un objeto particular o concepto visual entre una amplia colección o base de datos basada en bocetos hechos por usuarios humanos. Para automatizar esta tarea, Los investigadores han estado tratando de desarrollar herramientas que puedan analizar bocetos humanos e identificar imágenes relacionadas con el boceto o que contengan el mismo objeto.
A pesar de los resultados prometedores logrados con algunas de estas herramientas, El desarrollo de técnicas que funcionen consistentemente bien en las tareas SBIR ha demostrado ser un desafío hasta ahora. Esto se debe principalmente a las marcadas diferencias visuales entre los bocetos abstractos y las imágenes reales. Por ejemplo, los bocetos hechos por humanos a menudo son deformados y abstractos, lo que hace que sea más difícil relacionarlos con objetos en imágenes reales.
Para superar este desafío, Investigadores de la Universidad de Tianjin y la Universidad de Correos y Telecomunicaciones de Beijing en China han desarrollado recientemente una arquitectura basada en redes neuronales que aprende representaciones discriminatorias de características entre dominios para tareas de recuperación de imágenes basadas en bocetos (SBIR). La técnica que crearon, presentado en un artículo publicado previamente en arXiv, combina una variedad de técnicas computacionales, incluido el mapeo de características semi-heterogéneas, modelos conjuntos de inserción semántica y co-atención.
"La idea clave radica en cómo cultivamos las relaciones mutuas y sutiles entre los bocetos, imágenes naturales y mapas de bordes, "escribieron los investigadores en su artículo." El mapeo de características semi-heterogéneas está diseñado para extraer características inferiores de cada dominio, donde las ramas del boceto y el mapa de bordes se comparten mientras que la rama de la imagen natural es heterogénea con respecto a otras ramas ".
El modelo diseñado por los investigadores es una red de inserción conjunta de tres vías semi-heterogénea (Semi3-Net). Además del mapeo semi-heterogéneo, utiliza una técnica conocida como incrustación semántica conjunta. La incrustación semántica permite a la red incrustar características de diferentes dominios (p. Ej., desde bocetos o fotografías) en un espacio semántico común de alto nivel. Semi3-Net también incorpora un modelo de co-atención, que está diseñado para recalibrar características extraídas de los dos dominios diferentes.
Finalmente, los investigadores diseñaron un mecanismo de pérdida híbrida que puede calcular la correlación entre bocetos, mapas de bordes e imágenes naturales. Este mecanismo permite que el modelo Semi3-Net aprenda representaciones que son invariantes en los dos dominios (es decir, bocetos e imágenes tomadas con cámaras).
Los investigadores capacitaron y evaluaron a Semi3-Net con datos de Sketchy y TU-Berlin Extension, dos conjuntos de datos que se utilizan ampliamente en estudios que se centran en tareas SBIR. La base de datos de Sketchy contiene 75, 471 bocetos y 12, 500 imágenes naturales, mientras que TU-Berlin Extension contiene 204, 489 imágenes naturales y 20, 000 bocetos dibujados a mano.
Hasta aquí, Semi3-Net se ha desempeñado notablemente bien en todos los experimentos realizados por los investigadores, superando a otros modelos de vanguardia para SBIR. El equipo ahora planea continuar trabajando en el modelo y mejorar aún más su rendimiento. quizás incluso adaptándolo para abordar otros problemas que requieran conectar datos de diferentes dominios.
"En el futuro, nos centraremos en extender la red de dominio cruzado propuesta para la recuperación de imágenes de grano fino y aprender la correspondencia de los detalles de grano fino para pares de imágenes de boceto, "escribieron los investigadores en su artículo.
© 2019 Science X Network