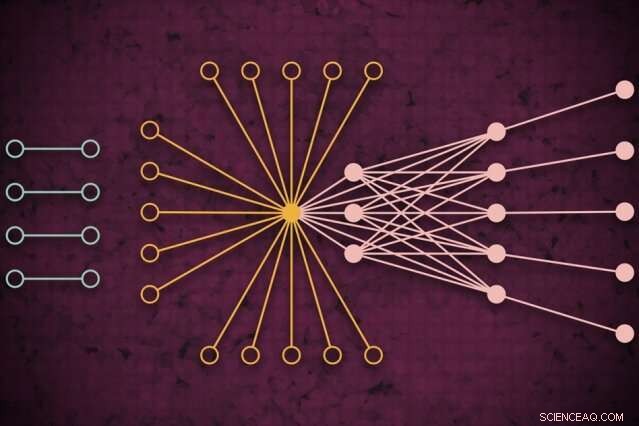
Usando un sistema de supercomputación, Los investigadores del MIT desarrollaron un modelo que captura cómo podría verse el tráfico web global en un día determinado, incluidos los enlaces aislados nunca antes vistos (izquierda) que rara vez se conectan pero parecen afectar el tráfico web principal (derecha). Crédito:MIT News
Usando un sistema de supercomputación, Los investigadores del MIT han desarrollado un modelo que captura cómo se ve el tráfico web en todo el mundo en un día determinado, que se puede utilizar como herramienta de medición para la investigación en Internet y muchas otras aplicaciones.
Comprender los patrones de tráfico web a una escala tan grande, los investigadores dicen, es útil para informar la política de Internet, identificar y prevenir cortes, defenderse de los ciberataques, y diseñar una infraestructura informática más eficiente. En la reciente Conferencia de Computación Extrema de Alto Rendimiento del IEEE se presentó un documento que describe el enfoque.
Por su trabajo, los investigadores recopilaron el mayor conjunto de datos de tráfico de Internet disponible al público, que comprende 50 mil millones de paquetes de datos intercambiados en diferentes lugares en todo el mundo durante un período de varios años.
Ejecutaron los datos a través de una nueva canalización de "redes neuronales" que opera en 10, 000 procesadores del MIT SuperCloud, un sistema que combina recursos informáticos del Laboratorio Lincoln del MIT y de todo el Instituto. Esa canalización entrenó automáticamente un modelo que captura la relación de todos los enlaces en el conjunto de datos, desde pings comunes hasta gigantes como Google y Facebook, a enlaces raros que solo se conectan brevemente pero que parecen tener algún impacto en el tráfico web.
El modelo puede tomar cualquier conjunto de datos de red masivo y generar algunas medidas estadísticas sobre cómo todas las conexiones en la red se afectan entre sí. Eso se puede utilizar para revelar información sobre el intercambio de archivos de igual a igual, direcciones IP nefastas y comportamiento de spam, la distribución de ataques en sectores críticos, y cuellos de botella de tráfico para asignar mejor los recursos informáticos y mantener el flujo de datos.
En concepto, el trabajo es similar a medir el fondo cósmico de microondas del espacio, las ondas de radio casi uniformes que viajan por nuestro universo y que han sido una fuente importante de información para estudiar los fenómenos en el espacio exterior. "Creamos un modelo preciso para medir el fondo del universo virtual de Internet, "dice Jeremy Kepner, investigador del Centro de Supercomputación del Laboratorio Lincoln del MIT y astrónomo de formación. "Si desea detectar alguna variación o anomalía, tienes que tener un buen modelo del fondo ".
Junto a Kepner en el papel están:Kenjiro Cho de la Iniciativa de Internet de Japón; KC Claffy del Centro de Análisis de Datos de Internet Aplicados de la Universidad de California en San Diego; Vijay Gadepally y Peter Michaleas del Centro de Supercomputación del Laboratorio Lincoln; y Lauren Milechin, investigador del Departamento de Tierra del MIT, Ciencias Atmosféricas y Planetarias.
Rompiendo datos
En la investigación de Internet, los expertos estudian anomalías en el tráfico web que pueden indicar, por ejemplo, amenazas cibernéticas. Para hacerlo ayuda a comprender primero cómo es el tráfico normal. Pero capturar eso ha seguido siendo un desafío. Los modelos tradicionales de "análisis de tráfico" solo pueden analizar pequeñas muestras de paquetes de datos intercambiados entre fuentes y destinos limitados por ubicación. Eso reduce la precisión del modelo.
Los investigadores no buscaban específicamente abordar este problema de análisis de tráfico. Pero habían estado desarrollando nuevas técnicas que podrían usarse en MIT SuperCloud para procesar matrices de red masivas. El tráfico de Internet fue el caso de prueba perfecto.
Las redes generalmente se estudian en forma de gráficos, con actores representados por nodos, y enlaces que representan conexiones entre los nodos. Con tráfico de Internet, los nodos varían en tamaño y ubicación. Los grandes supernodos son centros populares, como Google o Facebook. Los nodos hoja se extienden desde ese supernodo y tienen múltiples conexiones entre sí y con el supernodo. Fuera de ese "núcleo" de supernodos y nodos hoja hay nodos y enlaces aislados, que se conectan entre sí solo en raras ocasiones.
La captura de la extensión completa de esos gráficos no es factible para los modelos tradicionales. "No puedes tocar esos datos sin acceso a una supercomputadora, "Dice Kepner.
En asociación con el proyecto Widely Integrated Distributed Environment (WIDE), fundada por varias universidades japonesas, y el Centro de Análisis Aplicado de Datos de Internet (CAIDA), en California, Los investigadores del MIT capturaron el conjunto de datos de captura de paquetes más grande del mundo para el tráfico de Internet. El conjunto de datos anónimos contiene casi 50 mil millones de puntos de datos de origen y destino únicos entre los consumidores y varias aplicaciones y servicios durante días aleatorios en varias ubicaciones de Japón y los EE. UU. que se remonta a 2015.
Antes de que pudieran entrenar cualquier modelo con esos datos, necesitaban hacer un preprocesamiento extenso. Para hacerlo utilizaron software que crearon previamente, llamado Modo de datos dimensionales distribuidos dinámicos (D4M), que utiliza algunas técnicas de promediado para calcular y clasificar de manera eficiente "datos hiperespasos" que contienen mucho más espacio vacío que puntos de datos. Los investigadores dividieron los datos en unidades de aproximadamente 100, 000 paquetes en 10, 000 procesadores MIT SuperCloud. Esto generó matrices más compactas de miles de millones de filas y columnas de interacciones entre fuentes y destinos.
Captura de valores atípicos
Pero la gran mayoría de las celdas de este conjunto de datos hiperespaso todavía estaban vacías. Para procesar las matrices, el equipo ejecutó una red neuronal en el mismo 10, 000 núcleos. Entre bastidores, una técnica de prueba y error comenzó a ajustar modelos a la totalidad de los datos, creando una distribución de probabilidad de modelos potencialmente precisos.
Luego, utilizó una técnica de corrección de errores modificada para refinar aún más los parámetros de cada modelo para capturar la mayor cantidad de datos posible. Tradicionalmente, Las técnicas de corrección de errores en el aprendizaje automático intentarán reducir la importancia de cualquier dato periférico para que el modelo se ajuste a una distribución de probabilidad normal. lo que lo hace más preciso en general. Pero los investigadores utilizaron algunos trucos matemáticos para asegurarse de que el modelo aún consideraba que todos los datos periféricos, como los enlaces aislados, eran importantes para las mediciones generales.
En el final, la red neuronal genera esencialmente un modelo simple, con solo dos parámetros, que describe el conjunto de datos de tráfico de Internet, "desde nodos muy populares hasta nodos aislados, y el espectro completo de todo lo que hay en el medio, "Dice Kepner.
Los investigadores ahora se están acercando a la comunidad científica para encontrar su próxima aplicación para el modelo. Expertos por ejemplo, podría examinar la importancia de los enlaces aislados que los investigadores encontraron en sus experimentos que son raros pero que parecen afectar el tráfico web en los nodos centrales.
Más allá de Internet la canalización de la red neuronal se puede utilizar para analizar cualquier red hiperespasa, como las redes biológicas y sociales. "Ahora le hemos dado a la comunidad científica una herramienta fantástica para las personas que desean construir redes más robustas o detectar anomalías en las redes, ", Dice Kepner." Esas anomalías pueden ser comportamientos normales de lo que hacen los usuarios, o podrían ser personas que hacen cosas que no quieres ".
Esta historia se vuelve a publicar por cortesía de MIT News (web.mit.edu/newsoffice/), un sitio popular que cubre noticias sobre la investigación del MIT, innovación y docencia.














