Un modelo de investigadores del MIT y Microsoft identifica instancias en las que los automóviles autónomos han "aprendido" de ejemplos de entrenamiento que no coinciden con lo que realmente está sucediendo en la carretera. que se puede utilizar para identificar qué acciones aprendidas podrían causar errores del mundo real. Crédito:MIT News
Un modelo novedoso desarrollado por investigadores del MIT y Microsoft identifica instancias en las que los sistemas autónomos han "aprendido" de ejemplos de entrenamiento que no coinciden con lo que realmente está sucediendo en el mundo real. Los ingenieros podrían utilizar este modelo para mejorar la seguridad de los sistemas de inteligencia artificial, como vehículos sin conductor y robots autónomos.
Los sistemas de inteligencia artificial que impulsan los automóviles sin conductor, por ejemplo, están entrenados extensamente en simulaciones virtuales para preparar el vehículo para casi todos los eventos en la carretera. Pero a veces el automóvil comete un error inesperado en el mundo real porque ocurre un evento que debería, pero no lo hace alterar el comportamiento del coche.
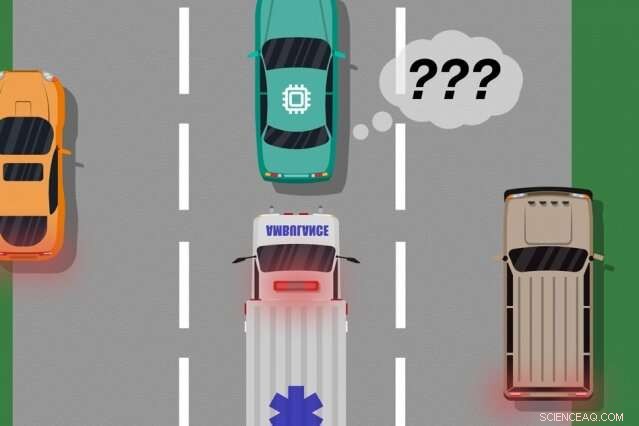
Considere un automóvil sin conductor que no fue entrenado, y lo que es más importante, no tiene los sensores necesarios, diferenciar entre escenarios claramente diferentes, como grande, carros blancos y ambulancias con rojo, luces intermitentes en la carretera. Si el automóvil circula por la carretera y una ambulancia enciende sus sirenas, es posible que el automóvil no sepa reducir la velocidad y detenerse, porque no percibe la ambulancia como diferente de un gran coche blanco.
En un par de artículos, presentados en la conferencia Autonomous Agents and Multiagent Systems del año pasado y la próxima conferencia Association for the Advancement of Artificial Intelligence, los investigadores describen un modelo que utiliza la participación humana para descubrir estos "puntos ciegos" de formación.
Al igual que con los enfoques tradicionales, los investigadores pusieron un sistema de IA a través de un entrenamiento de simulación. Pero entonces, un humano monitorea de cerca las acciones del sistema mientras actúa en el mundo real, proporcionar retroalimentación cuando el sistema hizo, o estuvo a punto de hacer, cualquier error. Luego, los investigadores combinan los datos de entrenamiento con los datos de retroalimentación humana, y utilizar técnicas de aprendizaje automático para producir un modelo que identifique situaciones en las que el sistema probablemente necesite más información sobre cómo actuar correctamente.
Los investigadores validaron su método utilizando videojuegos, con un humano simulado corrigiendo el camino aprendido de un personaje en pantalla. Pero el siguiente paso es incorporar el modelo con enfoques tradicionales de entrenamiento y prueba para autos autónomos y robots con retroalimentación humana.
"El modelo ayuda a los sistemas autónomos a conocer mejor lo que no saben, "dice el primer autor Ramya Ramakrishnan, estudiante de posgrado en el Laboratorio de Ciencias de la Computación e Inteligencia Artificial. "Muchas veces, cuando se implementan estos sistemas, sus simulaciones entrenadas no coinciden con la configuración del mundo real [y] podrían cometer errores, como tener accidentes. La idea es utilizar humanos para cerrar la brecha entre la simulación y el mundo real, de forma segura, para que podamos reducir algunos de esos errores ".
Los coautores de ambos artículos son:Julie Shah, profesor asociado en el Departamento de Aeronáutica y Astronáutica y director del Grupo de Robótica Interactiva de CSAIL; y Ece Kamar, Debadeepta Dey, y Eric Horvitz, todo de Microsoft Research. Besmira Nushi es coautora adicional del próximo artículo.
Recibir retroalimentación
Algunos métodos de entrenamiento tradicionales brindan retroalimentación humana durante las pruebas en el mundo real, pero solo para actualizar las acciones del sistema. Estos enfoques no identifican puntos ciegos, que podría ser útil para una ejecución más segura en el mundo real.
El enfoque de los investigadores primero somete un sistema de IA a un entrenamiento de simulación, donde producirá una "política" que esencialmente mapea cada situación a la mejor acción que puede tomar en las simulaciones. Luego, el sistema se implementará en el mundo real, donde los humanos proporcionan señales de error en regiones donde las acciones del sistema son inaceptables.
Los seres humanos pueden proporcionar datos de múltiples formas, como a través de "demostraciones" y "correcciones". En demostraciones, los actos humanos en el mundo real, mientras que el sistema observa y compara las acciones del ser humano con lo que hubiera hecho en esa situación. Para autos sin conductor, por ejemplo, un humano controlaría manualmente el automóvil mientras el sistema produce una señal si su comportamiento planificado se desvía del comportamiento del humano. Los emparejamientos y desajustes con las acciones del ser humano proporcionan indicaciones ruidosas de dónde el sistema podría estar actuando de manera aceptable o inaceptable.
Alternativamente, el humano puede proporcionar correcciones, con el humano monitoreando el sistema mientras actúa en el mundo real. Un humano podría sentarse en el asiento del conductor mientras el automóvil autónomo se conduce por su ruta planificada. Si las acciones del automóvil son correctas, el humano no hace nada. Si las acciones del automóvil son incorrectas, sin embargo, el humano puede tomar el volante, que envía una señal de que el sistema no estaba actuando de manera inaceptable en esa situación específica.
Una vez que se compilan los datos de retroalimentación del humano, el sistema tiene esencialmente una lista de situaciones y, para cada situación, múltiples etiquetas que dicen que sus acciones eran aceptables o inaceptables. Una sola situación puede recibir muchas señales diferentes, porque el sistema percibe muchas situaciones como idénticas. Por ejemplo, un automóvil autónomo puede haber navegado junto a un automóvil grande muchas veces sin reducir la velocidad ni detenerse. Pero, en una sola instancia, una ambulancia, que aparece exactamente igual para el sistema, cruceros por. El automóvil autónomo no se detiene y recibe una señal de retroalimentación de que el sistema tomó una acción inaceptable.
"En ese punto, el sistema ha recibido múltiples señales contradictorias de un humano:algunos con un gran automóvil al lado, y estaba bien y uno donde había una ambulancia en el mismo lugar exacto, pero eso no estuvo bien. El sistema toma nota de que hizo algo mal, pero no sabe porque ", Dice Ramakrishnan." Debido a que el agente está recibiendo todas estas señales contradictorias, el siguiente paso es recopilar la información para preguntar, '¿Qué posibilidades hay de que cometa un error en esta situación en la que recibí estas señales contradictorias?' "
Agregación inteligente
El objetivo final es que estas situaciones ambiguas se etiqueten como puntos ciegos. Pero eso va más allá de simplemente contar las acciones aceptables e inaceptables para cada situación. Si el sistema realizó las acciones correctas nueve de cada 10 veces en la situación de ambulancia, por ejemplo, un voto de mayoría simple etiquetaría esa situación como segura.
"Pero debido a que las acciones inaceptables son mucho más raras que las acciones aceptables, el sistema eventualmente aprenderá a predecir todas las situaciones como seguras, que puede ser extremadamente peligroso, ", Dice Ramakrishnan.
Con ese fin, los investigadores utilizaron el algoritmo Dawid-Skene, un método de aprendizaje automático que se usa comúnmente para el crowdsourcing para manejar el ruido de las etiquetas. El algoritmo toma como entrada una lista de situaciones, cada uno con un conjunto de etiquetas ruidosas de "aceptable" e "inaceptable". Luego, agrega todos los datos y usa algunos cálculos de probabilidad para identificar patrones en las etiquetas de puntos ciegos predichos y patrones para situaciones seguras pronosticadas. Usando esa información, genera una sola etiqueta agregada de "seguro" o "punto ciego" para cada situación junto con su nivel de confianza en esa etiqueta. Notablemente, el algoritmo puede aprender en una situación en la que puede tener, por ejemplo, realizado aceptablemente el 90 por ciento del tiempo, la situación es todavía lo suficientemente ambigua como para merecer un "punto ciego".
En el final, el algoritmo produce un tipo de "mapa de calor, "donde a cada situación del entrenamiento original del sistema se le asigna una probabilidad de baja a alta de ser un punto ciego para el sistema.
"Cuando el sistema se implementa en el mundo real, puede utilizar este modelo aprendido para actuar con más cautela e inteligencia. Si el modelo aprendido predice que un estado es un punto ciego con alta probabilidad, el sistema puede consultar a un humano sobre la acción aceptable, permitiendo una ejecución más segura, ", Dice Ramakrishnan.
Esta historia se vuelve a publicar por cortesía de MIT News (web.mit.edu/newsoffice/), un sitio popular que cubre noticias sobre la investigación del MIT, innovación y docencia.