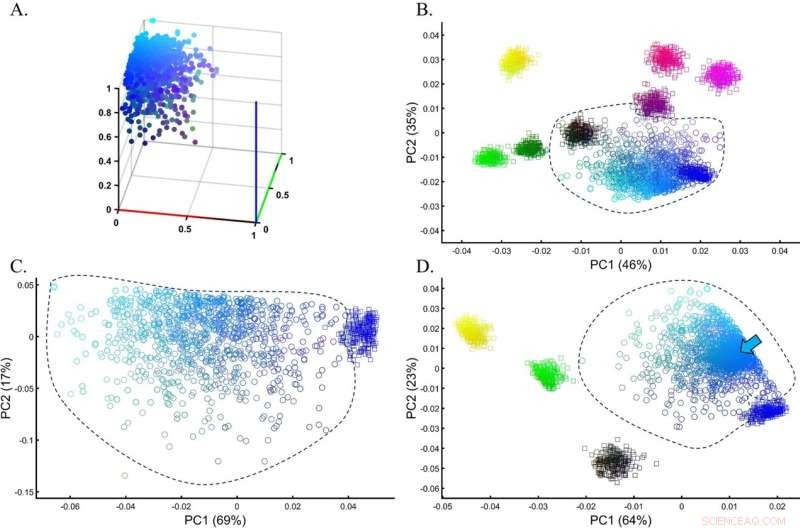
Evaluación de la precisión del agrupamiento de PCA para una población de prueba heterogénea en una simulación de una configuración de GWAS. (A) La verdadera distribución de la población de prueba Cyan (n = 1000). (B) PCA de la población de prueba con ocho muestras de tamaño uniforme (n = 250) de poblaciones de referencia. (C) PCA de la población de prueba con Blue del análisis anterior muestra una superposición mínima entre las cohortes. (D) PCA de la población de prueba con cinco muestras de tamaño uniforme (n = 250) de poblaciones de referencia, incluido el cian (marcado con una flecha). Los colores (B) de arriba a abajo y de izquierda a derecha incluyen:amarillo [1,1,0], rojo claro [1,0,0,5], morado [1,0,1], morado oscuro [0,5,0,0,5] ], negro [0,0,0], verde oscuro [0,0.5,0], verde [0,1,0] y azul [1,0,0]. Crédito:Informes científicos (2022). DOI:10.1038/s41598-022-14395-4
El método analítico más común dentro de la genética de poblaciones tiene fallas profundas, según un nuevo estudio de la Universidad de Lund en Suecia. Esto puede haber llevado a resultados incorrectos y conceptos erróneos sobre el origen étnico y las relaciones genéticas. El método se ha utilizado en cientos de miles de estudios, afectando los resultados dentro de la genética médica e incluso las pruebas comerciales de ascendencia. El estudio se publica en Scientific Reports .
La velocidad a la que se pueden recopilar datos científicos está aumentando exponencialmente, lo que lleva a conjuntos de datos masivos y altamente complejos, denominados la "revolución de Big Data". Para hacer que estos datos sean más manejables, los investigadores utilizan métodos estadísticos que tienen como objetivo compactar y simplificar los datos mientras conservan la mayor parte de la información clave. Quizás el método más utilizado se llama PCA (análisis de componentes principales). Por analogía, piense en PCA como un horno con harina, azúcar y huevos como entrada de datos. Es posible que el horno siempre haga lo mismo, pero el resultado, un pastel, depende en gran medida de las proporciones de los ingredientes y de cómo se combinen.
"Se espera que este método brinde resultados correctos porque se usa con tanta frecuencia. Pero no es una garantía de confiabilidad ni produce conclusiones estadísticamente sólidas", dice el Dr. Eran Elhaik, profesor asociado de biología de células moleculares en la Universidad de Lund.
Según Elhaik, el método ayudó a crear viejas percepciones sobre raza y etnia. Desempeña un papel en la elaboración de relatos históricos sobre quiénes y de dónde provienen las personas, no solo por parte de la comunidad científica sino también por parte de las empresas de ascendencia comercial. Un ejemplo famoso es cuando un destacado político estadounidense realizó una prueba de ascendencia antes de la campaña presidencial de 2020 para respaldar sus reclamos ancestrales. Otro ejemplo es la idea errónea de que los judíos asquenazíes son una raza o un grupo aislado impulsado por los resultados de la PCA.
"Este estudio demuestra que esos resultados no eran fiables", dice Eran Elhaik.
PCA se usa en muchos campos científicos, pero el estudio de Elhaik se centra en su uso en genética de poblaciones, donde la explosión en el tamaño de los conjuntos de datos es particularmente aguda, lo que se debe a los costos reducidos de la secuenciación del ADN.
El campo de la paleogenómica, en el que queremos aprender sobre pueblos antiguos e individuos como los europeos de la Edad del Cobre, se basa en gran medida en PCA. PCA se utiliza para crear un mapa genético que posiciona la muestra desconocida junto con las muestras de referencia conocidas. Hasta ahora, se ha asumido que las muestras desconocidas están relacionadas con la población de referencia con la que se superponen o se encuentran más cerca en el mapa.
Sin embargo, Elhaik descubrió que la muestra desconocida podría estar cerca de prácticamente cualquier población de referencia simplemente cambiando los números y tipos de las muestras de referencia, generando versiones históricas prácticamente infinitas, todas matemáticamente "correctas", pero solo una puede ser biológicamente correcta. .
En el estudio, Elhaik ha examinado las doce aplicaciones genéticas de población más comunes de PCA. Ha utilizado datos genéticos reales y simulados para mostrar cuán flexibles pueden ser los resultados de PCA. Según Elhaik, esta flexibilidad significa que no se puede confiar en las conclusiones basadas en PCA, ya que cualquier cambio en las muestras de referencia o de prueba producirá resultados diferentes.
Entre 32 000 y 216 000 artículos científicos solo en genética han empleado PCA para explorar y visualizar similitudes y diferencias entre individuos y poblaciones y han basado sus conclusiones en estos resultados.
"Creo que estos resultados deben reevaluarse", dice Elhaik.
Él espera que el nuevo estudio desarrolle un mejor enfoque para cuestionar los resultados y, por lo tanto, ayude a que la ciencia sea más confiable. Pasó una parte significativa de la última década siendo pionero en métodos como la estructura de población geográfica (GPS), para predecir la biogeografía a partir del ADN, y el Pairwise Matcher, que mejora las coincidencias de casos y controles utilizadas en pruebas genéticas y ensayos de medicamentos.
"Las técnicas que ofrecen tal flexibilidad fomentan la mala ciencia y son particularmente peligrosas en un mundo donde existe una intensa presión para publicar. Si un investigador ejecuta PCA varias veces, la tentación siempre será seleccionar el resultado que hace la mejor historia", agrega el profesor. William Amos, de la Universidad de Cambridge, que no participó en el estudio. Investigadores desarrollan el primer método basado en IA para datar restos arqueológicos