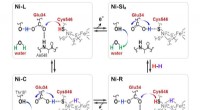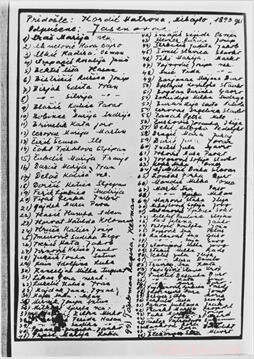
Uno de más de 7, 000 listas de nombres de campos de concentración en el Museo Conmemorativo del Holocausto de EE. UU. Ésta es una lista manuscrita de mujeres serbias y croatas que fueron deportadas al campo de concentración de Jasenovac. Crédito:Museo Conmemorativo del Holocausto de los Estados Unidos
Melkior Ornik, miembro de la facultad de ingeniería aeroespacial, también es matemático, un aficionado a la historia, y un firme creyente en la integridad cuando se trata de utilizar la ciencia sólida en los debates públicos. Entonces, cuando apareció una historia en su canal de noticias sobre un par de investigadores que desarrollaron un método estadístico para analizar conjuntos de datos y lo usaron para refutar supuestamente el número de víctimas del Holocausto en un campo de concentración en Croacia, naturalmente llamó su atención.
Ornik es profesor en el Departamento de Ingeniería Aeroespacial de la Universidad de Illinois Urbana-Champaign. Procedió a estudiar la investigación en profundidad y utilizó el método para volver a analizar los mismos datos del Museo Conmemorativo del Holocausto de los Estados Unidos. Luego, escribió un artículo de refutación en el que desacreditaba los hallazgos de los investigadores.
La refutación de Ornik se publica en la misma revista que el artículo original. Dijo que el editor le pidió que incluyera una lista de respuestas a algunas de las posibles preguntas que otros científicos pueden tener cuando lean su artículo. Unas pocas semanas después, la revista colocó una nota en el artículo original indicando que no respalda ni comparte las opiniones de los autores, y recomendó leer el artículo de Ornik.
"Como científicos, como ingenieros, Creo que es nuestro deber corregir la ciencia defectuosa y defectuosa, ", Dijo Ornik." Hay tanto esfuerzo para lograr que el público y los legisladores crean en la ciencia, que cuando un experto en matemáticas dice que tiene pruebas, da credibilidad al argumento. Pero cuando se demuestra que sus afirmaciones no son ciertas, no es bueno para la ciencia y no es bueno para la sociedad. Por eso es especialmente importante que los científicos desafíen los hallazgos falsos cuando los descubrimos ".
Según Ornik, Algunas personas promueven la opinión de que los campos de concentración o no existían o no se usaban para matar personas, o que el número de víctimas actualmente ampliamente aceptado se ha inflado sustancialmente. La mayoría de los historiadores no se toman en serio las afirmaciones a la luz de la gran cantidad de datos y pruebas disponibles.
"Que los autores del artículo original afirmen que han encontrado pruebas matemáticas de que la lista de víctimas de ese campo fue fabricada tiene obvias implicaciones históricas, "Dijo Ornik." Creo, hasta cierto punto, el daño ya está hecho, pero sentí la necesidad de dejar constancia de las suposiciones, inexactitudes, y el uso indebido de los datos sin procesar del museo que encontré en la investigación original ".
El artículo al que respondió Ornik presenta un método novedoso para identificar anomalías en un conjunto de histogramas. Ornik dijo que no discute los méritos del método presentado en el documento original, solo su aplicación al campo de concentración de Jasenovac.
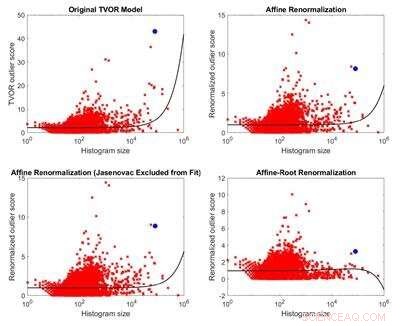
Comparación del modelo original de identificación de valores atípicos y tres modelos derivados de él. Debido a la inaplicabilidad de sus supuestos al conjunto de datos considerado, el modelo original no tiene fundamento teórico. Tres modelos alternativos están menos sesgados al tamaño que el modelo original y producen resultados opuestos. Crédito:Melkior Ornik
Ornik comenzó a sospechar de las conclusiones del artículo porque los investigadores insinuaron en un caso que una lista más pequeña, naturalmente, tiene una puntuación más pequeña. pero compararon las puntuaciones de los tamaños de las listas de víctimas para afirmar que la relacionada con Jasenovac, uno de los más grandes, fue problemático.
"Empecé a buscar para ver si había algún tipo de sesgo en el tamaño y si en realidad era más probable que asignaran la bandera de ser problemático a una lista más grande o no. Y resulta que, a pesar de las afirmaciones de los autores, Ellos eran, "Dijo Ornik." Es más probable que las listas más grandes sean calculadas como problemáticas que las listas más pequeñas cuando su método se aplica a los datos ".
Ornik, que suele utilizar análisis estadísticos similares en aplicaciones aeroespaciales, explicó otra razón por la que su argumento estadístico no funciona.
"Cuando miras los datos, una colección de cualquier cosa, y desea descubrir un valor atípico, algo que es diferente, debe asumir que todos los datos provienen de la misma fuente, la misma distribución. Tome una lista de víctimas por año de nacimiento. Produciría un gráfico de las edades de cada persona. Digamos que el 10 por ciento tiene más de 70 años. Ahora, esa distribución no sería cierta para una lista de niños deportados, por ejemplo, porque esa lista, por definición, es estructuralmente diferente. También es diferente de una lista de todos los que tienen cédula de identidad. Las tarjetas de identidad se emiten solo a personas que no son niños. Todavía, las listas con las que trabajaron estos investigadores provienen de una multitud de fuentes e incluyen listas de niños, listas de personas que se casan, listas de prisioneros de guerra, cosas que, por definición, no pueden provenir de la misma distribución ".
Otro error importante en el papel original, Ornik dijo:es que algunas listas duplicadas se trataron como dos listas separadas. Esto significaba que aproximadamente el 67 por ciento de toda su base de datos eran en realidad sublistas de la lista más grande.
"El 7, Más de 000 listas publicadas en línea por el Museo del Holocausto no están curadas, "Dijo Ornik." Por ejemplo, hay dos listas que contienen exactamente los mismos datos; uno está en cirílico y el otro usa el alfabeto latino. Pero los trataron como dos listas separadas. Hay otras listas que contienen el mismo nombre, pero no hay forma de saber si son la misma persona o dos personas diferentes nacidas el mismo día con nombres idénticos. Podrían haber eliminado los errores muy atroces en los que una lista está claramente duplicada, pero el resto, necesitaría acceder a los datos históricos originales ".
Tanto el documento original como el de Ornik, "Comente sobre 'TVOR:Encontrar valores atípicos de variación total discreta entre histogramas, '"se publican en Acceso IEEE .