Crédito:Lee y otros.
En los últimos años, los algoritmos de aprendizaje profundo han logrado resultados notables en una variedad de campos, incluidas las disciplinas artísticas. De hecho, muchos informáticos de todo el mundo han desarrollado con éxito modelos que pueden crear obras artísticas, incluidos poemas, pinturas y bocetos.
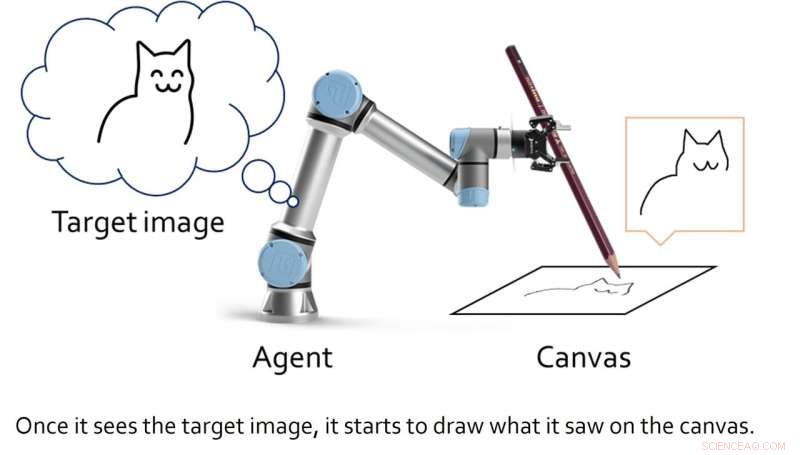
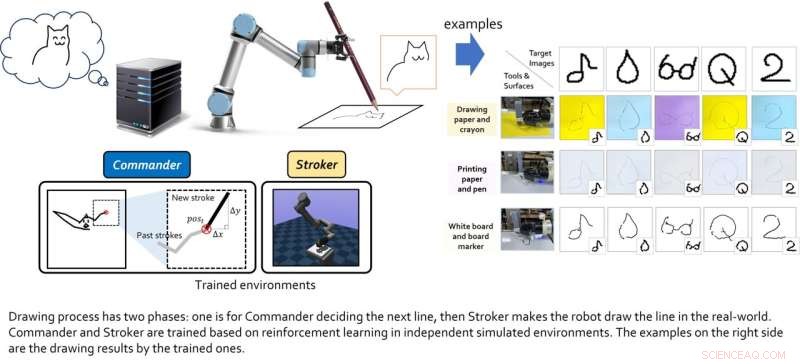
Investigadores de la Universidad Nacional de Seúl introdujeron recientemente un nuevo marco de aprendizaje profundo artístico, que está diseñado para mejorar las habilidades de un robot de dibujo. Su marco, introducido en un artículo presentado en ICRA 2022 y prepublicado en arXiv, permite que un robot de dibujo aprenda tanto el renderizado basado en trazos como el control del motor simultáneamente.
"La principal motivación de nuestra investigación fue hacer algo genial con mecanismos no basados en reglas, como el aprendizaje profundo; pensamos que dibujar es algo genial para mostrar si el dibujante es un robot aprendido en lugar de un humano", Ganghun Lee, el primer autor del artículo, le dijo a TechXplore. "Las técnicas recientes de aprendizaje profundo han mostrado resultados sorprendentes en el área artística, pero la mayoría de ellas se trata de modelos generativos que producen resultados de píxeles completos a la vez".
En lugar de desarrollar un modelo generativo que produzca obras artísticas generando patrones de píxeles específicos, Lee y sus colegas crearon un marco que representa el dibujo como un proceso de decisión secuencial. Este proceso secuencial se asemeja a la forma en que los humanos dibujarían líneas individuales con un bolígrafo o un lápiz para crear gradualmente un boceto.
Luego, los investigadores esperaban aplicar su marco a un agente de dibujo robótico, de modo que pudiera producir bocetos en tiempo real usando un bolígrafo o lápiz real. Mientras que otros equipos crearon algoritmos de aprendizaje profundo para "artistas de robots" en el pasado, estos modelos generalmente requerían grandes conjuntos de datos de entrenamiento que contenían bocetos y dibujos, así como enfoques cinemáticos inversos para enseñar al robot a manipular un bolígrafo y dibujar con él.
El marco creado por Lee y sus colegas, por otro lado, no se entrenó en ningún ejemplo de dibujo del mundo real. En cambio, puede desarrollar de forma autónoma sus propias estrategias de dibujo a lo largo del tiempo, a través de un proceso de prueba y error.
"Nuestro marco tampoco utiliza cinemática inversa, que hace que los movimientos del robot sean un poco estrictos, sino que también permite que el sistema encuentre sus propios trucos de movimiento (ajustando los valores de las articulaciones) para hacer que el estilo de movimiento sea lo más natural posible", dijo Lee. "En otras palabras, mueve directamente sus articulaciones sin primitivas, mientras que muchos sistemas robóticos comúnmente usan primitivas para moverse".
Crédito:Lee y otros.
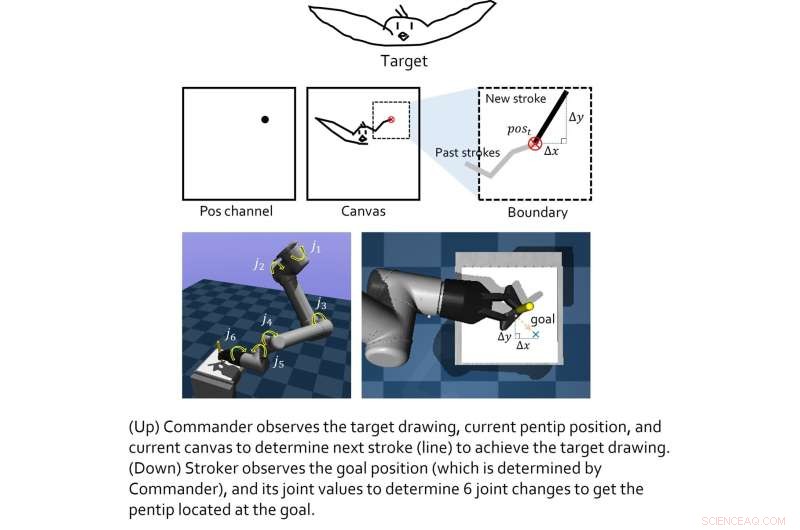
El modelo creado por este equipo de investigadores incluye dos "agentes virtuales", a saber, el agente de clase alta y el de clase baja. El papel del agente de clase alta es aprender nuevos trucos de dibujo, mientras que el agente de clase baja aprende estrategias de movimiento efectivas.
Los dos agentes virtuales fueron entrenados de forma individual mediante técnicas de aprendizaje por refuerzo y sólo se acoplaron una vez completada su respectiva formación. Luego, Lee y sus colegas probaron su rendimiento combinado en una serie de experimentos del mundo real, utilizando un brazo robótico de 6 grados de libertad con una pinza 2D. Los resultados obtenidos en estas pruebas iniciales fueron muy alentadores, ya que el algoritmo permitió al agente robótico producir buenos bocetos de imágenes específicas.

Crédito:Lee y otros.
"Descubrimos que los módulos basados en el aprendizaje de refuerzo capacitados para cada objetivo se pueden fusionar para lograr objetivos de colaboración más grandes", explicó Lee. "En un entorno jerárquico, las decisiones del agente superior pueden ser el 'estado intermedio', lo que permite que el agente inferior observe para tomar decisiones inferiores. Si cada agente de niveles está bien entrenado y lo suficientemente generalizado para cada espacio de estado, entonces un Todo el sistema hecho de cada módulo puede hacer grandes cosas. Sin embargo, la condición principal es que, como lo han hecho todos los enfoques de aprendizaje por refuerzo, las funciones de recompensa para cada agente deben estar bien formadas (no es fácil)".
En el futuro, el marco creado por Lee y sus colegas podría usarse para mejorar el rendimiento de los agentes de dibujo robótico existentes y desarrollados recientemente. Mientras tanto, Lee está desarrollando modelos similares basados en el aprendizaje por refuerzo creativo, incluido un sistema que puede producir collages artísticos.
Crédito:Lee y otros.
"También nos gustaría extender la tarea a dibujos robóticos más complicados, como pinturas, pero ahora me estoy enfocando más en los problemas prácticos de las aplicaciones de aprendizaje por refuerzo que en los dibujos robóticos", agregó Lee. "Espero que nuestro artículo se convierta en un ejemplo divertido y significativo de una aplicación basada en el aprendizaje por refuerzo puro, especialmente equipada con robots".
© 2022 Red Ciencia X Un marco de aprendizaje por refuerzo para mejorar las habilidades de lanzamiento de fútbol de los robots cuadrúpedos