Crédito:Google
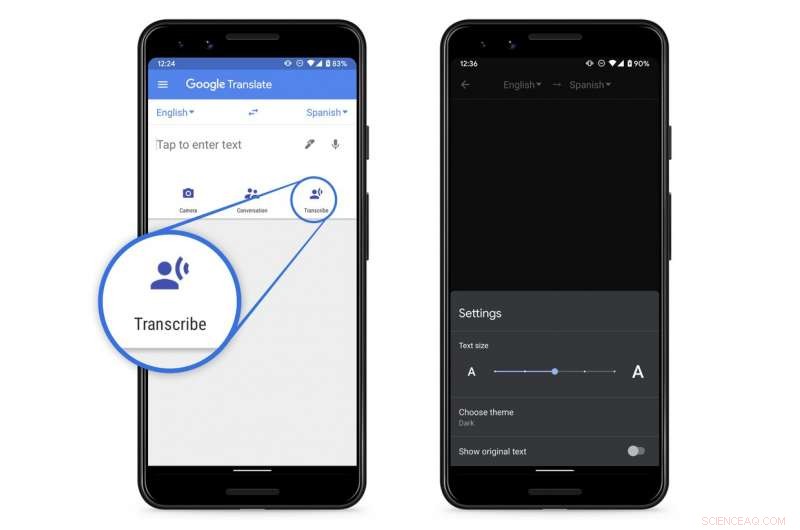
Google ha anunciado una nueva función de transcripción en tiempo real para su aplicación gratuita Translate para teléfonos Android. Se planea una versión de IOS para el futuro, dice la empresa.
La función permitirá a los usuarios obtener traducciones instantáneas de texto de discursos en curso, conferencias o monólogos en cualquiera de los ocho idiomas, incluido el inglés.
En la actualidad, Translate permite conversiones de fragmentos de voz relativamente cortos.
Los únicos requisitos son tener solo un orador hablando a la vez en una habitación silenciosa (otras voces o ruidos disminuirán la precisión) y una conexión a Internet. necesario para la interacción con las unidades de procesamiento de tensores basadas en la nube de Google.
El lanzamiento comienza hoy (18 de marzo) y debería estar disponible para todos los usuarios al final de la semana en la Play Store de Google.
En modo conversación, la aplicación permite a los usuarios tener una conversación de ida y vuelta con alguien que habla un idioma diferente.
Además del inglés, las traducciones están disponibles en francés, Alemán, Hindi, Portugués, Ruso, Español y tailandés.
La aplicación también funcionará con reproducciones de audio pregrabado. Pero Google dice que la traducción digital directa de los archivos de audio cargados aún no está disponible.
El anuncio de esta semana es un recordatorio de lo lejos que hemos llegado desde los primeros días del reconocimiento de voz digital. Bell Laboratories debutó con su futurista sistema "Audrey" en 1952 que reconocía los dígitos hablados del 0 al 9. Se dio un paso de gigante una década más tarde cuando IBM exhibió la "Caja de zapatos" en la Feria Mundial de 1962:podía reconocer la friolera de 16 palabras.
Durante cinco años en la década de 1970, El reconocimiento de voz recibió un gran impulso del ejército de Estados Unidos. El Departamento de Defensa financió proyectos de investigación masivos sobre reconocimiento de voz, incluida la iniciativa "Harpy" Speech Understanding Research (SUR) de Carnegie-Mellon, que construyó un vocabulario de reconocimiento de más de 1, 011 palabras. Ese programa introdujo notablemente el concepto de patrones de pronunciación y probabilidad por primera vez, mejorando enormemente la capacidad de reconocer distintos modos de hablar.
La década de 1980 trajo consigo avances cada vez mayores en la detección de palabras, con investigadores aplicando la teoría de la probabilidad a sonidos desconocidos. El programa del gigante tecnológico IBM amplió el reconocimiento a 5, 000 palabras. Pero la década puede recordarse mejor por la presentación de la primera muñeca parlante del mundo, "Julie, "que entendía el discurso. Una campaña publicitaria decía:" Finalmente, la muñeca que te entiende ".
Dragon llevó el reconocimiento de voz a las masas en la década de 1990, con su primer producto de consumo en gran parte preciso, aunque aún con errores, a un precio de "solo" $ 9, 000. A finales de la década, el programa Dragon NaturallySpeaking enormemente mejorado, que por primera vez no requirió pausas entre cada palabra hablada, estaba disponible para los consumidores por alrededor de $ 700.
Hoy tenemos Siri y Alexa y otras aplicaciones móviles gratuitas y de bajo costo que nos permiten solicitar direcciones de manejo, ordenar comida, comprar artículos para el hogar y escribir texto hablado en correos electrónicos y documentos de procesamiento de texto, todo lo cual ha expandido el reconocimiento de voz a puntos inimaginables no hace muchos años.
Con los últimos avances disponibles para millones de usuarios con dispositivos de mano, Arpía, Audrey, Julie probablemente se quedaría sin palabras.
© 2020 Science X Network














