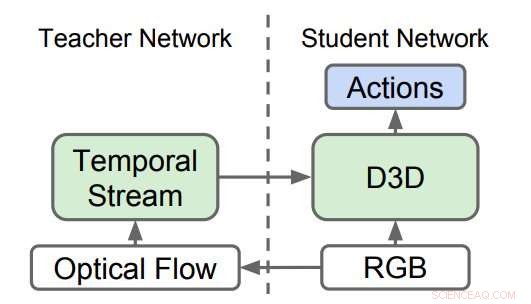
Redes 3D destiladas (D3D). Los investigadores entrenaron una CNN 3D para reconocer acciones de video RGB mientras destilaban conocimiento de una red que reconoce acciones de secuencias de flujo óptico. Durante la inferencia, solo se utiliza D3D. Crédito:Stroud et al.
Un equipo de investigadores de Google la Universidad de Michigan y la Universidad de Princeton han desarrollado recientemente un nuevo método para el reconocimiento de acciones por video. El reconocimiento de acciones de video implica identificar acciones particulares realizadas en secuencias de video, como abrir una puerta, cerrando una puerta, etc.
Los investigadores han estado tratando de enseñar a las computadoras a reconocer acciones humanas y no humanas en video durante años. La mayoría de las herramientas de reconocimiento de acción de video de última generación emplean un conjunto de dos redes neuronales:la secuencia espacial y la secuencia temporal.
En estos enfoques, una red neuronal está entrenada para reconocer acciones en un flujo de imágenes regulares basadas en la apariencia (es decir, el 'flujo espacial') y la segunda red está entrenada para reconocer acciones en un flujo de datos de movimiento (es decir, el 'flujo temporal'). Los resultados obtenidos por estas dos redes se combinan para lograr el reconocimiento de acciones de video.
Aunque los resultados empíricos logrados utilizando enfoques de 'dos corrientes' son excelentes, estos métodos se basan en dos redes distintas, en lugar de uno solo. El objetivo del estudio realizado por los investigadores de Google, la Universidad de Michigan y Princeton iba a investigar formas de mejorar esto, para reemplazar las dos corrientes de la mayoría de los enfoques existentes con una sola red que aprende directamente de los datos.
En los estudios más recientes, tanto los flujos espaciales como los temporales consisten en redes neuronales convolucionales (CNN) 3-D, que aplican filtros espacio-temporales al videoclip antes de intentar la clasificación. Teóricamente Estos filtros temporales aplicados deberían permitir que la secuencia espacial aprenda representaciones de movimiento, por tanto, la corriente temporal debería ser innecesaria.
En la práctica, sin embargo, el rendimiento de las herramientas de reconocimiento de acciones de video mejora cuando se incluye una secuencia temporal completamente separada. Esto sugiere que el flujo espacial por sí solo no puede detectar algunas de las señales capturadas por el flujo temporal.
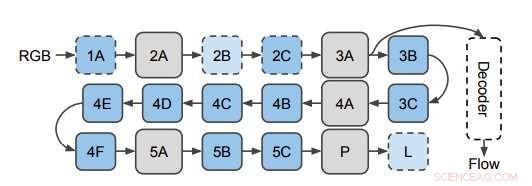
La red utilizada para predecir el flujo óptico de las funciones 3D de CNN. Los investigadores aplican el decodificador en capas ocultas en la CNN 3D (representada aquí en la capa 3A). Este diagrama muestra la estructura de I3D / S3D-G, donde los cuadros azules representan la convolución (líneas discontinuas) o los bloques de inicio (líneas continuas), y los recuadros grises representan bloques agrupados. Los nombres de las capas son los mismos que los utilizados en Inception. Crédito:Stroud et al.
Para examinar más a fondo esta observación, Los investigadores investigaron si el flujo espacial de CNN 3-D para el reconocimiento de acciones de video carece de representaciones de movimiento. Después, demostraron que estas representaciones de movimiento se pueden mejorar mediante destilación, una técnica para comprimir el conocimiento en un conjunto en un solo modelo.
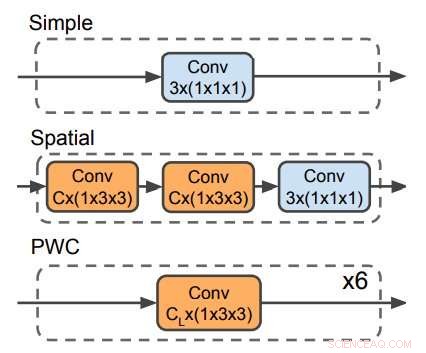
Se utilizan tres decodificadores para predecir el flujo óptico. El decodificador PWC se parece a la red de predicción de flujo óptico de PWC-net. Ningún decodificador utiliza filtros temporales. Crédito:Stroud et al.
Los investigadores capacitaron a una red de 'maestros' para reconocer acciones dadas la entrada de movimiento. Luego, formaron una segunda red de 'estudiantes', que solo se alimenta del flujo de imágenes regulares, con un doble objetivo:hacer bien la tarea de reconocimiento de acciones e imitar el resultado de la red de profesores. Esencialmente, la red de estudiantes aprende a reconocer basándose tanto en la apariencia como en el movimiento, mejor que el profesor y así como los modelos de dos corrientes más grandes y engorrosos.
Recientemente, varios estudios también probaron un enfoque alternativo para el reconocimiento de acciones de video, lo que implica entrenar una sola red con dos objetivos diferentes:desempeñarse bien en la tarea de reconocimiento de acciones y predecir directamente las señales de movimiento de bajo nivel (es decir, el flujo óptico) en el video. Los investigadores encontraron que su método de destilación superó este enfoque. Esto sugiere que es menos importante para una red reconocer efectivamente el flujo óptico de bajo nivel en un video que reproducir el conocimiento de alto nivel que la red de profesores ha aprendido sobre el reconocimiento de acciones a partir del movimiento.
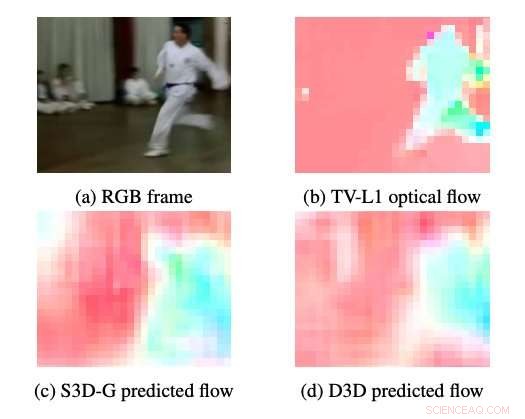
Ejemplos de flujo óptico producido por S3DG y D3D (sin ajuste fino) utilizando el decodificador PWC aplicado en la capa 3A. El color y la saturación de cada píxel corresponde al ángulo y la magnitud del movimiento, respectivamente. El flujo óptico de TV-L1 se muestra a 28 × 28px, la resolución de salida del decodificador. Crédito:Stroud et al.
Los investigadores demostraron que es posible entrenar una red neuronal de flujo único que funciona tan bien como enfoques de dos flujos. Sus hallazgos sugieren que el rendimiento de los métodos actuales de vanguardia para el reconocimiento de acciones de video podría lograrse utilizando aproximadamente 1/3 del cálculo. Esto facilitaría la ejecución de estos modelos en dispositivos con limitaciones de cálculo, como teléfonos inteligentes, y a mayor escala (por ejemplo, para identificar acciones, como 'slam dunks', en videos de YouTube).
En general, este estudio reciente destaca algunas de las deficiencias de los métodos de reconocimiento de acciones de video existentes, proponiendo un nuevo enfoque que implica la formación de un profesor y una red de estudiantes. Investigación futura, sin embargo, podría intentar lograr un desempeño de vanguardia sin la necesidad de una red de maestros, alimentando los datos de entrenamiento directamente a la red de estudiantes.
© 2019 Science X Network