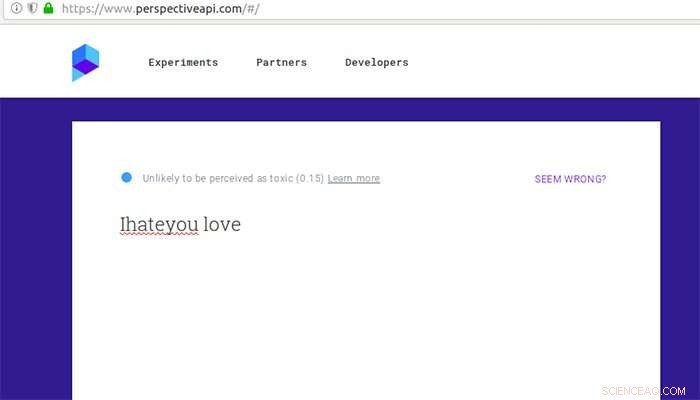
Cómo califica Google Perspective un comentario que de otro modo se consideraría tóxico después de algunos errores tipográficos insertados y un poco de amor. Crédito:Universidad Aalto
Los mensajes de texto y los comentarios que incitan al odio son un problema cada vez mayor en los entornos en línea, Sin embargo, abordar el problema desenfrenado se basa en poder identificar el contenido tóxico. Un nuevo estudio realizado por el grupo de investigación de Sistemas Seguros de la Universidad de Aalto ha descubierto debilidades en muchos detectores de aprendizaje automático que se utilizan actualmente para reconocer y mantener a raya el discurso de odio.
Muchas redes sociales y plataformas en línea populares utilizan detectores de incitación al odio que un equipo de investigadores dirigido por el profesor N. Asokan ha demostrado que son frágiles y fáciles de engañar. La mala gramática y la ortografía incómoda, intencional o no, pueden hacer que los comentarios tóxicos en las redes sociales sean más difíciles de detectar para los detectores de IA.
El equipo puso a prueba siete detectores de discurso de odio de última generación. Todos fallaron.
Las técnicas modernas de procesamiento del lenguaje natural (PNL) pueden clasificar el texto en función de caracteres individuales, palabras u oraciones. Cuando se enfrentan a datos textuales que difieren de los utilizados en su formación, comienzan a buscar a tientas.
"Insertamos errores tipográficos, cambiaron los límites de las palabras o agregaron palabras neutrales al discurso de odio original. Eliminar espacios entre palabras fue el ataque más poderoso, y una combinación de estos métodos fue efectiva incluso contra el sistema de clasificación de comentarios de Google Perspective, "dice Tommi Gröndahl, estudiante de doctorado en la Universidad de Aalto.
Google Perspective clasifica la 'toxicidad' de los comentarios utilizando métodos de análisis de texto. En 2017, Investigadores de la Universidad de Washington demostraron que se puede engañar a Google Perspective introduciendo simples errores tipográficos. Gröndahl y sus colegas ahora han descubierto que Perspective se ha vuelto resistente a errores tipográficos simples, pero aún puede ser engañado por otras modificaciones, como eliminar espacios o agregar palabras inocuas como "amor".
Una frase como "Te odio" se deslizó por el tamiz y se convirtió en no odiosa cuando se modificó en "Te odio, te amo".
Los investigadores señalan que en diferentes contextos, la misma expresión puede considerarse odiosa o simplemente ofensiva. El discurso de odio es subjetivo y específico del contexto, lo que hace que las técnicas de análisis de texto sean insuficientes como soluciones independientes.
Los investigadores recomiendan que se preste más atención a la calidad de los conjuntos de datos utilizados para entrenar modelos de aprendizaje automático, en lugar de refinar el diseño del modelo. Los resultados indican que la detección basada en caracteres podría ser una forma viable de mejorar las aplicaciones actuales.
El estudio se llevó a cabo en colaboración con investigadores de la Universidad de Padua en Italia. Los resultados se presentarán en el taller ACM AISec en octubre.
El estudio es parte de un proyecto en curso llamado "Detección de engaños a través del análisis de texto en los sistemas seguros" en la Universidad de Aalto.