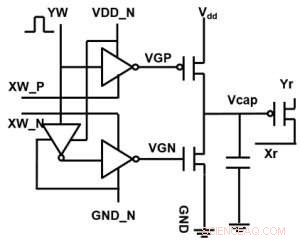
Figura 1. Esquema de celda unitaria de una matriz de puntos cruzados basada en condensadores. Crédito:IBM
IBM está llegando más allá de las tecnologías digitales con una matriz de puntos cruzados basada en condensadores para redes neuronales analógicas, exhibiendo mejoras potenciales de órdenes de magnitud en los cálculos de aprendizaje profundo. Las arquitecturas de computación analógica explotan la capacidad de almacenamiento y los atributos físicos de ciertos dispositivos de memoria no solo para almacenar información, sino también para realizar cálculos. Esto tiene el potencial de reducir en gran medida el tiempo y la energía que requieren las computadoras porque no es necesario transferir datos entre la memoria y el procesador. El inconveniente podría ser una reducción en la precisión computacional, pero para sistemas que no requieren alta precisión, es la compensación correcta.
En redes neuronales analógicas (NN), Los arreglos de puntos cruzados basados en memoria no volátil (NVM) han logrado resultados prometedores para las tareas de inferencia. Sin embargo, entrenar NN con alta precisión es difícil para los dispositivos NVM, ya que el entrenamiento exitoso depende de mantener pequeños los cambios incrementales en el peso NN (requiriendo aproximadamente 1, 000 estados de actualización) y simétrico (de modo que las actualizaciones positivas y negativas se equilibren en promedio). Estos problemas se pueden solucionar mediante el uso de condensadores. Dado que la carga se puede sumar o restar continuamente si el número de electrones es alto, Se puede lograr una actualización de peso analógica y simétrica. Presentamos una matriz de puntos cruzados basada en condensadores para redes neuronales analógicas en el Simposio de tecnología VLSI 2018. La nueva arquitectura logró una simetría y linealidad récord para la actualización del peso.
La Figura 1 muestra el esquema de celda unitaria de una matriz de puntos cruzados basada en condensadores. El componente clave es el condensador que está conectado a un transistor de efecto de campo de lectura (FET). La carga del condensador representa el peso sináptico y el condensador se carga y descarga con dos FET de fuente de corriente. La Figura 2 muestra el cambio medido en la conductancia del FET de lectura de una sola celda, y voltaje del condensador correspondiente respectivamente, aplicando diez ciclos de 400 actualizaciones positivas seguidas de 400 actualizaciones negativas. La Figura 3 compara los factores experimentales de actualización de no linealidad para nuestra sinapsis analógica basada en condensadores con otras tecnologías NVM. La celda unitaria basada en condensadores proporciona la mejor simetría y linealidad demostradas hasta la fecha. La Figura 4 muestra la actualización de peso en paralelo en una matriz de 2 × 2.
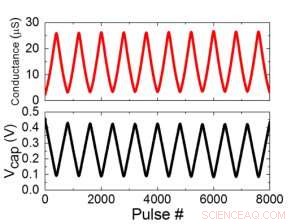
Figura 2. (a) Resultados experimentales para la actualización de una celda con 8000 pulsos. (b) Cambio de voltaje del capacitor correspondiente. Ancho de pulso 50 ns, período:500 ns. Crédito:IBM
Aunque los condensadores son volátiles, la fuga podría compensarse durante la actualización del peso. Dado que el entrenamiento avanza repetidamente, ciclos de actualización de peso y retroceso, los pesos después de la descomposición en el ciclo anterior se utilizan en el entrenamiento para el siguiente ciclo y se actualizan. Por lo tanto, no se necesitan ciclos de actualización intencionales. Probamos el efecto del tiempo de retención en el entrenamiento, utilizando una red completamente conectada. Tiene una capa de entrada, dos capas ocultas, y una capa de salida (Figura 5) y se entrenó en el conjunto de datos MNIST mediante descenso de gradiente estocástico y retropropagación. Suponiendo que la duración del ciclo de entrenamiento por capa (adelante + atrás + actualización) es de 200 ns y el peso sináptico decae con la constante de tiempo RC τ, encontramos que la penalización en la precisión del entrenamiento debido a la pérdida de carga del capacitor se vuelve insignificante cuando τ> 106 × la duración del ciclo de entrenamiento (Figura 6). También probamos el requisito de tiempo de retención para una red convolucional. Nuestra red de prueba tiene dos capas convolucionales con dos capas de agrupación y dos capas completamente conectadas (Figura 7). Debido al peso compartido (reutilización) en capas convolucionales, los requisitos de retención para una red neuronal convolucional (CNN) son aproximadamente 600 más (Figura 8).
Estimamos la escalabilidad de esta matriz basada en condensadores en función de la fuga para redes neuronales convolucionales y completamente conectadas (Figura 9). Los puntos de datos circulares muestran que el capacitor escala linealmente con la fuga del transistor de paso. Los puntos de datos cuadrados muestran que cuando la fuga es grande, el área de la celda está dominada por los condensadores; cuando la corriente de fuga es pequeña, el área estará dominada por FET en la celda. Para tecnología DRAM con fugas de 1 fA / celda se requiere condensador <1fF / celda para una red neuronal completamente conectada y ~ 100 fF / celda para CNN. La escalabilidad a una entrada más grande y más capas necesita más estudio. Aunque puede necesitar un condensador más grande cuando la entrada se hace más grande, Nuestros resultados preliminares (que se publicarán) muestran que la optimización de la red / algoritmo podría reducir la necesidad de condensadores.
IBM ahora está trabajando en una memoria ideal novedosa con comportamiento analógico optimizado. Estos condensadores permitirán que el núcleo de IA analógico se implemente en un programa acelerado, ya que la tecnología y el proceso están disponibles.
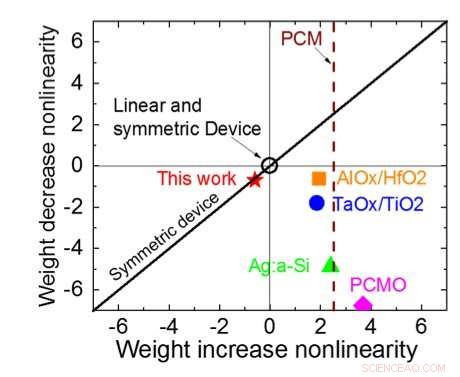
Figura 3. No linealidad de la conductancia de este trabajo en comparación con otras tecnologías NVM. Crédito:IBM
Además de nuestro enfoque de condensadores, IBM está explorando otros elementos novedosos para la memoria analógica y la computación, como la memoria de cambio de fase (PCM) y la RAM resistiva (RRAM). Estos elementos varían en términos de áreas de celda, retencion, simetría, y madurez. Los aceleradores analógicos son un componente de la línea de aceleradores de hardware de IA de IBM Research AI. La canalización comienza con aprovechar al máximo los aceleradores de GPU existentes, seguido de innovadores núcleos de inteligencia artificial digital que explotan la computación aproximada.
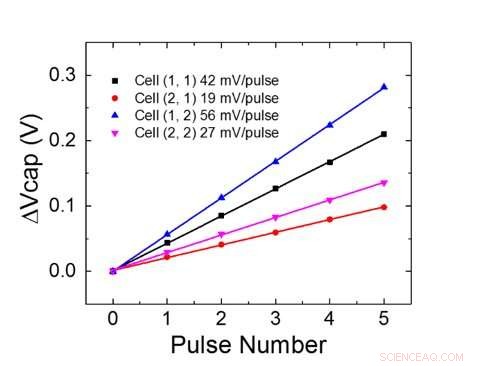
Figura 4. Actualización de peso en paralelo en una matriz de 2 × 2. Crédito:IBM
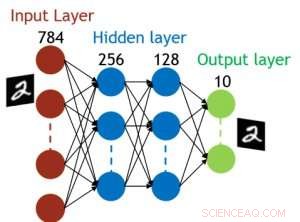
Figura 5. Estructura simulada para una red neuronal completamente conectada. Crédito:IBM
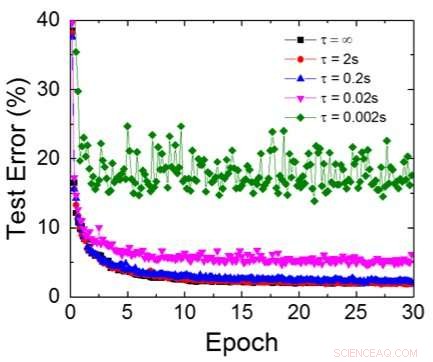
Figura 6. Error de prueba simulado del conjunto de datos MNIST, asumiendo que los pesos decaen continuamente con diferente constante de tiempo RC τ, Duración del ciclo de entrenamiento de 200ns. Crédito:IBM
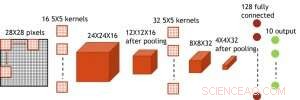
Figura 7. Estructura simulada para red neuronal convolucional. Crédito:IBM
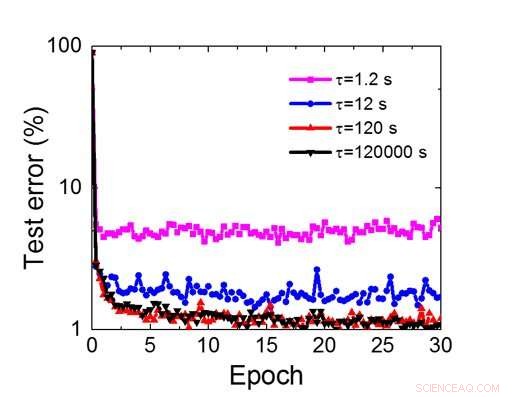
Figura 8. Requisito de tiempo de retención simulado para esta matriz basada en condensadores para entrenar una red neuronal convolucional. Crédito:IBM
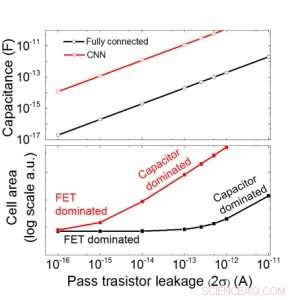
Figura 9. Escalabilidad de esta matriz basada en condensadores en función de la fuga para redes neuronales convolucionales y completamente conectadas. Crédito:IBM














