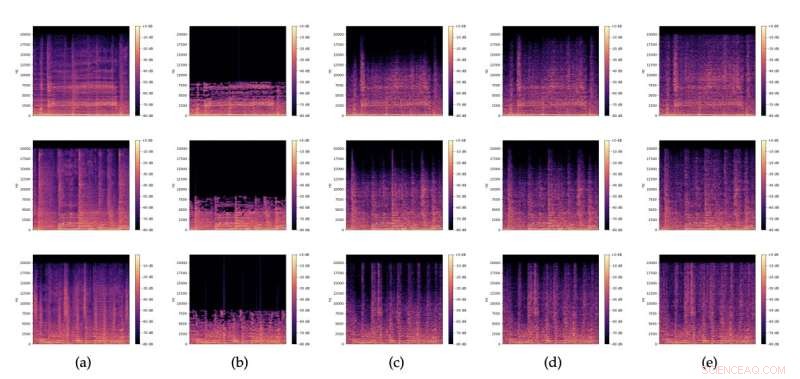
Espectrogramas de (a) extractos de audio originales, (b) versiones MP3 de 32kbit/s correspondientes y (c), (d), (e) restauraciones con diferente ruido z muestreado aleatoriamente de N (0,I). Crédito:Lattner &Nistal.
Durante las últimas décadas, los informáticos han desarrollado tecnologías y herramientas cada vez más avanzadas para almacenar grandes cantidades de archivos de música y audio en dispositivos electrónicos. Un hito particular para el almacenamiento de música fue el desarrollo de la tecnología MP3 (es decir, MPEG-1 capa 3), una técnica para comprimir secuencias de sonido o canciones en archivos muy pequeños que pueden almacenarse y transferirse fácilmente entre dispositivos.
La codificación, edición y compresión de archivos multimedia, incluidos archivos PKZIP, JPEG, GIF, PNG, MP3, AAC, Cinepak y MPEG-2, se logra mediante un conjunto de tecnologías conocidas como códecs. Los códecs son tecnologías de compresión con dos componentes clave:un codificador que comprime archivos y un decodificador que los descomprime.
Hay dos tipos de códecs, los llamados códecs sin pérdida y con pérdida. Durante la descompresión, los códecs sin pérdida, como los códecs PKZIP y PNG, reproducen exactamente el mismo archivo que los archivos originales. Los métodos de compresión con pérdida, por otro lado, producen un facsímil del archivo original que suena (o se ve) como el original pero ocupa menos espacio de almacenamiento en los dispositivos electrónicos.
Los códecs de audio con pérdida esencialmente funcionan comprimiendo transmisiones de audio digital, eliminando algunos datos y luego descomprimiéndolos. Generalmente, la diferencia entre el archivo original y el descomprimido es difícil o imposible de percibir para los humanos.
Sin embargo, cuando los códecs con pérdidas usan altas tasas de compresión, pueden introducir deficiencias y alterar perceptiblemente las señales de audio. Recientemente, los informáticos han intentado superar esta limitación de los códecs con pérdidas y mejorar la calidad de los archivos comprimidos mediante técnicas de aprendizaje profundo.
Investigadores de Sony Computer Science Laboratories (CSL) desarrollaron recientemente un nuevo método de aprendizaje profundo para mejorar y restaurar la calidad de canciones y grabaciones de audio muy comprimidas (es decir, archivos de audio que fueron comprimidos por códecs con pérdidas con altas tasas de compresión). Este método, presentado en un artículo prepublicado en arXiv, se basa en redes adversarias generativas (GAN), modelos de aprendizaje automático en los que dos redes neuronales "compiten" para hacer predicciones cada vez más precisas o confiables.
"Muchos trabajos han abordado el problema de la mejora de audio y la eliminación de artefactos de compresión utilizando técnicas de aprendizaje profundo", escribieron Stefan Lattner y Javier Nistal en su artículo. "Sin embargo, solo unos pocos trabajos abordan la restauración de señales de audio muy comprimidas en el dominio musical. En este estudio, probamos un generador estocástico para una arquitectura de red antagónica generativa (GAN) para esta tarea".
Al igual que otras GAN, el modelo creado por Lattner y Nistal se compone de dos modelos separados, conocidos como el "generador (G)" y el "crítico (D)". El generador recibe un extracto de una señal de audio musical comprimida en MP3, representada a través de un espectrograma (es decir, una representación visual de las frecuencias del espectro de una señal de audio).
El generador aprende continuamente a producir una versión restaurada de esta señal original, que es de menor tamaño. Mientras tanto, el componente crítico de la arquitectura GAN aprende a distinguir entre los archivos originales de alta calidad y las versiones restauradas, detectando así las diferencias entre ellos. En última instancia, la información recopilada por el crítico se utiliza para mejorar la calidad de los archivos restaurados, asegurando que la música o los datos de audio presentes en los archivos restaurados sean lo más fieles posible a los del original.
Lattner y Nistal evaluaron su arquitectura basada en GAN en una serie de pruebas, cuyo objetivo era determinar si su modelo podía mejorar la calidad de las entradas de MP3 y generar muestras comprimidas de mayor calidad y más cercanas a un archivo original que las creadas por otros modelos básicos para la compresión de audio. Sus resultados fueron muy prometedores, ya que descubrieron que las restauraciones del modelo de archivos MP3 muy comprimidos (16 kbit/sy 32 kbit/s) eran normalmente mejores que los archivos comprimidos originales, ya que sonaban mejor para los oyentes humanos expertos. Por otro lado, al usar tasas de compresión más débiles (64 kbit/s mono), el equipo descubrió que su modelo logró resultados ligeramente peores que las herramientas de compresión de MP3 de referencia.
"Realizamos una evaluación exhaustiva de los diferentes experimentos utilizando métricas objetivas y pruebas de escucha", dijeron Lattner y Nistal. "Encontramos que los modelos pueden mejorar la calidad de las señales de audio sobre las versiones MP3 para 16 y 32 kbit/s y que los generadores estocásticos son capaces de generar salidas más cercanas a las señales originales que las de los generadores deterministas".
Como parte de su estudio, los investigadores también demostraron que su arquitectura podía generar y agregar con éxito contenido realista de alta frecuencia que mejoraba la calidad de audio de las canciones comprimidas. El contenido generado incluía elementos de percusión, una voz de canto que producía sibilantes o oclusivas (es decir, sonidos de "s" y "t") y sonidos de guitarra.
En el futuro, el modelo que crearon podría ayudar a reducir significativamente el tamaño de los archivos de música MP3 sin alterar su contenido ni crear errores fácilmente perceptibles. Esto podría tener implicaciones significativas para el almacenamiento y la transmisión de música tanto en aplicaciones de transmisión (por ejemplo, Spotify, Apple Music, etc.) como en dispositivos electrónicos modernos, incluidos teléfonos inteligentes, tabletas y computadoras.
© 2022 Red Ciencia X Google Lyra habilitará las llamadas de voz para otros mil millones de usuarios