Crédito:KTH The Royal Institute of Technology
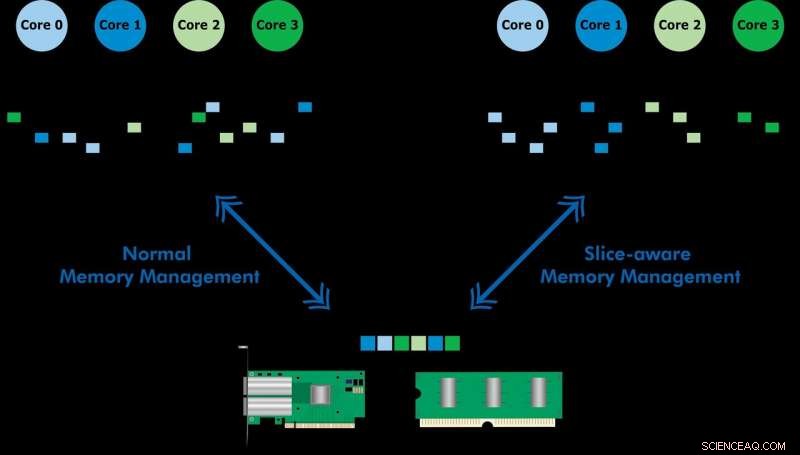
Desarrollado con Ericsson Research, El esquema de administración de memoria con reconocimiento de segmentos permite acceder más rápidamente a los datos de uso frecuente a través de la memoria caché de último nivel (LLC) de una CPU Intel Xeon. Al establecer un almacén de valores clave y asignar memoria de manera que se asigne al segmento de LLC más apropiado, demostraron tanto el procesamiento de paquetes de alta velocidad como el rendimiento mejorado de una tienda de valor clave. El equipo utilizó el esquema propuesto para implementar una herramienta llamada CacheDirector, que hace que Data Direct I / O (DDIO) sea consciente de los segmentos y publicó un documento de conferencia, Aproveche al máximo la caché de último nivel en los procesadores Intel, que se presentó en EuroSys 2019 en la primavera.
"En este momento, un servidor que recibe paquetes de 64 bytes a 100 Gbps tiene solo 5,12 nanosegundos para procesar cada paquete antes de que llegue el siguiente, "dice la coautora Alireza Farshin, estudiante de doctorado en el Laboratorio de Sistemas de Red de KTH. Pero si los datos se enrutan al segmento de caché correcto en la CPU, se puede acceder más rápido, lo que permite un procesamiento más rápido de más paquetes, en menos de 5 nanosegundos.
Data Direct I / O (DDIO) envía paquetes a porciones aleatorias, que está lejos de ser eficiente. Dada la actual arquitectura de caché no uniforme (NUCA), la solución de administración de caché es invaluable, dice el profesor de KTH Dejan Kostic, quien dirigió la investigación.
"Cuando se combina con la introducción del margen dinámico en el kit de desarrollo de plano de datos (DPDK), El encabezado del paquete se puede colocar en el segmento de LLC más cercano al núcleo de procesamiento relevante. Como resultado, el núcleo puede acceder a los paquetes más rápido y al mismo tiempo reducir el tiempo de espera, " él dice.
"Nuestro trabajo demuestra que aprovechar las mejoras de nanosegundos en la latencia puede tener un gran impacto en el rendimiento de las aplicaciones que se ejecutan en sistemas informáticos que ya están altamente optimizados, "Dice Farshin. El equipo descubrió que para una CPU que funciona a 3,2 GHz, CacheDirector puede ahorrar hasta alrededor de 20 ciclos por acceso a la LLC, lo que equivale a 6.25 nanosegundos. Esto acelera el procesamiento de paquetes y reduce las latencias finales de las cadenas de servicios de virtualización de funciones de red (NFV) optimizadas que se ejecutan a 100 Gbps hasta en un 21,5 por ciento.