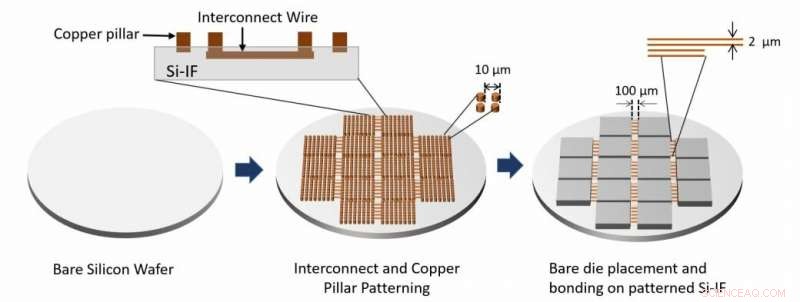
Se muestra el flujo del proceso de ensamblaje del sistema. Las capas de interconexión y los pilares de cobre se fabrican procesando la oblea de silicio desnuda. Luego, los troqueles desnudos se unen a la oblea usando TCB. Crédito:Arquitectura de procesadores Waferscale - Un caso de estudio de GPU, HPCA 19.
Investigadores de la Universidad de Illinois en Urbana-Champaign y la Universidad de California, Los Angeles, están detrás del desarrollo reciente de una computadora a escala de obleas que pretende ser más rápida, más eficiente energéticamente, que sus homólogos contemporáneos.
Los ingenieros apuntan a usar algo llamado "tejido de interconexión de silicio" para construir una computadora con 40 GPU en una sola oblea de silicio. TechSpot y otros sitios informaron sobre su trabajo y su periódico, que se presentará este mes.
Algunos antecedentes sobre Si-IF:"Durante las últimas dos décadas, los chips de silicio han disminuido en tamaño 1000x, mientras que los paquetes en las placas de circuitos solo se han reducido 4 veces, ", dijo UCLA Technology Development Group. Una solución es" tejido de interconexión de silicio (Si-IF) ".
Samuel Moore en Espectro IEEE tiene un artículo muy citado sobre el tema donde señaló resultados:"Las simulaciones de este monstruo multiprocesador aceleraron los cálculos casi 19 veces y redujeron la combinación de consumo de energía y retardo de señal en más de 140 veces".
A saber, el esfuerzo de investigación se encuentra entre los miembros del departamento de ingeniería eléctrica e informática, Universidad de California, Los Angeles, y departamento de ingeniería eléctrica e informática, Universidad de Illinois en Urbana-Champaign. Su artículo se titula "Arquitectura de procesadores de escala de obleas:un estudio de caso de GPU".
El profesor asociado de ingeniería informática de Illinois, Rakesh Kumar, y sus colegas ya comenzaron a trabajar para construir un prototipo de sistema de procesador prototipo de escala de obleas. El grupo lo explorará más a fondo para conocer los problemas que puedan surgir. Creían que había llegado el momento de revisar las arquitecturas de escala de obleas.
Mark Tyson en Hexus :"Los ingenieros de la Universidad de Illinois Urbana-Champaign y de la Universidad de California en Los Ángeles creen que es hora de tener otro intento de crear una computadora a escala de oblea".
El acento se puede poner en la palabra volver a visitar . El equipo escribió en su periódico:"Como era de esperar, Los procesadores waferscale se estudiaron mucho en los años 80. También hubo varios intentos comerciales de construir procesadores de escala de obleas. Desafortunadamente, a pesar de la promesa, tales procesadores no pudieron tener éxito en la corriente principal debido a preocupaciones sobre el rendimiento ".
Dijeron "cuanto mayor sea el tamaño del procesador, cuanto menor era el rendimiento, el rendimiento a escala de obleas en aquellos días era debilitante. Argumentamos que se han logrado avances considerables en la tecnología de fabricación y envasado desde entonces y que puede ser el momento de revisar la viabilidad de los procesadores a escala de obleas ".
El profesor asociado de ingeniería informática de Illinois, Rakesh Kumar, y sus colaboradores están preparados para defender una computadora a escala de obleas que consta de hasta 40 GPU. El mejor titular para recordarnos por qué esto es interesante se puede encontrar en Espectro IEEE . "¿Qué es mejor que 40 servidores basados en GPU? Un servidor con 40 GPU".
Lo que es especial:tienen chips GPU estándar que pasaron las pruebas de calidad; están creando una tecnología que llaman tejido de interconexión de silicio (SiIF) para conectarlos mejor.
Shawn Knight en TechSpot escribió sobre esto. "Con una integración tan estrecha, "dijo Knight, "desde la perspectiva del programador, se vería como una GPU gigante en lugar de 40 GPU individuales ".
SiIF reemplaza la placa de circuito con silicio; no es necesario un paquete de chips, dijo Moore. Informó que en un diseño pudieron incluir 41 GPU. "Probaron una simulación de este diseño y descubrieron que aceleraba tanto el cálculo como el movimiento de datos mientras consumía menos energía que la que consumirían 40 servidores GPU estándar".
Tyson escribió que "como sabrán muchos lectores de HEXUS, Por lo general, las supercomputadoras distribuyen aplicaciones en cientos de GPU en PCB separados, comunicarse a través de enlaces de larga distancia. Dichos enlaces son lentos y energéticamente ineficientes en comparación con las interconexiones dentro de la arquitectura del chip ". Señaló que Kumar habló de obtener datos de una GPU a otra como crear una increíble cantidad de sobrecarga.
Espectro IEEE Moore explicó su trabajo con más detalle.
"La oblea SiIF está modelada con una o más capas de interconexiones de cobre de 2 micrómetros de ancho espaciadas a tan solo 4 micrómetros de distancia. Eso es comparable al nivel superior de interconexiones en un chip. En los lugares donde las GPU deben conectarse , la oblea de silicio está modelada con pilares de cobre cortos separados unos 5 micrómetros. La GPU está alineada por encima de estos, pulsado, y calentado. Este proceso bien establecido, llamado unión por compresión térmica, hace que los pilares de cobre se fusionen con las interconexiones de cobre de la GPU. "
Su trabajo generó comentarios favorables. Tyson lo calificó como un movimiento valiente pero posiblemente oportuno para la industria.
¿Que sigue? El equipo presentará sus hallazgos en el Simposio Internacional IEEE sobre Arquitectura de Computadoras de Alto Rendimiento. El evento es del 16 al 20 de febrero en Washington DC.
© 2019 Science X Network