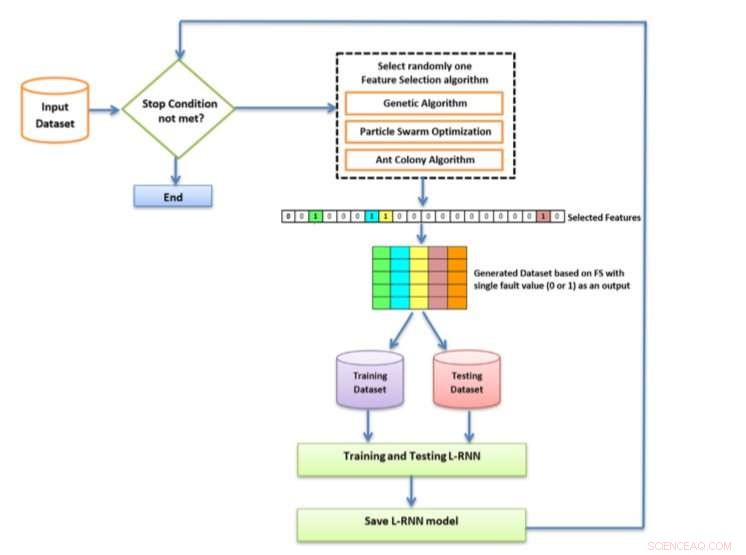
Un diagrama pictórico de la metodología propuesta. Crédito:Turabieh, Mafarja y Li.
Investigadores de la Universidad de Taif, Birzeit University y RMIT University han desarrollado un nuevo enfoque para la predicción de fallas de software (SFP), que aborda algunas de las limitaciones de las técnicas de SFP de aprendizaje automático existentes. Su enfoque emplea la selección de características (FS) para mejorar el rendimiento de una red neuronal recurrente en capas (L-RNN), que se utiliza como herramienta de clasificación para SFP.
La predicción de fallas de software (SFP) es el proceso de predecir módulos que son propensos a fallas en software recientemente desarrollado. Predecir fallas en los componentes de software antes de que se entreguen al usuario final es de vital importancia, ya que puede ahorrar tiempo, esfuerzo e inconvenientes asociados con la identificación y el tratamiento de estos problemas en una etapa posterior.
En años recientes, técnicas de aprendizaje automático como redes neuronales, Regresión logística, Las máquinas de vectores de soporte y los clasificadores de conjuntos han demostrado ser muy eficaces para abordar la SFP. Sin embargo, debido a la gran cantidad de datos que se pueden obtener mediante la extracción de repositorios históricos de software, es posible encontrar características que no están relacionadas con las fallas. A veces, esto puede inducir a error al algoritmo de aprendizaje, consecuentemente disminuyendo su rendimiento.
La selección de funciones (FS) es una técnica que puede ayudar a eliminar estas funciones no relacionadas sin afectar el rendimiento del algoritmo de aprendizaje automático. En el aprendizaje automático, La selección de características implica seleccionar un subconjunto de características relevantes (es decir, predictores) para usar en un modelo en particular. FS puede reducir la dimensionalidad de los datos; eliminar datos irrelevantes y redundantes.
En su papel publicado en Sistemas Expertos con Aplicaciones , el equipo de investigación de la Universidad de Taif, Birzeit University y RMIT University propusieron un nuevo enfoque de FS para mejorar el rendimiento de una red neuronal recurrente en capas (L-RNN) para SFP. Los investigadores emplearon tres algoritmos de envoltura FS diferentes de forma iterativa:algoritmo genético binario (BGA), optimización de enjambre de partículas binarias (BPSO), y optimización de colonias de hormigas binarias (BACO).
"Hemos propuesto un algoritmo de selección de características iterado con una red neuronal recurrente en capas para resolver el problema de predicción de fallas de software, "escribieron los investigadores en su artículo." El algoritmo propuesto es capaz de seleccionar las métricas de software más importantes utilizando diferentes algoritmos de selección de características. El proceso de clasificación se lleva a cabo mediante una red neuronal recurrente en capas ".
Los investigadores evaluaron su enfoque en 19 proyectos de software del mundo real del repositorio PROMISE y compararon sus resultados con los obtenidos utilizando otros enfoques de vanguardia. incluyendo Naïve Bayes (NB), redes neuronales artificiales (ANN), regresión logística (LR), los k vecinos más cercanos (k-NN) y los árboles de decisión C4.5. Su enfoque superó a todos los demás métodos existentes, logrando una tasa de clasificación promedio de 0.8358 en todos los conjuntos de datos.
"Los resultados obtenidos respaldan nuestra afirmación de la importancia de la selección de características en la construcción de un clasificador de alta calidad en lugar de utilizar un conjunto fijo de características o todas las características, ", explicaron los investigadores en su artículo." Para el trabajo futuro, planeamos investigar el desempeño de diferentes clasificadores, como la programación genética, para construir un modelo de computadora que sea capaz de predecir fallas en base a métricas seleccionadas ".
© 2019 Science X Network