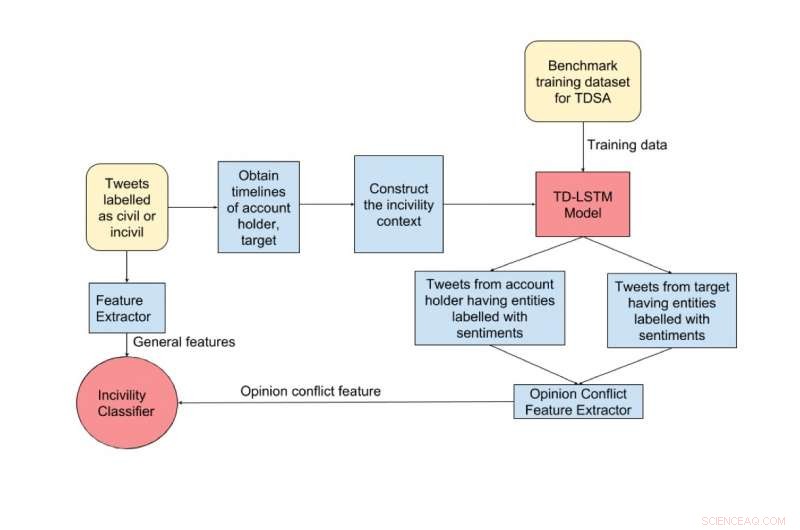
Esquema de los pasos para la detección de incivilidad. Los bloques de color amarillo representan entradas, los bloques de color rojo representan los clasificadores y los bloques de color azul representan los pasos intermedios. Crédito:Maity et al.
Investigadores de la Universidad Northwestern, Universidad McGill, y el Instituto Indio de Tecnología Kharagpur han desarrollado recientemente un modelo de red neuronal convolucional (CNN) a nivel de personaje que podría ayudar a detectar publicaciones abusivas en Twitter. Se descubrió que este modelo supera a varios métodos de referencia, logrando una precisión del 93,3 por ciento.
En años recientes, el comportamiento abusivo en las plataformas en línea ha aumentado exponencialmente, particularmente en Twitter. Por lo tanto, las empresas de redes sociales buscan nuevos métodos efectivos para identificar este comportamiento con el fin de intervenir y evitar que cause daños graves.
"Gorjeo, que inicialmente se concibió como una 'plaza de la ciudad electrónica, 'se está convirtiendo en un mosh pit, "Animesh Mukherjee, uno de los investigadores que realizó el estudio, dicho Tech Xplore . "Un número creciente de ciberagresiones, Todos los días se denuncian casos de ciberacoso e incivilidad, muchos de los cuales afectan gravemente a los usuarios. De hecho, esta es una de las principales razones por las que Twitter está perdiendo su base de seguidores activos ".
El contenido en línea puede difundirse rápidamente y llegar a un público muy amplio, por lo que los casos de abuso en línea a menudo se prolongan durante largos períodos de tiempo con efectos muy perjudiciales. La víctima o víctimas, así como otros transeúntes sensibles, podría terminar leyendo las palabras del delincuente innumerables veces antes de que finalmente desaparezcan de Twitter. Por eso es importante que las plataformas de redes sociales detecten este contenido de forma eficaz y rápida. realizar intervenciones oportunas para eliminarlo.
"Nos propusimos desarrollar un mecanismo que pueda detectar automáticamente los tweets descorteses de forma temprana, antes de que puedan causar daños graves, "Dijo Mukherjee." Observamos que la mayoría de las veces, una víctima / objetivo es atacada después de expresar fuertes sentimientos hacia ciertas entidades nombradas. Esto nos llevó a la idea central de aprovechar los conflictos de opinión para detectar tweets descorteses ".
Mukherjee y sus colegas se dieron cuenta de que las publicaciones abusivas a menudo se correlacionan con diferencias de opinión entre el delincuente y el objetivo. particularmente opiniones sobre una figura o entidad pública de renombre. Por lo tanto, incorporaron información de sentimiento específica de la entidad en su modelo de CNN, esperando que esto mejore su desempeño en la detección de contenido abusivo.

En el ejemplo de contexto de descortesía que se cita a continuación, observamos que el objetivo tuitea positivamente sobre Donald Trump y la economía estadounidense. Sin embargo, el delincuente (titular de la cuenta) tuitea negativamente sobre Trump y positivamente sobre el presidente Obama. Podemos observar que existe un conflicto de opinión entre el objetivo y el titular de la cuenta, ya que los sentimientos expresados hacia la entidad denominada común Donald Trump son opuestos. Pasando por todo el intercambio de mensajes, Nos encontramos con que este conflicto de opinión eventualmente conduce a una publicación descortés. Crédito:Maity et al.
"El nivel de carácter CNN intenta extraer automáticamente patrones de tweets descorteses que los distinguen de otros tweets, "Pawan Goyal, otro investigador que realizó el estudio, le dijo a Tech Xplore. "También optamos por utilizar la incrustación a nivel de personaje, en lugar de incrustaciones a nivel de palabra. Como los tweets suelen ser pequeños, solo contienen unas pocas palabras, y tienen muchas variaciones ortográficas, los modelos a nivel de carácter resultan más robustos que los modelos a nivel de palabra ".
Este modelo de CNN a nivel de personaje superó al mejor método de referencia en un 4,9 por ciento, logrando una precisión del 93,3 por ciento en la detección de tweets descorteses. Los investigadores también llevaron a cabo un análisis post-hoc, echar un vistazo más de cerca a los aspectos de comportamiento de los delincuentes y las víctimas en Twitter, con la esperanza de comprender mejor los incidentes de incivilidad.
Este análisis reveló que una parte considerable de los usuarios eran delincuentes reincidentes que habían acosado a los objetivos más de 10 veces. Similar, algunos objetivos habían sido acosados por diferentes delincuentes en distintas ocasiones. "El hallazgo más interesante de este estudio es que los conflictos de opinión se correlacionan fuertemente con el comportamiento descortés en Twitter, ", Dijo Mukherjee." Esta característica única vinculada con el modelo neuronal profundo basado en char-CNN puede ser muy eficaz en la identificación temprana de tweets descorteses ".
En el futuro, el modelo de CNN ideado por Mukherjee y sus colegas podría ayudar a contrarrestar y reducir el contenido abusivo en Twitter. Los investigadores ahora están tratando de desarrollar modelos similares para detectar el discurso de odio en Twitter. así como en otras plataformas de redes sociales.
"Mientras tanto, también estamos estudiando cómo se propaga el discurso de odio en las redes sociales, además de investigar cómo los diferentes métodos para contrarrestar la incitación al odio podrían ayudar a abordar este perverso fenómeno en línea, "Dijo Mukherjee.
© 2018 Tech Xplore