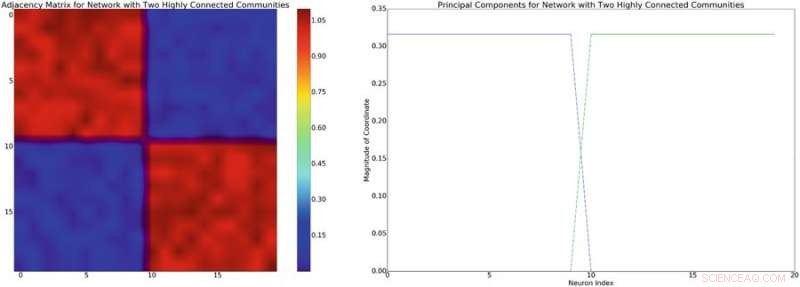
Izquierda:ejemplo de una matriz de adyacencia con una estructura diagonal de bloques aproximada. Suponiendo un modelo de mezcla lineal de interacciones neuronales, esta estructura de red inducirá una covarianza diagonal de aproximadamente bloques de estructura similar. Derecha:los componentes principales asociados con la matriz de adyacencia de la izquierda. Crédito:Mitchell &Petzold
Brian Mitchell y Linda Petzold, dos investigadores de la Universidad de California, han aplicado recientemente el aprendizaje de refuerzo profundo sin modelos a modelos de dinámica neuronal, logrando resultados muy prometedores.
El aprendizaje por refuerzo es un área del aprendizaje automático inspirada en la psicología conductista que entrena algoritmos para completar tareas particulares de manera efectiva. utilizando un sistema basado en recompensas y castigos. Un hito destacado en esta área ha sido el desarrollo de Deep-Q-Network (DQN), que se usó inicialmente para entrenar una computadora para jugar juegos de Atari.
El aprendizaje por refuerzo sin modelos se ha aplicado a una variedad de problemas, pero generalmente no se usa DQN. La razón principal de esto es que DQN puede proponer un número limitado de acciones, mientras que los problemas físicos generalmente requieren un método que pueda proponer un continuo de acciones.
Mientras lee la literatura existente sobre control neuronal, Mitchell y Petzold notaron el uso generalizado de un paradigma clásico para resolver problemas de control neuronal con estrategias de aprendizaje automático. Primero, el ingeniero y el experimentador acuerdan el objetivo y el diseño de su estudio. Luego, este último ejecuta el experimento y recopila datos, que luego será analizado por el ingeniero y utilizado para construir un modelo del sistema de interés. Finalmente, el ingeniero desarrolla un controlador para el modelo y el dispositivo implementa este controlador.
Resultados del experimento que controla la oscilación en el espacio de fase definido por un solo componente principal. El primer gráfico de la parte superior es un gráfico de la entrada en la celda accionada a lo largo del tiempo; el segundo gráfico de la parte superior es un gráfico de los picos de toda la red, donde diferentes colores corresponden a diferentes celdas; el tercer gráfico de la parte superior corresponde al potencial de membrana de cada célula a lo largo del tiempo; el cuarto de la gráfica superior muestra la oscilación objetivo; el gráfico inferior muestra la oscilación observada. La política, a pesar de entregar información a una sola celda, es capaz de inducir aproximadamente la oscilación objetivo en el espacio de fase observado. Crédito:Mitchell &Petzold 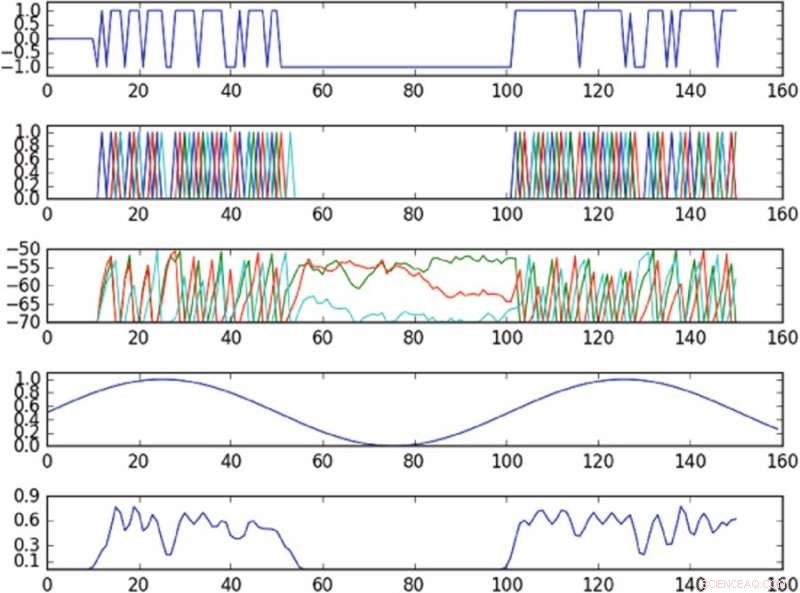
Los investigadores adaptaron un método de aprendizaje por refuerzo sin modelo llamado "gradientes de política deterministas profundos" (DDPG) y lo aplicaron a modelos de dinámica neuronal de bajo y alto nivel. Eligieron específicamente DDPG porque ofrece un marco muy flexible, que no requiere que el usuario modele la dinámica del sistema.
Investigaciones recientes han descubierto que los métodos sin modelos generalmente necesitan demasiada experimentación con el medio ambiente, dificultando su aplicación a problemas más prácticos. Sin embargo, Los investigadores encontraron que su enfoque sin modelos funcionaba mejor que los métodos actuales basados en modelos y era capaz de resolver problemas de dinámica neuronal más difíciles. como el control de trayectorias a través de un espacio de fase latente de una red de neuronas infraactivadas.
"Para los problemas que consideramos en este documento, Los enfoques sin modelos fueron bastante eficientes y no requirieron mucha experimentación en absoluto, sugiriendo que para problemas neuronales, Los controladores de última generación son más útiles en la práctica de lo que la gente podría haber pensado, "dijo Mitchell.
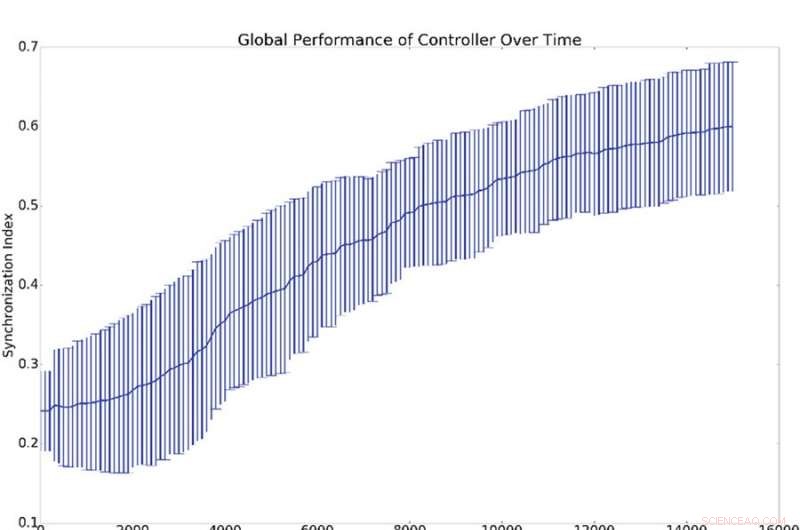
Resumen de resultados de 10 experimentos de sincronización. (a) Representa la desviación media y estándar de la sincronización global, (es decir, q de la ecuación 16), contra el número de períodos de entrenamiento del controlador. (b) Muestra histogramas que demuestran el nivel de sincronización de todos los osciladores de red con el oscilador de referencia (es decir, qi de la ecuación 16). Es decir, un punto en las curvas azul o verde demuestra la probabilidad de tener un valor dado para qi. El histograma azul muestra recuentos antes del entrenamiento, mientras que el histograma verde muestra recuentos después del entrenamiento. La sincronización media con la referencia, qi, es mucho más alto que la sincronización global, q, lo cual se explica por el hecho de que la sincronización con la referencia es más fácil de inducir que la sincronización global. Crédito:Mitchell &Petzold
Mitchell y Petzold llevaron a cabo su estudio como una simulación, por lo tanto, es necesario considerar importantes aspectos prácticos y de seguridad antes de que su método pueda introducirse en entornos clínicos. Investigación adicional que incorpore modelos en enfoques sin modelos, o que impone límites a los controladores sin modelo, podría ayudar a mejorar la seguridad antes de que estos métodos entren en entornos clínicos.
En el futuro, los investigadores también planean investigar cómo los sistemas neuronales se adaptan al control. Los cerebros humanos son órganos muy dinámicos que se adaptan a su entorno y cambian en respuesta a la estimulación externa. Esto podría provocar una competencia entre el cerebro y el controlador, particularmente cuando sus objetivos no están alineados.
"En muchos casos, queremos que el controlador gane y el diseño de controladores que siempre ganen es un problema importante e interesante, "dijo Mitchell." Por ejemplo, en el caso de que el tejido que se está controlando sea una región enferma del cerebro, esta región puede tener una cierta progresión que el controlador está tratando de corregir. En muchas enfermedades, esta progresión puede resistir el tratamiento (por ejemplo, un tumor que se adapta para expulsar la quimioterapia es un ejemplo canónico), pero los enfoques actuales sin modelos no se adaptan bien a este tipo de cambios. Mejorar los controladores sin modelos para manejar mejor la adaptación por parte del cerebro es una dirección interesante que estamos analizando ".
La investigación se publica en Informes científicos .
© 2018 Tech Xplore