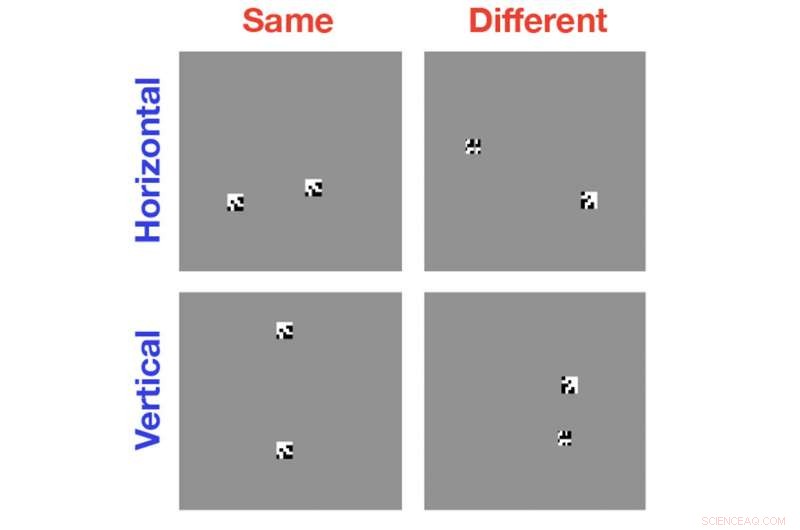
Las computadoras son excelentes para clasificar imágenes por los objetos que se encuentran con ellas, pero son sorprendentemente malos para descubrir cuándo dos objetos en una sola imagen son iguales o diferentes entre sí. Una nueva investigación ayuda a mostrar por qué esa tarea es tan difícil para los algoritmos modernos de visión por computadora. Crédito:Laboratorio Serre / Universidad Brown
Los algoritmos de visión por computadora han avanzado mucho en la última década. Se ha demostrado que son tan buenos o mejores que las personas en tareas como clasificar las razas de perros o gatos, y tienen la notable capacidad de identificar rostros específicos entre un mar de millones.
Pero la investigación realizada por científicos de la Universidad de Brown muestra que las computadoras fallan miserablemente en una clase de tareas con las que incluso los niños pequeños no tienen problemas:determinar si dos objetos en una imagen son iguales o diferentes. En un artículo presentado la semana pasada en la reunión anual de la Cognitive Science Society, El equipo de Brown arroja luz sobre por qué las computadoras son tan malas en este tipo de tareas y sugiere vías hacia sistemas de visión por computadora más inteligentes.
"Hay mucho entusiasmo por lo que la visión por computadora ha podido lograr, y comparto mucho de eso, "dijo Thomas Serre, profesor asociado de cognitiva, ciencias lingüísticas y psicológicas en Brown y el autor principal del artículo. "Pero creemos que trabajando para comprender las limitaciones de los sistemas de visión por computadora actuales como lo hemos hecho aquí, realmente podemos avanzar hacia lo nuevo, sistemas mucho más avanzados en lugar de simplemente ajustar los sistemas que ya tenemos ".
Para el estudio, Serre y sus colegas utilizaron algoritmos de visión por computadora de última generación para analizar imágenes simples en blanco y negro que contienen dos o más formas generadas al azar. En algunos casos, los objetos eran idénticos; a veces eran iguales pero con un objeto girado en relación con el otro; a veces los objetos eran completamente diferentes. Se pidió a la computadora que identificara la relación igual o diferente.
El estudio mostró que, incluso después de cientos de miles de ejemplos de formación, los algoritmos no fueron mejores que la posibilidad de reconocer la relación apropiada. La pregunta, luego, Por eso estos sistemas son tan malos en esta tarea.
Serre y sus colegas tenían la sospecha de que tenía algo que ver con la incapacidad de estos algoritmos de visión por computadora para individualizar objetos. Cuando las computadoras miran una imagen, en realidad, no pueden saber dónde se detiene un objeto de la imagen y el fondo, u otro objeto, comienza. Solo ven una colección de píxeles que tienen patrones similares a las colecciones de píxeles que han aprendido a asociar con ciertas etiquetas. Eso funciona bien para problemas de identificación o categorización, pero se desmorona al intentar comparar dos objetos.
Para mostrar que esta era la razón por la que los algoritmos se estaban descomponiendo, Serre y su equipo realizaron experimentos que aliviaron a la computadora de tener que individualizar objetos por sí misma. En lugar de mostrar a la computadora dos objetos en la misma imagen, los investigadores mostraron a la computadora los objetos uno a la vez en imágenes separadas. Los experimentos mostraron que los algoritmos no tenían problemas para aprender una relación igual o diferente siempre que no tuvieran que ver los dos objetos en la misma imagen.
La fuente del problema en la individualización de objetos, Serre dice, es la arquitectura de los sistemas de aprendizaje automático que impulsan los algoritmos. Los algoritmos utilizan redes neuronales convolucionales, capas de unidades de procesamiento conectadas que imitan libremente las redes de neuronas del cerebro. Una diferencia clave con el cerebro es que las redes artificiales son exclusivamente "feed-forward", lo que significa que la información tiene un flujo unidireccional a través de las capas de la red. No es así como funciona el sistema visual en humanos, según Serre.
"Si nos fijamos en la anatomía de nuestro propio sistema visual, encuentra que hay muchas conexiones recurrentes, donde la información va de un área visual superior a un área visual inferior y regresa, "Dijo Serre.
Si bien no está claro exactamente qué hacen esos comentarios, Serre dice, es probable que tengan algo que ver con nuestra capacidad para prestar atención a ciertas partes de nuestro campo visual y hacer representaciones mentales de objetos en nuestra mente.
"Es de suponer que la gente atiende a un objeto, construir una representación de características que esté ligada a ese objeto en su memoria de trabajo, "Dijo Serre." Luego cambian su atención a otro objeto. Cuando ambos objetos están representados en la memoria de trabajo, su sistema visual es capaz de hacer comparaciones como iguales o diferentes ".
Serre y sus colegas plantean la hipótesis de que la razón por la que las computadoras no pueden hacer algo así es porque las redes neuronales de alimentación hacia adelante no permiten el tipo de procesamiento recurrente requerido para esta individuación y representación mental de los objetos. Podría ser, Serre dice, que hacer que la visión por computadora sea más inteligente requerirá redes neuronales que se aproximen más a la naturaleza recurrente del procesamiento visual humano.