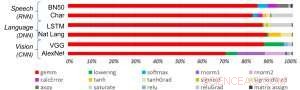
Figura 1. Los algoritmos de aprendizaje profundo se componen de un espectro de operaciones. Aunque la multiplicación de matrices es dominante, optimizar la eficiencia del rendimiento mientras se mantiene la precisión requiere que la arquitectura central respalde de manera eficiente todas las funciones auxiliares. Crédito:IBM
Los avances recientes en el aprendizaje profundo y el crecimiento exponencial en el uso del aprendizaje automático en los dominios de aplicaciones han hecho que la aceleración de la IA sea de vital importancia. IBM Research ha estado construyendo una línea de aceleradores de hardware de IA para satisfacer esta necesidad. En el Simposio de circuitos VLSI 2018, presentamos un bloque de construcción del núcleo del acelerador de múltiples TeraOPS que se puede escalar en una amplia gama de sistemas de hardware de IA. Este núcleo de inteligencia artificial digital presenta una arquitectura paralela que garantiza una utilización muy alta y motores de cómputo eficientes que aprovechan cuidadosamente la precisión reducida.
La informática aproximada es un principio central de nuestro enfoque para aprovechar "la física de la IA", en el que se logran ganancias informáticas de alta eficiencia energética mediante arquitecturas especialmente diseñadas, inicialmente usando cálculos digitales y luego incluyendo computación analógica y en memoria.
Históricamente, el cálculo se ha basado en aritmética de punto flotante de 64 y 32 bits de alta precisión. Este enfoque ofrece cálculos precisos hasta el enésimo punto decimal, un nivel de precisión crítico para tareas de computación científica como simular el corazón humano o calcular las trayectorias de los transbordadores espaciales. Pero, ¿necesitamos este nivel de precisión para tareas comunes de aprendizaje profundo? ¿Nuestro cerebro requiere una imagen de alta resolución para reconocer a un miembro de la familia? o un gato? Cuando ingresamos un hilo de texto para buscar, ¿Requerimos precisión en la clasificación relativa de los 50, 002 respuesta más útil frente a la 50, 003rd? La respuesta es que muchas tareas, incluidos estos ejemplos, se pueden realizar con cálculo aproximado.
Dado que rara vez se requiere precisión total para cargas de trabajo de aprendizaje profundo comunes, la precisión reducida es una dirección natural. Los bloques de construcción computacionales con motores de precisión de 16 bits son 4 veces más pequeños que los bloques comparables con precisión de 32 bits; Esta ganancia en la eficiencia del área se convierte en un impulso en el rendimiento y la eficiencia energética tanto para el entrenamiento de IA como para las cargas de trabajo de inferencia. Indicado simplemente, en computación aproximada, podemos intercambiar precisión numérica por eficiencia computacional, siempre que también desarrollemos mejoras algorítmicas para mantener la precisión del modelo. Este enfoque también complementa otras técnicas de computación aproximadas, incluido un trabajo reciente que describió enfoques novedosos de compresión de entrenamiento para reducir la sobrecarga de comunicaciones, lo que lleva a una aceleración de 40 a 200 veces con respecto a los métodos existentes.
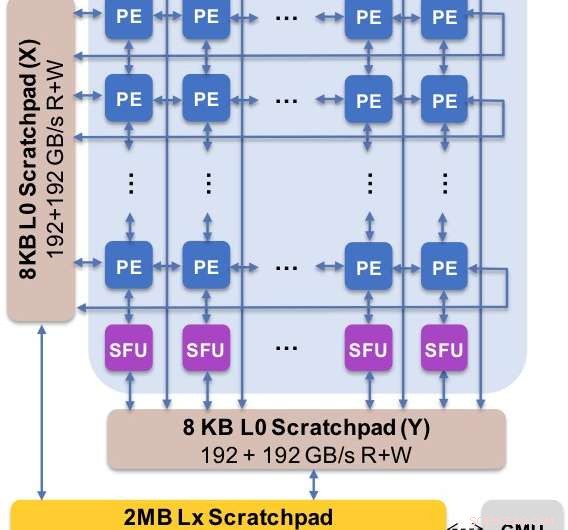
Figura 2. La arquitectura central captura el flujo de datos personalizado con la jerarquía del bloc de notas. El elemento de procesamiento (PE) aprovecha la precisión reducida para las operaciones de multiplicación de matrices y algunas funciones de activación, mientras que las unidades de función especial (SFU) retienen la precisión de coma flotante de 32 bits para las operaciones vectoriales restantes. Crédito:IBM
Presentamos los resultados experimentales de nuestro núcleo de inteligencia artificial digital en el Simposio de circuitos VLSI de 2018. El diseño de nuestro nuevo núcleo se rige por cuatro objetivos:
Nuestra nueva arquitectura se ha optimizado no solo para la multiplicación de matrices y los núcleos convolucionales, que tienden a dominar los cálculos de aprendizaje profundo, pero también un espectro de funciones de activación que son parte de la carga de trabajo computacional del aprendizaje profundo. Es más, nuestra arquitectura ofrece soporte para operaciones convolucionales nativas, permitiendo que las tareas de inferencia y entrenamiento de aprendizaje profundo en imágenes y datos de voz se ejecuten con una eficiencia excepcional en el núcleo.
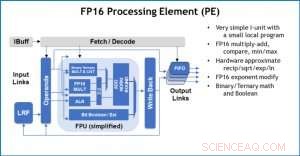
Figura 3. Elemento de procesamiento (PE) con capacidad de punto flotante de 16 bits (FP16) para operaciones de multiplicación de matrices, matemáticas binarias y ternarias, funciones de activación y operaciones booleanas. Crédito:IBM
Como ilustración de cómo se ha optimizado la arquitectura central para una variedad de funciones de aprendizaje profundo, La Figura 1 muestra el desglose de los tipos de operaciones dentro de los algoritmos de aprendizaje profundo en un espectro de dominios de aplicaciones. Los componentes dominantes de multiplicación de matrices se calculan en la arquitectura central mediante el uso de una organización de flujo de datos personalizada de los Elementos de procesamiento que se muestran en las Figuras 2 y 3, donde los cálculos de precisión reducida se pueden explotar de manera eficiente. mientras que las funciones vectoriales restantes (todas las barras que no son rojas en la Figura 1) se ejecutan en los Elementos de procesamiento o en las Unidades de funciones especiales que se muestran en las Figuras 3 o 4, dependiendo de las necesidades de precisión de la función específica.
En el Simposio, mostramos resultados de hardware que confirman que este enfoque de arquitectura única es capaz tanto de entrenamiento como de inferencia y admite modelos en múltiples dominios (por ejemplo, habla, visión, procesamiento natural del lenguaje). Mientras que otros grupos apuntan al "máximo rendimiento" de sus chips de IA especializados, pero tienen niveles de rendimiento sostenidos en una pequeña fracción del pico, nos hemos centrado en maximizar el rendimiento y la utilización sostenidos, ya que el rendimiento sostenido se traduce directamente en experiencia del usuario y tiempos de respuesta.
Nuestro chip de prueba se muestra en la Figura 5. Con este chip de prueba, construido en tecnología 14LPP, hemos demostrado con éxito tanto la formación como la inferencia, en una amplia biblioteca de aprendizaje profundo, ejercitar todas las operaciones comúnmente utilizadas en tareas de aprendizaje profundo, incluyendo multiplicaciones de matrices, convoluciones y diversas funciones de activación no lineales.
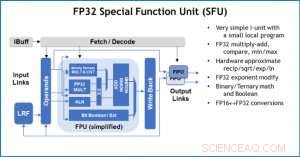
Figura 4. Unidad de función especial (SFU) con coma flotante de 32 bits (FP32) para ciertos cálculos vectoriales. Crédito:IBM
Destacamos la flexibilidad y la capacidad multipropósito del núcleo de IA digital y el soporte nativo para múltiples flujos de datos en el papel VLSI, pero este enfoque es completamente modular. Este núcleo de IA se puede integrar en SoC, CPU, o microcontroladores y se utilizan para entrenamiento, inferencia, o ambos. Los chips que utilizan el núcleo se pueden implementar en el centro de datos o en el borde.
Impulsado por una comprensión fundamental de los algoritmos de aprendizaje profundo en IBM Research, Esperamos que los requisitos de precisión para el entrenamiento y la inferencia continúen escalando, lo que impulsará mejoras de eficiencia cuántica en las arquitecturas de hardware necesarias para la IA. Estén atentos para más investigaciones de nuestro equipo.
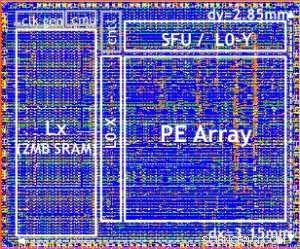
Figura 5. Chip de prueba digital AI Core, basado en tecnología 14LPP, incluyendo puertas de 5.75M, 1,00 chanclas, 16KB L0 and 16KB of PE local registers. This chip was used to demonstrate both training and inferencing, across a wide range of AI workloads. Crédito:IBM