Los resultados de un análisis de redes neuronales artificiales (ANN) pueden no ser confiables para moléculas que son demasiado diferentes de aquellas en las que se entrenó la ANN. Las nubes negras que se muestran aquí cubren los complejos de metales de transición en el conjunto de datos cuyas representaciones numéricas están demasiado lejos de las de los complejos de entrenamiento para ser consideradas confiables. Crédito:Instituto de Tecnología de Massachusetts
En años recientes, El aprendizaje automático ha demostrado ser una herramienta valiosa para identificar nuevos materiales con propiedades optimizadas para aplicaciones específicas. Trabajando con grandes conjuntos de datos bien definidos, Las computadoras aprenden a realizar una tarea analítica para generar una respuesta correcta y luego usan la misma técnica en un conjunto de datos desconocido.
Si bien ese enfoque ha guiado el desarrollo de nuevos materiales valiosos, han sido principalmente compuestos orgánicos, señala Heather Kulik Ph.D. '09, un profesor asistente de ingeniería química. Kulik se centra en cambio en compuestos inorgánicos, en particular, los basados en metales de transición, una familia de elementos (incluidos el hierro y el cobre) que tienen propiedades únicas y útiles. En esos compuestos, conocidos como complejos de metales de transición, el átomo de metal se encuentra en el centro con brazos unidos químicamente, o ligandos, hecho de carbono, hidrógeno, nitrógeno, o átomos de oxígeno que irradian hacia afuera.
Los complejos de metales de transición ya desempeñan funciones importantes en áreas que van desde el almacenamiento de energía hasta la catálisis para la fabricación de productos químicos finos, por ejemplo, para productos farmacéuticos. Pero Kulik cree que el aprendizaje automático podría ampliar aún más su uso. En efecto, su grupo ha estado trabajando no solo para aplicar el aprendizaje automático a los inorgánicos, una empresa novedosa y desafiante, sino también para utilizar la técnica para explorar nuevos territorios. "Estábamos interesados en comprender hasta dónde podíamos impulsar nuestros modelos para hacer descubrimientos, para hacer predicciones sobre compuestos que no se habían visto antes". "dice Kulik.
Sensores y computadoras
Durante los últimos cuatro años, Kulik y Jon Paul Janet, un estudiante de posgrado en ingeniería química, se han centrado en los complejos de metales de transición con "espín", una propiedad de la mecánica cuántica de los electrones. Generalmente, los electrones ocurren en pares, uno con giro hacia arriba y el otro con giro hacia abajo, por lo que se cancelan entre sí y no hay giro neto. Pero en un metal de transición los electrones pueden desaparecer, y el giro neto resultante es la propiedad que hace complejos inorgánicos de interés, dice Kulik. "Adaptar la falta de apareamiento de los electrones nos da una perilla única para adaptar las propiedades".
Un complejo dado tiene un estado de giro preferido. Pero agregue algo de energía, digamos, de la luz o el calor, y puede cambiar al otro estado. En el proceso, puede presentar cambios en las propiedades de la macroescala, como el tamaño o el color. Cuando la energía necesaria para causar el giro, llamada energía de división de espín, es cercana a cero, el complejo es un buen candidato para su uso como sensor, o quizás como componente fundamental en una computadora cuántica.
Los químicos conocen muchas combinaciones de metal-ligando con energías de división de espín cercanas a cero, haciéndolos potenciales complejos "spin-crossover" (SCO) para tales aplicaciones prácticas. Pero el conjunto completo de posibilidades es vasto. La energía de división del espín de un complejo de metal de transición está determinada por los ligandos que se combinan con un metal dado, y hay ligandos casi infinitos entre los que elegir. El desafío es encontrar combinaciones novedosas con la propiedad deseada para convertirse en OCS, sin tener que recurrir a millones de pruebas de prueba y error en un laboratorio.
Traducir moléculas a números
La forma estándar de analizar la estructura electrónica de las moléculas es utilizando un método de modelado computacional llamado teoría funcional de la densidad, o DFT. Los resultados de un cálculo de DFT son bastante precisos, especialmente para sistemas orgánicos, pero realizar un cálculo para un solo compuesto puede llevar horas. o incluso días. A diferencia de, Se puede entrenar una herramienta de aprendizaje automático llamada red neuronal artificial (ANN) para realizar el mismo análisis y luego hacerlo en solo unos segundos. Como resultado, Las RNA son mucho más prácticas para buscar posibles OCS en el enorme espacio de los complejos factibles.

Este gráfico representa una muestra de un complejo de metales de transición. Un complejo de metal de transición consiste en un átomo central de metal de transición (naranja) rodeado por una serie de moléculas orgánicas unidas químicamente en estructuras conocidas como ligandos. Crédito:Instituto de Tecnología de Massachusetts
Debido a que una ANN requiere una entrada numérica para funcionar, El primer desafío de los investigadores fue encontrar una manera de representar un complejo de metal de transición dado como una serie de números, cada uno describiendo una propiedad seleccionada. Existen reglas para definir representaciones de moléculas orgánicas, donde la estructura física de una molécula dice mucho sobre sus propiedades y comportamiento. Pero cuando los investigadores siguieron esas reglas para los complejos de metales de transición, no funcionó. "El enlace metal-orgánico es muy complicado de conseguir, ", dice Kulik." Hay propiedades únicas de la unión que son más variables. Hay muchas más formas en las que los electrones pueden elegir para formar un enlace ”. Así que los investigadores necesitaban crear nuevas reglas para definir una representación que fuera predictiva en química inorgánica.
Usando el aprendizaje automático, exploraron varias formas de representar un complejo de metales de transición para analizar la energía de división del espín. Los resultados fueron mejores cuando la representación dio el mayor énfasis a las propiedades del centro metálico y la conexión metal-ligando y menos énfasis a las propiedades de los ligandos más alejados. Curiosamente, sus estudios demostraron que las representaciones que daban un énfasis más equitativo en general funcionaban mejor cuando el objetivo era predecir otras propiedades, como la longitud del enlace ligando-metal o la tendencia a aceptar electrones.
Probando la ANN
Como prueba de su enfoque, Kulik y Janet, asistidos por Lydia Chan, un pasante de verano de Troy High School en Fullerton, California:definió un conjunto de complejos de metales de transición basados en cuatro metales de transición:cromo, manganeso, planchar, y cobalto, en dos estados de oxidación con 16 ligandos (cada molécula puede tener hasta dos). Al combinar esos bloques de construcción, crearon un "espacio de búsqueda" de 5, 600 complejos, algunos de ellos familiares y bien estudiados, y algunos de ellos totalmente desconocidos.
En trabajos anteriores, los investigadores habían entrenado a una ANN en miles de compuestos que eran bien conocidos en la química de los metales de transición. Para probar la capacidad de la ANN capacitada para explorar un nuevo espacio químico para encontrar compuestos con las propiedades específicas, intentaron aplicarlo a la piscina de 5, 600 complejos, 113 de los cuales había visto en el estudio anterior.
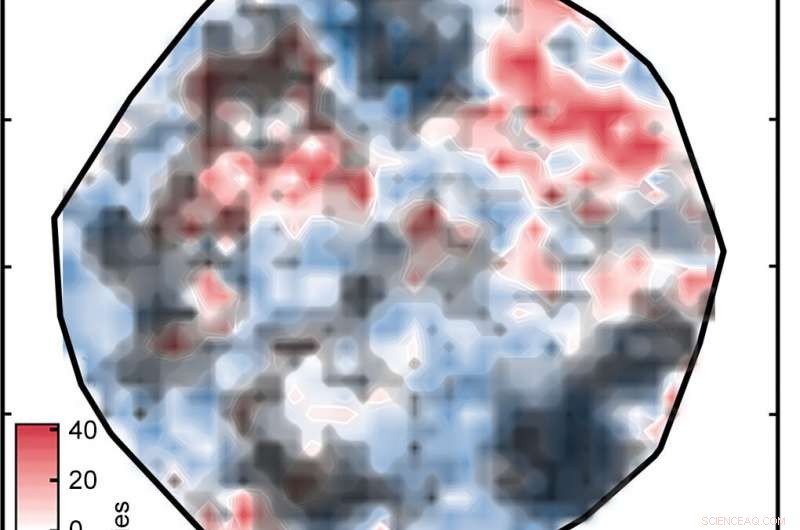
El resultado fue el gráfico etiquetado como "Figura 1" en la presentación de diapositivas de arriba, que clasifica los complejos en una superficie determinada por la ANN. Las regiones blancas indican complejos con energías de división de espín dentro de 5 kilocalorías por mol de cero, lo que significa que son candidatos potencialmente buenos para OCS. Las regiones roja y azul representan complejos con energías de división de espín demasiado grandes para ser útiles. Los diamantes verdes que aparecen en el recuadro muestran complejos que tienen centros de hierro y ligandos similares; en otras palabras, compuestos relacionados cuyas energías de cruce de espín deberían ser similares. Su aparición en la misma región de la trama es evidencia de la buena correspondencia entre la representación de los investigadores y las propiedades clave del complejo.
Pero hay una trampa:no todas las predicciones de división de espín son precisas. Si un complejo es muy diferente de aquellos en los que se entrenó la red, el análisis ANN puede no ser confiable, un problema estándar cuando se aplican modelos de aprendizaje automático al descubrimiento en ciencia de materiales o química, señala Kulik. Usando un enfoque que parecía exitoso en su trabajo anterior, los investigadores compararon las representaciones numéricas de los complejos de entrenamiento y prueba y descartaron todos los complejos de prueba donde la diferencia era demasiado grande.
Centrándonos en las mejores opciones
Realizando el análisis ANN de los 5, 600 complejos tomaron solo una hora. Pero en el mundo real el número de complejos a explorar podría ser miles de veces mayor, y cualquier candidato prometedor requeriría un cálculo DFT completo. Por lo tanto, los investigadores necesitaban un método para evaluar un gran conjunto de datos para identificar cualquier candidato inaceptable incluso antes del análisis de ANN. Con ese fin, desarrollaron un algoritmo genético, un enfoque inspirado en la selección natural, para puntuar los complejos individuales y descartar los que se consideraban inadecuados.
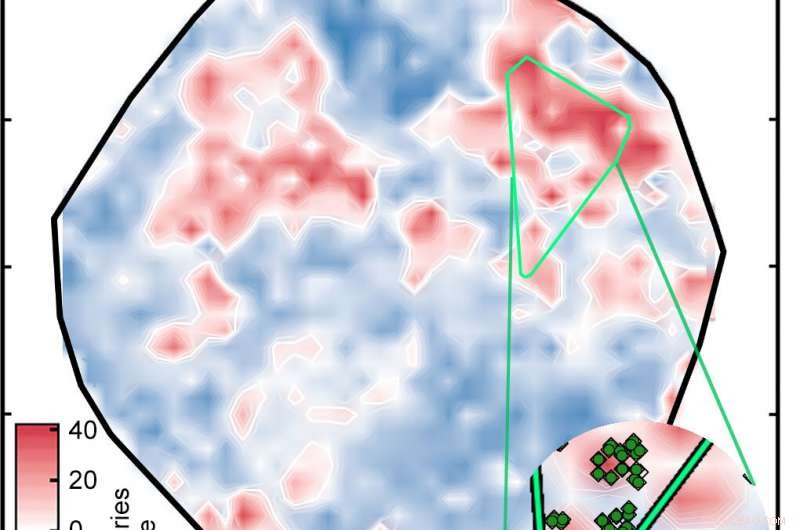
Una red neuronal artificial previamente entrenada en compuestos bien conocidos analizados 5, 600 complejos de metales de transición para identificar posibles complejos de cruce de espín. El resultado fue esta trama, en el que los complejos se colorean en función de su energía de división de espín en kilocalorías por mol (kcal / mol). En candidatos prometedores, esa energía está dentro de 5 kcal / mol de cero. Los diamantes de color verde brillante en el recuadro son complejos relacionados. Crédito:Instituto de Tecnología de Massachusetts
Para preseleccionar un conjunto de datos, el algoritmo genético primero selecciona al azar 20 muestras del conjunto completo de complejos. A continuación, asigna una puntuación de "aptitud" a cada muestra en función de tres medidas. Primero, ¿Es su energía de cruce de giro lo suficientemente baja como para que sea un buen SCO? Descubrir, la red neuronal evalúa cada uno de los 20 complejos. Segundo, ¿El complejo está demasiado lejos de los datos de entrenamiento? Si es así, la energía de cruce de espín de la ANN puede ser inexacta. Y finalmente, ¿El complejo está demasiado cerca de los datos de entrenamiento? Si es así, los investigadores ya han realizado un cálculo de DFT en una molécula similar, por lo que al candidato no le interesa la búsqueda de nuevas opciones.
Sobre la base de su evaluación en tres partes de los primeros 20 candidatos, el algoritmo genético descarta las opciones no aptas y guarda al más apto para la siguiente ronda. Para asegurar la diversidad de los compuestos guardados, el algoritmo pide que algunos de ellos muten un poco. A un complejo se le puede asignar un nuevo, ligando seleccionado al azar, o dos complejos prometedores pueden intercambiar ligandos. Después de todo, si un complejo se ve bien, entonces, algo muy similar podría ser incluso mejor, y el objetivo aquí es encontrar candidatos novedosos. El algoritmo genético luego agrega algunos nuevos, complejos elegidos al azar para completar el segundo grupo de 20 y realiza su siguiente análisis. Al repetir este proceso un total de 21 veces, produce 21 generaciones de opciones. De este modo procede a través del espacio de búsqueda, permitir que los candidatos más aptos sobrevivan y se reproduzcan, y los incapaces de morir.
Realizando el análisis de 21 generaciones en el total de 5, Un conjunto de datos de 600 complejos requirió poco más de cinco minutos en una computadora de escritorio estándar, y arrojó 372 pistas con una buena combinación de alta diversidad y confianza aceptable. Luego, los investigadores usaron DFT para examinar 56 complejos elegidos al azar entre esos cables, y los resultados confirmaron que dos tercios de ellos podrían ser buenas OCS.
Si bien una tasa de éxito de dos tercios puede no parecer muy buena, los investigadores señalan dos puntos. Primero, su definición de lo que podría ser un buen OCS era muy restrictiva:para que un complejo sobreviva, su energía de división de giro tenía que ser extremadamente pequeña. Y segundo, dado un espacio de 5, 600 complejos y nada para continuar, ¿Cuántos análisis DFT se necesitarían para encontrar 37 clientes potenciales? Como señala Janet, "No importa cuántos evaluamos con la red neuronal porque es muy barata. Son los cálculos de DFT los que llevan tiempo".
Mejor de todo, el uso de su enfoque permitió a los investigadores encontrar algunos candidatos de OCS no convencionales que no se habrían pensado en base a lo que se ha estudiado en el pasado. "Hay reglas que la gente tiene, heurísticas en la cabeza, sobre cómo construirían un complejo de cruce de espín, ", dice Kulik." Demostramos que se pueden encontrar combinaciones inesperadas de metales y ligandos que normalmente no se estudian, pero que pueden ser prometedoras como candidatos de cruce de espín ".
Compartiendo las nuevas herramientas
Para apoyar la búsqueda mundial de nuevos materiales, los investigadores han incorporado el algoritmo genético y ANN en "molSimplify, "el grupo está en línea, Kit de herramientas de software de código abierto que cualquiera puede descargar y usar para construir y simular complejos de metales de transición. Para ayudar a los usuarios potenciales, el sitio ofrece tutoriales que demuestran cómo utilizar las funciones clave de los códigos de software de fuente abierta. El desarrollo de molSimplify comenzó con la financiación de MIT Energy Initiative en 2014, y todos los estudiantes del grupo de Kulik han contribuido desde entonces.
Los investigadores continúan mejorando su red neuronal para investigar posibles SCO y para publicar versiones actualizadas de molSimplify. Mientras tanto, otros en el laboratorio de Kulik están desarrollando herramientas que pueden identificar compuestos prometedores para otras aplicaciones. Por ejemplo, un área importante de atención es el diseño de catalizadores. La estudiante de posgrado en química Aditya Nandy se está enfocando en encontrar un mejor catalizador para convertir el gas metano en un combustible líquido más fácil de manejar, como el metanol, un problema particularmente desafiante. "Ahora tenemos una molécula externa entrando, y nuestro complejo, el catalizador, tiene que actuar sobre esa molécula para realizar una transformación química que tiene lugar en toda una serie de pasos, ", dice Nandy." El aprendizaje automático será muy útil para descubrir los parámetros de diseño importantes para un complejo de metales de transición que hará que cada paso de ese proceso sea energéticamente favorable ".
Esta historia se vuelve a publicar por cortesía de MIT News (web.mit.edu/newsoffice/), un sitio popular que cubre noticias sobre la investigación del MIT, innovación y docencia.