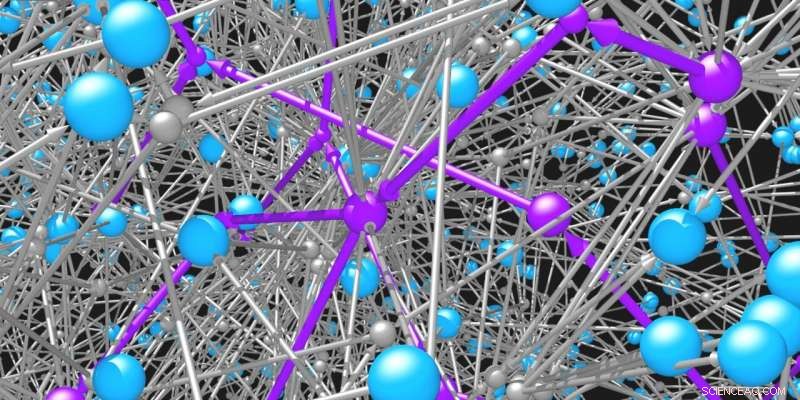
Las moléculas (esferas azules) están conectadas entre sí por las reacciones (esferas grises y flechas) en las que participan. La red de posibles moléculas orgánicas y reacciones es increíblemente vasta. Se necesitan algoritmos de búsqueda inteligente para identificar vías factibles (violeta) para sintetizar las moléculas deseadas. Crédito:Mikolaj Kowalik y Kyle Bishop / Columbia Engineering
Investigadores desde bioquímicos hasta científicos de materiales, Durante mucho tiempo han confiado en la rica variedad de moléculas orgánicas para resolver desafíos urgentes. Algunas moléculas pueden ser útiles en el tratamiento de enfermedades, otros para iluminar nuestras pantallas digitales, otros más para pigmentos, pinturas y plásticos. Las propiedades únicas de cada molécula están determinadas por su estructura, es decir, por la conectividad de sus átomos constituyentes. Una vez que se identifica una estructura prometedora, Queda la difícil tarea de fabricar la molécula objetivo a través de una secuencia de reacciones químicas. Pero cuales?
Los químicos orgánicos generalmente trabajan hacia atrás desde la molécula objetivo hasta los materiales de partida mediante un proceso llamado análisis retrosintético. Durante este proceso, el químico se enfrenta a una serie de decisiones complejas e interrelacionadas. Por ejemplo, de las decenas de miles de reacciones químicas diferentes, ¿Cuál debería elegir para crear la molécula diana? Una vez que se toma esa decisión, puede encontrarse con múltiples moléculas de reactivo necesarias para la reacción. Si estas moléculas no están disponibles para comprar, Entonces, ¿cómo se seleccionan las reacciones adecuadas para producirlas? Elegir inteligentemente qué hacer en cada paso de este proceso es fundamental para navegar por la gran cantidad de caminos posibles.
Los investigadores de Columbia Engineering han desarrollado una nueva técnica basada en el aprendizaje por refuerzo que entrena un modelo de red neuronal para seleccionar correctamente la "mejor" reacción en cada paso del proceso retrosintético. Esta forma de IA proporciona un marco para que los investigadores diseñen síntesis químicas que optimicen los objetivos especificados por el usuario, como el costo de síntesis, la seguridad, y sostenibilidad. El nuevo enfoque publicado el 31 de mayo por Ciencia Central ACS , tiene más éxito (en aproximadamente un 60%) que las estrategias existentes para resolver este desafiante problema de búsqueda.
"El aprendizaje por refuerzo ha creado jugadores de computadora que son mucho mejores que los humanos para jugar videojuegos complejos. ¡Quizás la retrosíntesis no sea diferente! Este estudio nos da la esperanza de que los algoritmos de aprendizaje por refuerzo sean quizás algún día mejores que los jugadores humanos en el 'juego' de retrosíntesis, "dice Alán Aspuru-Guzik, profesor de química e informática en la Universidad de Toronto, que no participó en el estudio.
El equipo enmarcó el desafío de la planificación retrosintética como un juego como el ajedrez y el Go, donde el número combinatorio de opciones posibles es astronómico y el valor de cada elección es incierto hasta que se complete el plan de síntesis y se evalúe su costo. A diferencia de los estudios anteriores que utilizaron funciones de puntuación heurísticas (reglas generales simples) para guiar la planificación retrosintética, Este nuevo estudio utilizó técnicas de aprendizaje por refuerzo para emitir juicios basados en la propia experiencia del modelo neuronal.
"Somos los primeros en aplicar el aprendizaje por refuerzo al problema del análisis retrosintético, "dice Kyle Bishop, profesor asociado de ingeniería química. "Partiendo de un estado de completa ignorancia, donde el modelo no sabe absolutamente nada sobre estrategia y aplica reacciones al azar, el modelo puede practicar y practicar hasta que encuentre una estrategia que supere a una heurística definida por humanos ".
En su estudio, El equipo de Bishop se centró en utilizar el número de pasos de reacción como medida de lo que constituye una vía sintética "buena". Hicieron que su modelo de aprendizaje por refuerzo adaptara su estrategia con este objetivo en mente. Usando experiencia simulada, el equipo entrenó la red neuronal del modelo para estimar el costo de síntesis esperado o el valor de cualquier molécula dada basándose en una representación de su estructura molecular.
El equipo planea explorar diferentes objetivos en el futuro, por ejemplo, entrenar el modelo para minimizar los costos en lugar del número de reacciones, o para evitar moléculas que pudieran resultar tóxicas. Los investigadores también están tratando de reducir el número de simulaciones necesarias para que el modelo aprenda su estrategia. ya que el proceso de formación era bastante costoso computacionalmente.
"Esperamos que nuestro juego de retrosíntesis pronto siga el camino del ajedrez y el Go, en el que los algoritmos autodidactas superan sistemáticamente a los expertos humanos, "Observa el obispo." Y damos la bienvenida a la competencia. Al igual que con los programas de computadora para jugar al ajedrez, la competencia es el motor de las mejoras en el estado de la técnica, y esperamos que otros puedan aprovechar nuestro trabajo para demostrar un desempeño aún mejor ".
El estudio se titula "Aprendizaje de la planificación retrosintética a través de la experiencia simulada".