Muchos estudios científicos no se están demorando en más pruebas. Crédito:Fotografía A y N / Shutterstock.com
En un ensayo de un nuevo fármaco para curar el cáncer, El 44 por ciento de 50 pacientes logró la remisión después del tratamiento. Sin la droga solo el 32 por ciento de los pacientes anteriores hicieron lo mismo. El nuevo tratamiento suena prometedor, pero ¿es mejor que el estándar?
Esa pregunta es dificil por lo que los estadísticos tienden a responder una pregunta diferente. Miran sus resultados y calculan algo llamado valor p. Si el valor p es menor que 0.05, los resultados son "estadísticamente significativos", en otras palabras, Es poco probable que sea causado por una casualidad aleatoria.
El problema es, muchos resultados estadísticamente significativos no se están reproduciendo. Un tratamiento que se muestra prometedor en un ensayo no muestra ningún beneficio en absoluto cuando se administra al siguiente grupo de pacientes. Este problema se ha vuelto tan grave que una revista de psicología prohibió los valores p por completo.
Mis colegas y yo hemos estudiado este problema, y creemos saber qué lo está causando. La barra para reclamar significancia estadística es simplemente demasiado baja.
La mayoría de las hipótesis son falsas
La colaboración de ciencia abierta, una organización sin fines de lucro centrada en la investigación científica, intentó replicar 100 experimentos de psicología publicados. Si bien 97 de los experimentos iniciales informaron hallazgos estadísticamente significativos, sólo 36 de los estudios replicados lo hicieron.
Varios estudiantes de posgrado y yo usamos estos datos para estimar la probabilidad de que un experimento de psicología elegido al azar probara un efecto real. Descubrimos que solo alrededor del 7 por ciento lo hizo. En un estudio similar, la economista Anna Dreber y sus colegas estimaron que solo el 9 por ciento de los experimentos se reproducirían.
Ambos análisis sugieren que solo uno de cada 13 nuevos tratamientos experimentales en psicología, y probablemente muchas otras ciencias sociales, resultará exitoso.
Esto tiene implicaciones importantes al interpretar los valores p, particularmente cuando están cerca de 0.05.
El factor Bayes
Es más probable que los valores de p cercanos a 0,05 se deban a una casualidad aleatoria de lo que la mayoría de la gente cree.
Para entender el problema volvamos a nuestro ensayo imaginario de drogas. Recordar, 22 de cada 50 pacientes con el nuevo fármaco entraron en remisión, en comparación con un promedio de solo 16 de cada 50 pacientes con el tratamiento anterior.
La probabilidad de ver 22 o más éxitos de 50 es 0.05 si el nuevo medicamento no es mejor que el anterior. Eso significa que el valor p para este experimento es estadísticamente significativo. Pero queremos saber si el nuevo tratamiento es realmente una mejora, o si no es mejor que la antigua forma de hacer las cosas.
Descubrir, Necesitamos combinar la información contenida en los datos con la información disponible antes de que se realizara el experimento. o las "probabilidades anteriores". Las probabilidades anteriores reflejan factores que no se miden directamente en el estudio. Por ejemplo, podrían explicar el hecho de que en otros 10 ensayos de fármacos similares, ninguno resultó tener éxito.
Si el nuevo fármaco no es mejor que el antiguo, luego, las estadísticas nos dicen que la probabilidad de ver exactamente 22 de 50 éxitos en esta prueba es 0.0235 - relativamente baja.
¿Qué pasa si el nuevo fármaco es realmente mejor? En realidad, no conocemos la tasa de éxito del nuevo fármaco, pero una buena suposición es que está cerca de la tasa de éxito observada, 22 de 50. Si asumimos que, entonces, la probabilidad de observar exactamente 22 de 50 éxitos es 0,113, aproximadamente cinco veces más probable. (No es casi 20 veces más probable, aunque, como podría adivinar si supiera que el valor p del experimento era 0.05).
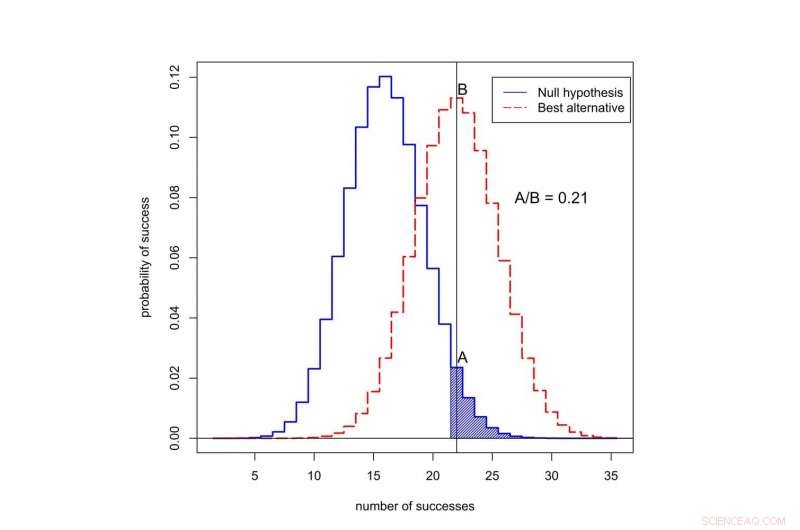
¿Cuál es la probabilidad de observar el éxito en 50 intentos? La curva negra representa probabilidades bajo la "hipótesis nula, 'Cuando el nuevo tratamiento no es mejor que el anterior. La curva roja representa las probabilidades de que el nuevo tratamiento sea mejor. El área sombreada representa el valor p. En este caso, la razón de las probabilidades asignadas a 22 éxitos es A dividido por B, o 0,21. Crédito:Valen Johnson, CC BY-SA
Esta razón de probabilidades se llama factor de Bayes. Podemos usar el teorema de Bayes para combinar el factor de Bayes con las probabilidades anteriores para calcular la probabilidad de que el nuevo tratamiento sea mejor.
Por el valor del argumento, supongamos que solo 1 de cada 13 tratamientos experimentales contra el cáncer resultará exitoso. Eso se acerca al valor que estimamos para los experimentos de psicología.
Cuando combinamos estas probabilidades anteriores con el factor de Bayes, resulta que la probabilidad de que el nuevo tratamiento no sea mejor que el anterior es de al menos 0,71. ¡Pero el valor p estadísticamente significativo de 0.05 sugiere exactamente lo contrario!
Un nuevo enfoque
Esta inconsistencia es típica de muchos estudios científicos. Es particularmente común para valores de p alrededor de 0.05. Esto explica por qué una proporción tan alta de resultados estadísticamente significativos no se replica.
Entonces, ¿cómo debemos evaluar las afirmaciones iniciales de un descubrimiento científico? En septiembre, mis colegas y yo propusimos una nueva idea:solo los valores de p inferiores a 0,005 deben considerarse estadísticamente significativos. Los valores de p entre 0,005 y 0,05 deben llamarse simplemente sugerentes.
En nuestra propuesta, es más probable que se repitan los resultados estadísticamente significativos, incluso después de tener en cuenta las pequeñas probabilidades previas que suelen pertenecer a los estudios en lo social, ciencias biológicas y médicas.
Y lo que es más, pensamos que la significación estadística no debería servir como un umbral de línea brillante para la publicación. También podrían publicarse resultados estadísticamente sugerentes, o incluso resultados que en gran medida no son concluyentes, basado en si informaron o no evidencia preliminar importante con respecto a la posibilidad de que una nueva teoría pudiera ser cierta.
El 11 de octubre presentamos esta idea a un grupo de estadísticos en el Simposio de Inferencia Estadística de la ASA en Bethesda, Maryland. Nuestro objetivo al cambiar la definición de significancia estadística es restaurar el significado pretendido de este término:que los datos han brindado un apoyo sustancial para un descubrimiento científico o efecto de tratamiento.
Críticas a nuestra idea
No todo el mundo está de acuerdo con nuestra propuesta, incluido otro grupo de científicos dirigido por el psicólogo Daniel Lakens.
Argumentan que la definición de los factores de Bayes es demasiado subjetiva, y que los investigadores pueden hacer otras suposiciones que podrían cambiar sus conclusiones. En el ensayo clínico, por ejemplo, Lakens podría argumentar que los investigadores podrían informar la tasa de remisión de tres meses en lugar de seis meses, si proporcionó pruebas más contundentes a favor del nuevo fármaco.
Lakens y su grupo también sienten que la estimación de que solo uno de cada 13 experimentos se replicará es demasiado baja. Señalan que esta estimación no incluye efectos como p-hacking, un término para cuando los investigadores analizan repetidamente sus datos hasta que encuentran un valor p fuerte.
En lugar de subir el listón de la significación estadística, el grupo de Lakens piensa que los investigadores deberían establecer y justificar su propio nivel de significación estadística antes de realizar sus experimentos.
No estoy de acuerdo con muchas de las afirmaciones del grupo Lakens y, desde una perspectiva puramente práctica, Siento que su propuesta es inútil. La mayoría de las revistas científicas no proporcionan un mecanismo para que los investigadores registren y justifiquen su elección de valores p antes de realizar experimentos. Más importante, permitir que los investigadores establezcan sus propios umbrales de evidencia no parece una buena manera de mejorar la reproducibilidad de la investigación científica.
La propuesta de Lakens solo funcionaría si los editores de revistas y las agencias de financiación acordaran de antemano publicar informes de experimentos que no se han realizado según los criterios que los propios científicos han impuesto. Creo que es poco probable que esto suceda en el futuro cercano.
Hasta que lo haga Le recomiendo que no confíe en las afirmaciones de estudios científicos basados en valores p cercanos a 0,05. Insista en un estándar más alto.
Este artículo se publicó originalmente en The Conversation. Lea el artículo original.