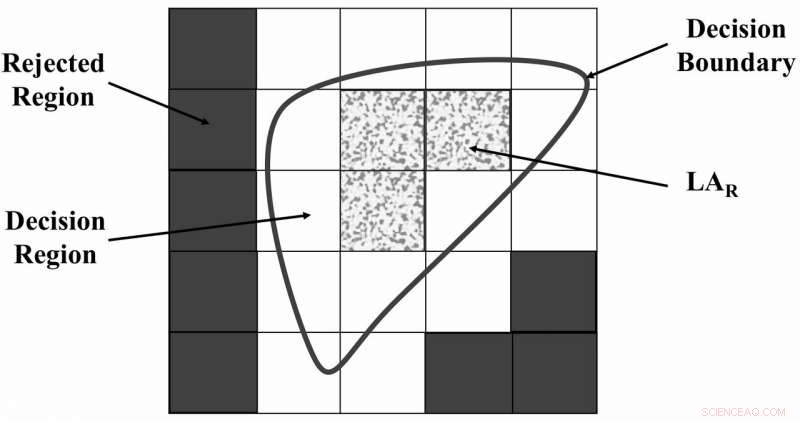
El universo de regiones discursivas segregadas por FRS. Crédito:Zabihimayvan &Doran.
En décadas recientes, Los ataques de phishing se han vuelto cada vez más comunes. Estos ataques permiten a los atacantes obtener datos confidenciales de los usuarios, como contraseñas, nombres de usuario, detalles de la tarjeta de crédito, etc., engañando a las personas para que revelen información personal. El tipo más común de ataque de phishing son las estafas por correo electrónico en las que se hace creer a los usuarios que deben proporcionar sus datos a una entidad establecida o de confianza. mientras son, De hecho, compartir estos datos con otra persona.
Los profesionales de TI han desarrollado una gran cantidad de herramientas y estrategias para detectar y prevenir ataques de phishing, muchos de los cuales se basan en el aprendizaje automático. El rendimiento de estos algoritmos de aprendizaje automático a menudo depende de las características que extraen de los sitios web.
Investigadores de la Universidad Estatal de Wright han desarrollado recientemente un nuevo método para identificar los mejores conjuntos de características para los algoritmos de detección de ataques de phishing. Su enfoque descrito en un artículo publicado previamente en arXiv, podría ayudar a mejorar el rendimiento de los algoritmos individuales de aprendizaje automático para descubrir ataques de phishing.
"El rendimiento de los algoritmos de detección de phishing que utilizan el aprendizaje automático depende en gran medida de las características de un sitio web que el algoritmo considere, incluida la longitud de la URL de la página web o si existen caracteres especiales como @ y guión en la URL, "Mahdieh Zabihimayvan y Derek Doran, los dos investigadores que realizaron el estudio, dijo a TechXplore por correo electrónico. "En este trabajo, Queríamos facilitar la creación de algoritmos de aprendizaje automático para la detección de suplantación de identidad mediante la recuperación automática de un "mejor" conjunto de funciones para cualquier algoritmo de detección de suplantación de identidad, independientemente del sitio web en cuestión ".
Si bien ahora existen varios algoritmos para identificar ataques de phishing, hasta aquí, muy pocos estudios se han centrado en determinar las características más efectivas para detectar este tipo particular de ataque. En su estudio, Zabihimayvan y Doran abordaron esta brecha en la literatura, tratando de descubrir las características más efectivas para esta tarea en particular.
"Aplicamos la teoría Fuzzy Rough Set (FRS) como una herramienta para seleccionar las funciones más efectivas de tres conjuntos de datos comparativos de sitios web de phishing, "Zabihimayvan y Doran dijeron." Las características seleccionadas se utilizan luego para tres algoritmos de aprendizaje automático de uso frecuente para la detección de phishing ".
Para probar la efectividad y la generalización de su enfoque de selección de características de las NIF, los investigadores lo utilizaron para entrenar a tres clasificadores de detección de phishing comúnmente empleados en un conjunto de datos de 14, 000 muestras de sitios web y luego evaluaron su rendimiento. Sus evaluaciones arrojaron resultados muy prometedores, alcanzando una medida F máxima del 95 por ciento cuando su método de selección de características se aplicó a un clasificador de bosque aleatorio (RM).
"FRS descubre dependencias de funciones basadas en los datos, "Zabihimayvan y Doran explicaron". En otras palabras, FRS decide cómo separar un conjunto de datos en función de sus valores de características y etiquetas utilizando un límite de decisión y una relación de similitud declarada en forma de funciones de pertenencia difusas. Las características seleccionadas por FRS son las que pueden distinguir mejor entre muestras de datos que pertenecen a diferentes clases ".
El enfoque FRS utilizado por Zabihimayvan y Doran seleccionó nueve características universales en todos los conjuntos de datos utilizados en su estudio. Con este conjunto de funciones universales, alcanzaron una medida F de aproximadamente el 93 por ciento, que es similar a la lograda por los clasificadores usando su enfoque FRS. El conjunto de funciones universales no contiene funciones de servicios de terceros, por lo que este hallazgo sugiere que uno podría detectar ataques de phishing más rápido sin consultas de fuentes externas.
"Las funciones seleccionadas automáticamente por FRS producen el mejor rendimiento de detección en varios clasificadores, "Zabihimayvan y Doran dijeron." También encontramos un conjunto de 'características universales' - aquellos aspectos de una página web que FRS encontró para predecir mejor si una página está intentando pescar información, no importa el tipo de sitio web que la página intente imitar ".
El estudio realizado por Zabihimayvan y Doran es uno de los primeros en proporcionar información valiosa sobre las funciones más efectivas para detectar ataques de phishing. En el futuro, Su trabajo podría allanar el camino para el desarrollo de técnicas de detección de phishing más eficaces y fiables. que descubriría estos ataques más rápido que los métodos actuales.
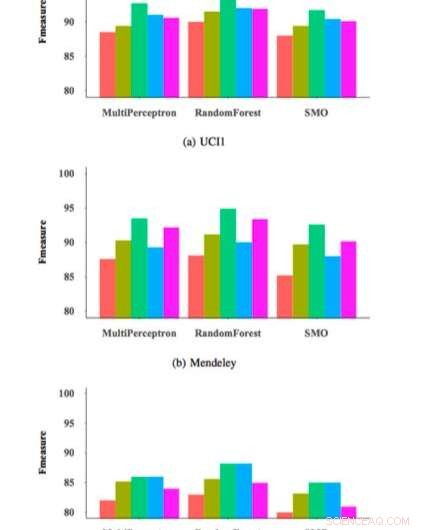
Medida F para diferentes clasificadores y conjuntos de características. Crédito:Zabihimayvan &Doran.
"Ahora esperamos ampliar aún más nuestro estudio investigando la selección de funciones para algoritmos de aprendizaje automático más sofisticados, incluidas arquitecturas de aprendizaje profundo que descubren automáticamente 'metacaracterísticas' para mejorar aún más el rendimiento de detección, "Zabihimayvan y Doran dijeron." También planeamos ampliar nuestro marco de selección de funciones para detectar correos electrónicos de phishing ".
© 2019 Science X Network