Los investigadores utilizaron el aprendizaje automático para crear el primer estudio basado en datos para iluminar cómo la cultura afecta el significado de las palabras. Crédito:Pintura de la Torre de Babel de Pieter Bruegel el Viejo, Kunsthistorisches Museum de Viena, Viena, Austria
¿Qué queremos decir con la palabra hermosa? Depende no solo de a quién le preguntes, pero en que idioma les preguntas. Según un análisis de aprendizaje automático de docenas de idiomas realizado en la Universidad de Princeton, el significado de las palabras no se refiere necesariamente a un intrínseco, constante esencial. En lugar de, está significativamente moldeado por la cultura, Historia y Geografía. Este hallazgo se mantuvo incluso para algunos conceptos que parecerían ser universales, como las emociones, características del paisaje y partes del cuerpo.
"Incluso para todos los días, las palabras que crees que significan lo mismo para todos, existe toda esta variabilidad, "dijo William Thompson, investigador postdoctoral en ciencias de la computación en la Universidad de Princeton, y autor principal de los hallazgos, publicado en Comportamiento humano de la naturaleza 10 de agosto. "Hemos proporcionado la primera evidencia basada en datos de que la forma en que interpretamos el mundo a través de las palabras es parte de nuestra herencia cultural".
El lenguaje es el prisma a través del cual conceptualizamos y entendemos el mundo, y los lingüistas y antropólogos han buscado durante mucho tiempo desenredar las fuerzas complejas que dan forma a estos sistemas críticos de comunicación. Pero los estudios que intentan abordar esas preguntas pueden ser difíciles de realizar y consumir mucho tiempo, a menudo implica mucho, entrevistas cuidadosas con hablantes bilingües que evalúan la calidad de las traducciones. "Puede llevar años y años documentar un par específico de idiomas y las diferencias entre ellos, ", Dijo Thompson." Pero los modelos de aprendizaje automático han surgido recientemente que nos permiten hacer estas preguntas con un nuevo nivel de precisión ".
En su nuevo periódico, Thompson y sus colegas Seán Roberts de la Universidad de Bristol, REINO UNIDO., y Gary Lupyan de la Universidad de Wisconsin, Madison, aprovechó el poder de esos modelos para analizar más de 1, 000 palabras en 41 idiomas.
En lugar de intentar definir las palabras, el método a gran escala utiliza el concepto de "asociaciones semánticas, "o simplemente palabras que tienen una relación significativa entre sí, que los lingüistas consideran una de las mejores formas de definir una palabra y compararla con otra. Asociados semánticos de "hermosa, " por ejemplo, incluir "colorido, " "amor, "" precioso "y" delicado ".
Los investigadores construyeron un algoritmo que examinó las redes neuronales entrenadas en varios lenguajes para comparar millones de asociaciones semánticas. El algoritmo tradujo los asociados semánticos de una palabra en particular a otro idioma, y luego repitió el proceso al revés. Por ejemplo, el algoritmo tradujo los asociados semánticos de "hermoso" al francés y luego tradujo los asociados semánticos de beau al inglés. La puntuación final de similitud del algoritmo para el significado de una palabra se obtuvo al cuantificar qué tan cerca se alineaba la semántica en ambas direcciones de la traducción.
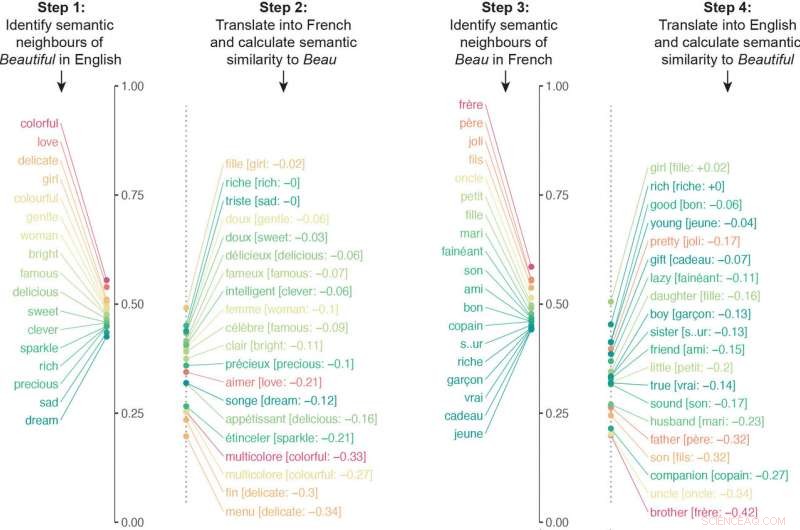
El algoritmo tradujo los asociados semánticos de una palabra en particular a otro idioma, y luego repitió el proceso al revés. En este ejemplo, los vecinos semánticos de "beautiful" se tradujeron al francés y luego los vecinos semánticos de "beau" se tradujeron al inglés. Las listas respectivas eran sustancialmente diferentes debido a las diferentes asociaciones culturales. Imagen cortesía de los investigadores. Crédito:Universidad de Princeton
"Una forma de ver lo que hemos hecho es una forma basada en datos de cuantificar qué palabras son más traducibles, "Dijo Thompson.
Los hallazgos revelaron que hay algunas palabras traducibles casi universalmente, principalmente aquellos que se refieren a números, profesiones, cantidades, fechas del calendario y parentesco. Muchos otros tipos de palabras, sin embargo, incluidos los que se refieren a animales, comida y emociones, tenían un significado mucho peor.
En un paso final, los investigadores aplicaron otro algoritmo que comparó cuán similares son las culturas que produjeron los dos idiomas, basado en un conjunto de datos antropológicos que compara cosas como las prácticas matrimoniales, sistemas legales y organización política de los hablantes de una lengua determinada.
Los investigadores descubrieron que su algoritmo podía predecir correctamente la facilidad con la que se podrían traducir dos idiomas en función de la similitud de las dos culturas que los hablan. Esto muestra que la variabilidad en el significado de las palabras no es simplemente aleatoria. La cultura juega un papel importante en la configuración de los lenguajes, una hipótesis que la teoría ha predicho durante mucho tiempo, pero que los investigadores carecían de datos cuantitativos que lo respaldaran.
"Este es un artículo extremadamente agradable que proporciona una cuantificación basada en principios de cuestiones que han sido fundamentales para el estudio de la semántica léxica, "dijo Damián Blasi, un científico del lenguaje en la Universidad de Harvard, que no participó en la nueva investigación. Si bien el artículo no proporciona una respuesta definitiva para todas las fuerzas que dan forma a las diferencias en el significado de las palabras, los métodos que establecieron los autores son sólidos, Blasi dijo:y el uso de múltiples, diversas fuentes de datos "es un cambio positivo en un campo que ha ignorado sistemáticamente el papel de la cultura en favor de los universales mentales o cognitivos".
Thompson estuvo de acuerdo en que los hallazgos de él y sus colegas enfatizan el valor de "seleccionar conjuntos de datos poco probables que normalmente no se ven en las mismas circunstancias". Los algoritmos de aprendizaje automático que usaron él y sus colegas fueron entrenados originalmente por científicos informáticos, mientras que los conjuntos de datos que incorporaron a los modelos para analizar fueron creados por antropólogos del siglo XX, así como por estudios lingüísticos y psicológicos más recientes. Como dijo Thompson, "Detrás de estos nuevos y sofisticados métodos, hay toda una historia de personas en múltiples campos que recopilan datos que estamos reuniendo y analizando de una manera completamente nueva ".