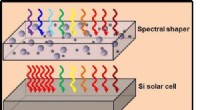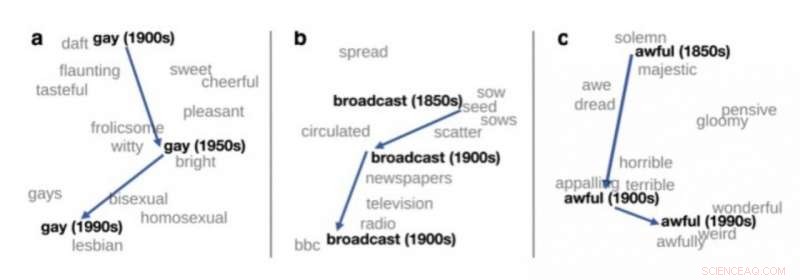
Vista bidimensional del cambio de significado de tres palabras en inglés, tomado de Hamilton et al. (2016). Crédito:upf
La semántica distributiva obtiene representaciones del significado de las palabras procesando miles de textos y extrayendo generalizaciones utilizando algoritmos computacionales. A pesar de la popularidad de la semántica distributiva en campos como la lingüística computacional y la ciencia cognitiva, su impacto en la lingüística teórica ha sido hasta ahora muy limitado.
Investigación de Gemma Boleda, jefe del grupo de investigación Lingüística Computacional y Teoría del Lenguaje (COLT) y profesor investigador ICREA del Departamento de Traducción y Ciencias del Lenguaje de la UPF, publicado en la revista Revisión anual de lingüística , proporciona una revisión crítica de los abundantes estudios disponibles sobre semántica distributiva, poniendo especial énfasis en los resultados relevantes para la lingüística teórica. Específicamente, hay tres áreas:cambio semántico, polisemia y composición, y la interfaz gramática-semántica.
La investigación de Gemma Boleda busca conectar enfoques teóricos y computacionales para avanzar en el conocimiento colectivo sobre cómo funciona el lenguaje. Uno de los métodos que ha investigado extensamente es la semántica distributiva, lo que permite obtener representaciones de palabras de forma automática. Se ha demostrado que estas representaciones reflejan propiedades lingüísticas significativas, por ejemplo, en qué se parecen dos palabras:una persona te dirá que "perro" y "cachorro" son muy similares, y, sin embargo, "perro" y "democracia" apenas se parecen en absoluto; la semántica distributiva dirá lo mismo, gracias a que induce propiedades lingüísticas basadas en textos escritos por personas. Por lo tanto, La semántica distributiva proporciona representaciones radicalmente empíricas.
La semántica distributiva permite analizar el uso de las palabras y la evolución de su significado.
La semántica distributiva proporciona un atractivo marco complementario a otros, métodos más tradicionales, no solo porque es radicalmente empírico, sino también porque proporciona representaciones multidimensionales:dos palabras pueden compararse en una dimensión de significado ("pizza" y "pasta" son tipos de comida), o en otro ("pizza" y "rueda" son redondos). Para representar todos los aspectos del significado, se necesitan representaciones multidimensionales. La semántica distributiva puede capturar los usos comunes de dos palabras, así como sus factores diferenciadores.
Una de las aplicaciones importantes de la semántica distributiva en la lingüística teórica es la detección de cambios de significado. Si se procesan datos de idiomas de diferentes períodos, como libros en inglés de 1900, 1950 y 1990, La semántica distributiva se puede utilizar para detectar automáticamente el cambio de significado de algunas palabras. Por ejemplo, la palabra "gay" en inglés a principios del siglo pasado significaba "feliz" y se ha utilizado cada vez más para significar "homosexual".
Aspectos de la investigación en semántica distributiva que contribuyen a la teoría del lenguaje
A partir del análisis de las obras estudiadas, Boleda concluye que existe evidencia suficiente para que los sólidos resultados de la semántica distributiva se importen directamente a la investigación en lingüística teórica.
"Hay al menos cuatro aspectos de la investigación en semántica distributiva que pueden contribuir a la teoría del lenguaje. El primer aspecto es exploratorio:las representaciones distributivas se pueden utilizar para explorar datos a gran escala, por ejemplo, examinando la similitud de palabras. El segundo es una herramienta para identificar casos específicos de fenómenos lingüísticos. Por ejemplo, Se pueden identificar palabras cuyos significados han cambiado al comparar las representaciones obtenidas de textos de diferentes épocas. El tercero es como banco de pruebas:evaluar diferentes hipótesis lingüísticas en términos distributivos. El cuarto y más difícil es el descubrimiento de nuevos fenómenos lingüísticos o tendencias teóricas relevantes en los datos. "explica la autora en su obra.