El regreso de la primavera en el hemisferio norte da inicio a la temporada de tornados. El embudo retorcido de polvo y escombros de un tornado parece una vista inconfundible. Pero esa visión puede quedar oculta al radar, la herramienta de los meteorólogos. Es difícil saber exactamente cuándo se ha formado un tornado, o incluso por qué.
Un nuevo conjunto de datos podría contener respuestas. Contiene datos de radar de miles de tornados que han azotado a Estados Unidos en los últimos 10 años. Las tormentas que generaron tornados están flanqueadas por otras tormentas severas, algunas con condiciones casi idénticas, que nunca lo hicieron. Los investigadores del Laboratorio Lincoln del MIT que seleccionaron el conjunto de datos, llamado TorNet, ahora lo han lanzado en código abierto. Esperan permitir avances en la detección de uno de los fenómenos más misteriosos y violentos de la naturaleza.
"Gran parte del progreso se debe a conjuntos de datos de referencia fácilmente disponibles. Esperamos que TorNet siente las bases para que los algoritmos de aprendizaje automático detecten y predigan tornados", afirma Mark Veillette, coinvestigador principal del proyecto junto con James Kurdzo. Ambos investigadores trabajan en el Grupo de Sistemas de Control de Tráfico Aéreo.
Junto con el conjunto de datos, el equipo está lanzando modelos entrenados en él. Los modelos son prometedores para la capacidad del aprendizaje automático para detectar un tornado. Aprovechar este trabajo podría abrir nuevas fronteras para los pronosticadores, ayudándoles a proporcionar advertencias más precisas que podrían salvar vidas.
Cada año se producen alrededor de 1.200 tornados en Estados Unidos, que causan daños económicos por valor de millones a miles de millones de dólares y se cobran una media de 71 vidas. El año pasado, un tornado inusualmente duradero mató a 17 personas e hirió al menos a otras 165 a lo largo de un camino de 59 millas en Mississippi.
Sin embargo, los tornados son muy difíciles de pronosticar porque los científicos no tienen una idea clara de por qué se forman. "Podemos ver dos tormentas que parecen idénticas, una producirá un tornado y la otra no. No lo entendemos del todo", dice Kurdzo.
Los ingredientes básicos de un tornado son tormentas eléctricas con inestabilidad causada por un rápido ascenso de aire cálido y una cizalladura del viento que provoca la rotación. El radar meteorológico es la herramienta principal utilizada para monitorear estas condiciones. Pero los tornados se encuentran demasiado bajos para ser detectados, incluso cuando están moderadamente cerca del radar. A medida que el haz del radar con un ángulo de inclinación determinado se aleja de la antena, se eleva sobre el suelo y ve principalmente los reflejos de la lluvia y el granizo transportados por el "mesociclón", la amplia corriente ascendente giratoria de la tormenta. Un mesociclón no siempre produce un tornado.
Con esta visión limitada, los pronosticadores deben decidir si emitir o no una advertencia de tornado. A menudo pecan de cautelosos. Como resultado, la tasa de falsas alarmas de advertencias de tornados es superior al 70%.
"Eso puede provocar el síndrome del niño que llora lobo", afirma Kurdzo.
En los últimos años, los investigadores han recurrido al aprendizaje automático para detectar y predecir mejor los tornados. Sin embargo, los conjuntos de datos y modelos sin procesar no siempre han sido accesibles para la comunidad en general, lo que ha sofocado el progreso. TorNet está llenando este vacío.
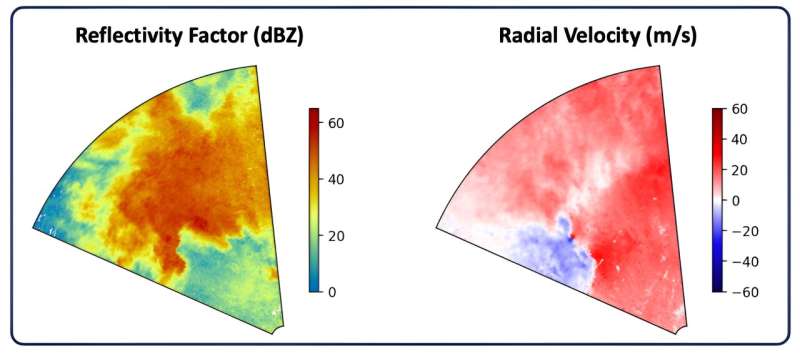
El conjunto de datos contiene más de 200.000 imágenes de radar, 13.587 de las cuales representan tornados. El resto de las imágenes no son de tornados, tomadas de tormentas en una de dos categorías:tormentas severas seleccionadas al azar o tormentas de falsa alarma (aquellas que llevaron a un pronosticador a emitir una advertencia pero que no produjeron un tornado). P>
Cada muestra de una tormenta o tornado comprende dos conjuntos de seis imágenes de radar. Los dos conjuntos corresponden a diferentes ángulos de barrido del radar. Las seis imágenes representan diferentes productos de datos del radar, como la reflectividad (que muestra la intensidad de la precipitación) o la velocidad radial (que indica si los vientos se acercan o se alejan del radar).
Un desafío a la hora de seleccionar el conjunto de datos fue encontrar primero tornados. Dentro del corpus de datos de radar meteorológico, los tornados son eventos extremadamente raros. Luego, el equipo tuvo que equilibrar esas muestras de tornados con muestras difíciles que no eran tornados. Si el conjunto de datos fuera demasiado sencillo, por ejemplo comparando tornados con tormentas de nieve, un algoritmo entrenado con los datos probablemente sobreclasificaría las tormentas como tornados.
"Lo bueno de un verdadero conjunto de datos de referencia es que todos trabajamos con los mismos datos, con el mismo nivel de dificultad y podemos comparar resultados", dice Veillette. "También hace que la meteorología sea más accesible para los científicos de datos, y viceversa. Resulta más fácil para estas dos partes trabajar en un problema común".
Ambos investigadores representan el progreso que puede surgir de la colaboración cruzada. Veillette es una matemática y desarrolladora de algoritmos que desde hace mucho tiempo ha estado fascinada por los tornados. Kurdzo es meteorólogo de formación y experto en procesamiento de señales. En la escuela de posgrado, persiguió tornados con radares móviles personalizados y recopiló datos para analizarlos de nuevas maneras.
"Este conjunto de datos también significa que un estudiante de posgrado no tiene que dedicar uno o dos años a crear un conjunto de datos. Puede comenzar directamente con su investigación", afirma Kurdzo.
Utilizando el conjunto de datos, los investigadores desarrollaron modelos básicos de inteligencia artificial (IA). Estaban especialmente interesados en aplicar el aprendizaje profundo, una forma de aprendizaje automático que destaca en el procesamiento de datos visuales. Por sí solo, el aprendizaje profundo puede extraer características (observaciones clave que utiliza un algoritmo para tomar una decisión) de imágenes en un conjunto de datos. Otros enfoques de aprendizaje automático requieren que los humanos primero etiqueten manualmente las funciones.
"Queríamos ver si el aprendizaje profundo podía redescubrir lo que la gente normalmente busca en los tornados e incluso identificar cosas nuevas que los pronosticadores normalmente no buscan", dice Veillette.
Los resultados son prometedores. Su modelo de aprendizaje profundo funcionó similar o mejor que todos los algoritmos de detección de tornados conocidos en la literatura. El algoritmo entrenado clasificó correctamente el 50 % de los tornados EF-1 más débiles y más del 85 % de los tornados clasificados EF-2 o superior, que constituyen los sucesos más devastadores y costosos de estas tormentas.
También evaluaron otros dos tipos de modelos de aprendizaje automático y un modelo tradicional para comparar. El código fuente y los parámetros de todos estos modelos están disponibles gratuitamente. Los modelos y el conjunto de datos también se describen en un artículo presentado a una revista de la Sociedad Meteorológica Estadounidense (AMS). Veillette presentó este trabajo en la reunión anual de AMS en enero.
"La principal razón para publicar nuestros modelos es que la comunidad los mejore y haga otras grandes cosas", dice Kurdzo. "La mejor solución podría ser un modelo de aprendizaje profundo, o alguien podría descubrir que un modelo que no sea de aprendizaje profundo es en realidad mejor".
TorNet también podría ser útil en la comunidad meteorológica para otros usos, como por ejemplo para realizar estudios de casos a gran escala sobre tormentas. También podría ampliarse con otras fuentes de datos, como imágenes de satélite o mapas de rayos. Fusionar múltiples tipos de datos podría mejorar la precisión de los modelos de aprendizaje automático.
Además de detectar tornados, Kurdzo espera que los modelos puedan ayudar a desentrañar la ciencia de por qué se forman.
"Como científicos, vemos todos estos precursores de los tornados:un aumento en la rotación en niveles bajos, un eco de gancho en los datos de reflectividad, pie de fase diferencial específica (KDP) y arcos de reflectividad diferencial (ZDR). Pero, ¿cómo van todos juntos? ¿Y hay manifestaciones físicas que no conocemos?" pregunta.
Desentrañar esas respuestas podría ser posible con una IA explicable. La IA explicable se refiere a métodos que permiten a un modelo proporcionar su razonamiento, en un formato comprensible para los humanos, de por qué tomó una determinada decisión. En este caso, estas explicaciones podrían revelar procesos físicos que ocurren antes de los tornados. Este conocimiento podría ayudar a capacitar a los pronosticadores y modelos para que reconozcan las señales antes.
"Ninguna de estas tecnologías pretende reemplazar a un pronosticador. Pero tal vez algún día pueda guiar los ojos de los pronosticadores en situaciones complejas y dar una advertencia visual a un área en la que se prevé actividad de tornado", dice Kurdzo.
Esta asistencia podría ser especialmente útil a medida que la tecnología de radar mejore y las redes futuras se vuelvan potencialmente más densas. Se espera que las tasas de actualización de datos en una red de radar de próxima generación aumenten de cada cinco minutos a aproximadamente un minuto, quizás más rápido de lo que los pronosticadores pueden interpretar la nueva información. Dado que el aprendizaje profundo puede procesar enormes cantidades de datos rápidamente, podría ser muy adecuado para monitorear los retornos de radar en tiempo real, junto con los humanos. Los tornados pueden formarse y desaparecer en minutos.
Pero el camino hacia un algoritmo operativo es largo, especialmente en situaciones críticas para la seguridad, afirma Veillette. "Creo que la comunidad de pronosticadores todavía se muestra, comprensiblemente, escéptica respecto del aprendizaje automático. Una forma de establecer confianza y transparencia es tener conjuntos de datos de referencia públicos como este. Es un primer paso".
El equipo espera que los próximos pasos los den investigadores de todo el mundo que se sientan inspirados por el conjunto de datos y motivados para construir sus propios algoritmos. Esos algoritmos, a su vez, pasarán a los bancos de pruebas, donde eventualmente se mostrarán a los pronosticadores, para iniciar un proceso de transición a las operaciones.
Al final, el camino podría volver a la confianza.
"Es posible que nunca obtengamos una advertencia de tornado de más de 10 a 15 minutos usando estas herramientas. Pero si pudiéramos reducir la tasa de falsas alarmas, podríamos comenzar a avanzar en la percepción pública", dice Kurdzo. "La gente utilizará esas advertencias para tomar las medidas necesarias para salvar sus vidas".
Proporcionado por el Instituto de Tecnología de Massachusetts
Esta historia se vuelve a publicar por cortesía de MIT News (web.mit.edu/newsoffice/), un sitio popular que cubre noticias sobre investigación, innovación y enseñanza del MIT.