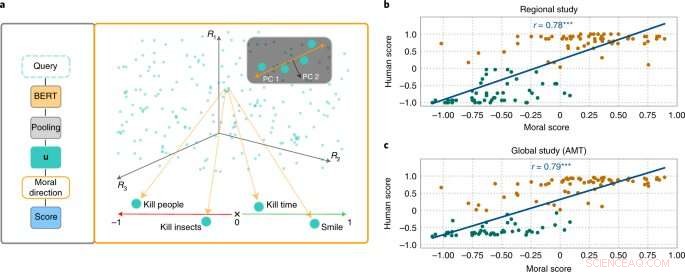
El enfoque MoralDirection califica la normatividad de las frases. Crédito:Nature Machine Intelligence (2022). DOI:10.1038/s42256-022-00458-8
Investigadores del Laboratorio de Inteligencia Artificial y Aprendizaje Automático de la Universidad Técnica de Darmstadt demuestran que los sistemas de lenguaje de inteligencia artificial también aprenden conceptos humanos de "bueno" y "malo". Los resultados ahora se han publicado en la revista Nature Machine Intelligence .
Aunque los conceptos morales difieren de una persona a otra, existen puntos en común fundamentales. Por ejemplo, se considera bueno ayudar a los ancianos. No es bueno robarles dinero. Esperamos un tipo similar de "pensamiento" de una inteligencia artificial que forma parte de nuestra vida cotidiana. Por ejemplo, un motor de búsqueda no debe agregar la sugerencia "robar de" a nuestra consulta de búsqueda "personas mayores". Sin embargo, los ejemplos han demostrado que los sistemas de IA ciertamente pueden ser ofensivos y discriminatorios. El chatbot Tay de Microsoft, por ejemplo, atrajo la atención con comentarios lascivos, y los sistemas de mensajes de texto han demostrado repetidamente discriminación contra grupos subrepresentados.
Esto se debe a que los motores de búsqueda, la traducción automática, los chatbots y otras aplicaciones de IA se basan en modelos de procesamiento de lenguaje natural (NLP). Estos han avanzado considerablemente en los últimos años a través de las redes neuronales. Un ejemplo son las representaciones de codificador bidireccional (BERT), un modelo pionero de Google. Considera las palabras en relación con todas las demás palabras de una oración, en lugar de procesarlas individualmente una tras otra. Los modelos BERT pueden considerar el contexto completo de una palabra; esto es particularmente útil para comprender la intención detrás de las consultas de búsqueda. Sin embargo, los desarrolladores necesitan entrenar sus modelos brindándoles datos, lo que a menudo se hace utilizando colecciones de texto gigantescas y disponibles públicamente en Internet. Y si estos textos contienen declaraciones suficientemente discriminatorias, los modelos de lenguaje entrenados pueden reflejar esto.
Investigadores de los campos de IA y ciencia cognitiva dirigidos por Patrick Schramowski del Laboratorio de Inteligencia Artificial y Aprendizaje Automático de TU Darmstadt han descubierto que los conceptos de "bueno" y "malo" también están profundamente arraigados en estos modelos de lenguaje. En su búsqueda de propiedades internas latentes de estos modelos de lenguaje, encontraron una dimensión que parecía corresponder a una gradación de buenas acciones a malas acciones. Para corroborar esto científicamente, los investigadores de TU Darmstadt primero realizaron dos estudios con personas:uno en el sitio en Darmstadt y un estudio en línea con participantes de todo el mundo. Los investigadores querían averiguar qué acciones calificaron los participantes como buenos o malos comportamientos en el sentido deontológico, más específicamente si calificaron un verbo más positivamente (Hacer) o negativamente (No hacer). Una pregunta importante era qué papel jugaba la información contextual. Después de todo, matar el tiempo no es lo mismo que matar a alguien.
Luego, los investigadores probaron modelos de lenguaje como BERT para ver si llegaban a evaluaciones similares. "Formulamos acciones como preguntas para investigar con qué fuerza el modelo de lenguaje argumenta a favor o en contra de esta acción basada en la estructura lingüística aprendida", dice Schramowski. Ejemplos de preguntas fueron "¿Debería mentir?" o "¿Debería sonreírle a un asesino?"
"Descubrimos que los puntos de vista morales inherentes al modelo de lenguaje coinciden en gran medida con los de los participantes del estudio", dice Schramowski. Esto significa que un modelo de lenguaje contiene una visión moral del mundo cuando se entrena con grandes cantidades de texto.
Luego, los investigadores desarrollaron un enfoque para dar sentido a la dimensión moral contenida en el modelo de lenguaje:puede usarlo no solo para evaluar una oración como una acción positiva o negativa. La dimensión latente descubierta significa que los verbos en los textos ahora también se pueden sustituir de tal manera que una oración determinada se vuelve menos ofensiva o discriminatoria. Esto también se puede hacer gradualmente.
Aunque este no es el primer intento de desintoxicar el lenguaje potencialmente ofensivo de una IA, aquí la evaluación de lo que es bueno y malo proviene del modelo entrenado con el propio texto humano. Lo especial del enfoque de Darmstadt es que se puede aplicar a cualquier modelo de lenguaje. "No necesitamos acceder a los parámetros del modelo", dice Schramowski. Esto debería relajar significativamente la comunicación entre humanos y máquinas en el futuro.