(Arriba) Un escenario de navegación visual autónomo considerado por los investigadores, en un previamente desconocido, ambiente interior con humanos, utilizando imágenes RGB monoculares (abajo a la derecha). Enseñar a las máquinas a navegar en entornos interiores que contienen seres humanos, los investigadores crearon HumANav, un conjunto de datos que permite la representación fotorrealista en entornos simulados (por ejemplo, abajo a la izquierda). Crédito:Tolani et al.
Para abordar las tareas para las que están diseñados, los robots móviles deberían poder navegar en entornos del mundo real de manera eficiente, evitando a los humanos u otros obstáculos en su entorno. Si bien los objetos estáticos suelen ser bastante fáciles de detectar y eludir para los robots, evitar a los humanos puede ser más desafiante, ya que implica predecir sus movimientos futuros y planificarlos en consecuencia.
Investigadores de la Universidad de California, Berkeley, han desarrollado recientemente un nuevo marco que podría mejorar la navegación de robots entre humanos en entornos interiores como oficinas, hogares o museos. Su modelo, presentado en un artículo publicado previamente en arXiv, fue entrenado en un conjunto de datos recientemente compilado de imágenes fotorrealistas llamado HumANav.
"Proponemos un marco novedoso para la navegación alrededor de los seres humanos que combina la percepción basada en el aprendizaje con un control óptimo basado en modelos, "escribieron los investigadores en su artículo.
El nuevo marco que estos investigadores desarrollaron, apodado LB-WayPtNav-DH, tiene tres componentes clave:una percepción, una planificación, y un módulo de control. El módulo de percepción se basa en una red neuronal convolucional (CNN) que fue entrenada para mapear la entrada visual del robot en un waypoint (es decir, siguiente estado deseado) mediante aprendizaje supervisado.
El punto de ruta mapeado por la CNN luego se alimenta a los módulos de planificación y control del marco. Conjunto, Estos dos módulos garantizan que el robot se mueva a su ubicación objetivo de forma segura, evitando cualquier obstáculo y humanos en su entorno.
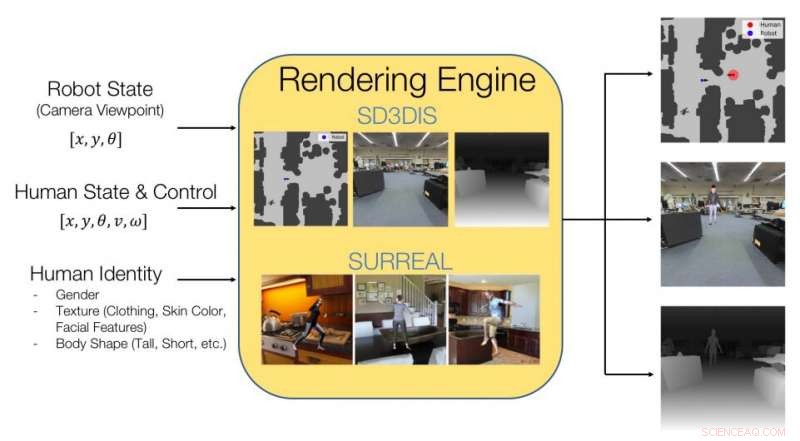
Imagen que explica lo que contiene el conjunto de datos de HumANav y cómo logra una representación fotorrealista de ambientes interiores que contienen humanos. Crédito:Tolani et al.
Los investigadores entrenaron su CNN en imágenes incluidas en un conjunto de datos que compilaron, apodado HumANav. HumANav contiene fotorrealistas, imágenes renderizadas de entornos de edificios simulados en los que los humanos se mueven, adaptado de otro conjunto de datos llamado SURREAL. Estas imágenes retratan 6000 caminando, mallas humanas texturizadas, organizados por la forma del cuerpo, género y velocidad.
"El marco propuesto aprende a anticipar y reaccionar al movimiento de las personas basándose únicamente en una imagen RGB monocular, sin predecir explícitamente el movimiento humano futuro, "escribieron los investigadores en su artículo.
Los investigadores evaluaron LB-WayPtNav-DH en una serie de experimentos, tanto en simulaciones como en el mundo real. En experimentos del mundo real, lo aplicaron a Turtlebot 2, un robot móvil de bajo costo con software de código abierto. Los investigadores informan que el marco de navegación del robot se generaliza bien a los edificios invisibles, eludir eficazmente a los seres humanos tanto en entornos simulados como en el mundo real.
"Nuestros experimentos demuestran que la combinación de control y aprendizaje basados en modelos conduce a comportamientos de navegación mejores y más eficientes en relación con los datos en comparación con un enfoque puramente basado en el aprendizaje, "escribieron los investigadores en su artículo.
En última instancia, el nuevo marco podría aplicarse a una variedad de robots móviles, mejorando su navegación en ambientes interiores. Hasta aquí, su enfoque ha demostrado funcionar notablemente bien, transferir políticas desarrolladas en simulación a entornos del mundo real.
En sus estudios futuros, los investigadores planean entrenar su marco en imágenes de entornos más complejos o abarrotados. Además, les gustaría ampliar el conjunto de datos de entrenamiento que compilaron, incluyendo un conjunto de imágenes más diverso.
© 2020 Science X Network