Hallazgo, y medir el discurso de odio por la islamofobia en las redes sociales. Crédito:John Gomez / Shutterstock
En un movimiento histórico, un grupo de parlamentarios publicó recientemente una definición de trabajo del término islamofobia. Lo definieron como "arraigado en el racismo", y como "un tipo de racismo que tiene como objetivo las expresiones de musulmán o lo que se percibe como musulmán".
En nuestro último documento de trabajo, Queríamos comprender mejor la prevalencia y la gravedad de este discurso de odio islamófobo en las redes sociales. Tal discurso daña a las víctimas objetivo, crea una sensación de miedo entre las comunidades musulmanas, y contraviene los principios fundamentales de equidad. Pero enfrentamos un desafío clave:si bien es extremadamente dañino, El discurso de odio islamófobo es bastante raro.
Cada día se envían miles de millones de publicaciones en las redes sociales, y solo un número muy pequeño de ellos contiene algún tipo de odio. Así que nos propusimos crear una herramienta de clasificación mediante el aprendizaje automático que detecta automáticamente si los tweets contienen islamofobia o no.
Detectar el discurso de odio islamófobo
Se han logrado grandes avances en el uso del aprendizaje automático para clasificar de manera sólida el discurso de odio más general, a escala y de manera oportuna. En particular, Se ha avanzado mucho en la categorización del contenido en función de si es odioso o no.
Pero el discurso de odio islamófobo es mucho más complejo y matizado que esto. Abarca toda la gama desde atacar verbalmente, abusar e insultar a los musulmanes para ignorarlos; desde destacar cómo se los percibe como "diferentes" hasta sugerir que no son miembros legítimos de la sociedad; desde la agresión hasta el despido. Queríamos tener en cuenta este matiz con nuestra herramienta para poder categorizar si el contenido es o no islamofóbico y si la islamofobia es fuerte o débil.
Definimos el discurso de odio islamofóbico como "cualquier contenido producido o compartido que exprese una negatividad indiscriminada contra el Islam o los musulmanes". Esto difiere de la definición de trabajo de islamofobia de los parlamentarios, pero está bien alineada con ella. resaltado arriba. Bajo nuestras definiciones, La islamofobia fuerte incluye declaraciones como "todos los musulmanes son bárbaros", mientras que la islamofobia débil incluye expresiones más sutiles, como "los musulmanes comen comida tan extraña".
Ser capaz de distinguir entre islamofobia débil y fuerte no solo nos ayudará a detectar y eliminar mejor el odio, sino también para comprender la dinámica de la islamofobia, investigar procesos de radicalización en los que una persona se vuelve progresivamente más islamófoba, y brindar un mejor apoyo a las víctimas.
Crédito:Vidgen y Yasseri
Configuración de los parámetros
La herramienta que creamos se llama clasificador de aprendizaje automático supervisado. El primer paso para crear uno es crear un conjunto de datos de entrenamiento o prueba; así es como la herramienta aprende a asignar tweets a cada una de las clases:islamofobia débil, fuerte islamofobia y no islamofobia. La creación de este conjunto de datos es un proceso difícil y que requiere mucho tiempo, ya que cada tweet debe etiquetarse manualmente. por lo que la máquina tiene una base de la que aprender. Otro problema es que detectar el discurso del odio es intrínsecamente subjetivo. Lo que considero fuertemente islamofóbico, podrías pensar que es débil y viceversa.
Hicimos dos cosas para mitigar esto. Primero, Pasamos mucho tiempo creando pautas para etiquetar los tweets. Segundo, tres expertos etiquetaron cada tweet, y utilizó pruebas estadísticas para comprobar cuánto estaban de acuerdo. Empezamos con 4, 000 tweets, muestreados de un conjunto de datos de 140 millones de tweets que recopilamos entre marzo de 2016 y agosto de 2018. La mayoría de los 4, 000 tweets no expresaron ninguna islamofobia, por lo que eliminamos muchos de ellos para crear un conjunto de datos equilibrado, que consta de 410 fuertes, 484 débil, y 447 ninguno (en total, 1, 341 tuits).
El segundo paso fue construir y ajustar el clasificador mediante la ingeniería de características y la selección de un algoritmo. Las características son las que usa el clasificador para asignar cada tweet a la clase correcta. Nuestra característica principal fue un modelo de inserción de palabras, un modelo de aprendizaje profundo que representa palabras individuales como un vector de números, que luego se puede utilizar para estudiar la similitud de palabras y el uso de palabras. También identificamos algunas otras características de los tweets, como la unidad gramatical, sentimiento y el número de menciones de mezquitas.
Una vez que construimos nuestro clasificador, el paso final fue evaluarlo, lo que hicimos aplicándolo a un nuevo conjunto de datos de tweets completamente invisibles. Seleccionamos 100 tweets asignados a cada una de las tres clases, entonces 300 en total, e hizo que nuestros tres codificadores expertos los volvieran a etiquetar. Esto nos permite evaluar el desempeño del clasificador, comparando las etiquetas asignadas por nuestro clasificador con las etiquetas reales.
La principal limitación del clasificador fue que tuvo problemas para identificar los tweets islamófobos débiles, ya que a menudo se superponían con los fuertes y los no islamófobos. Dicho eso en general, su desempeño fue fuerte. La precisión (el número de tweets identificados correctamente) fue del 77% y la precisión del 78%. Debido a nuestro riguroso proceso de diseño y prueba, podemos confiar en que es probable que el clasificador funcione de manera similar cuando se utiliza a escala "en la naturaleza" en datos de Twitter no vistos.
Usando nuestro clasificador
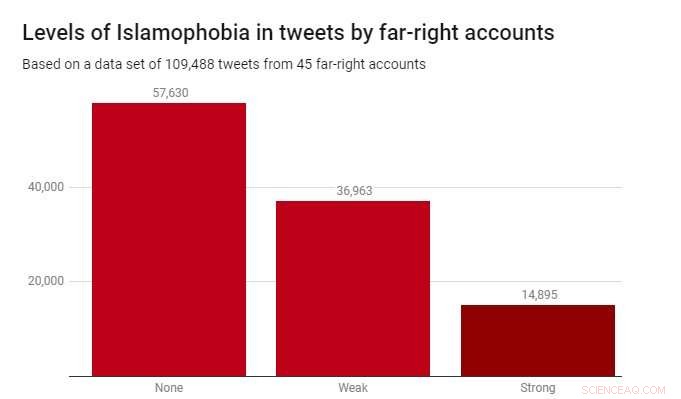
Aplicamos el clasificador a un conjunto de datos de 109, 488 tweets producidos por 45 cuentas de extrema derecha durante 2017. Estos fueron identificados por la organización benéfica Hope Not Hate en sus informes State of Hate de 2015 y 2017. El siguiente gráfico muestra los resultados.
Si bien la mayoría de los tweets (52,6%) no eran islamófobos, La islamofobia débil fue considerablemente más prevalente (33,8%) que la islamofobia fuerte (13,6%). Esto sugiere que la mayor parte de la islamofobia en estos relatos de extrema derecha es sutil e indirecta, en lugar de agresivo o abierto.
Detectar el discurso de odio islamófobo es un desafío real y urgente para los gobiernos, empresas tecnológicas y académicos. Desafortunadamente, este es un problema que no desaparecerá, y no hay soluciones simples. Pero si nos tomamos en serio la eliminación del discurso de odio y el extremismo de los espacios en línea, y hacer que las plataformas de redes sociales sean seguras para todos los que las usan, entonces tenemos que empezar con las herramientas adecuadas. Nuestro trabajo muestra que es completamente posible crear estas herramientas, no solo para detectar automáticamente contenido de odio, sino también para hacerlo de una manera matizada y detallada.
Este artículo se ha vuelto a publicar de The Conversation con una licencia de Creative Commons. Lea el artículo original.