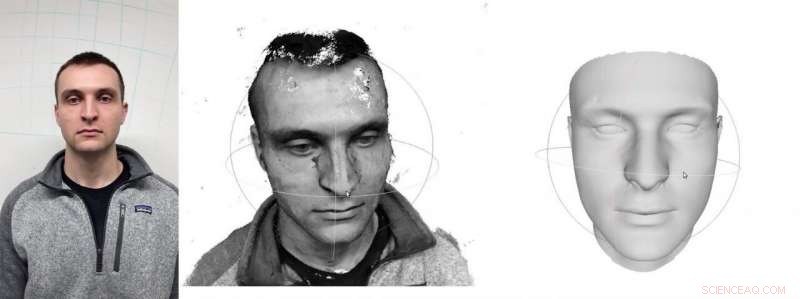
En un proceso de reconstrucción facial en 3D desarrollado en la Universidad Carnegie Mellon, video de teléfono inteligente de una persona, izquierda, se analiza para producir un modelo imperfecto de la cara, medio. Luego, el aprendizaje profundo se combina con técnicas convencionales de visión por computadora para completar la reconstrucción, Derecha. Crédito:Universidad Carnegie Mellon
Normalmente, Se necesitan equipos costosos y experiencia para crear una reconstrucción tridimensional precisa de la cara de alguien que sea realista y no parezca espeluznante. Ahora, Los investigadores de la Universidad Carnegie Mellon han logrado la hazaña utilizando videos grabados en un teléfono inteligente común.
El uso de un teléfono inteligente para grabar un video continuo del frente y los lados del rostro genera una densa nube de datos. Un proceso de dos pasos desarrollado por el Instituto de Robótica de CMU utiliza esos datos, con la ayuda de algoritmos de aprendizaje profundo, para construir una reconstrucción digital del rostro. Los experimentos del equipo muestran que su método puede lograr una precisión submilimétrica, superando a otros procesos basados en cámaras.
Una cara digital podría usarse para construir un avatar para juegos o para realidad virtual o aumentada, y también podría usarse en animación, identificación biométrica e incluso procedimientos médicos. Una representación tridimensional precisa de la cara también podría ser útil para construir mascarillas quirúrgicas o respiradores personalizados.
"La construcción de una reconstrucción en 3-D del rostro ha sido un problema abierto en la visión por computadora y los gráficos porque las personas son muy sensibles al aspecto de los rasgos faciales, "dijo Simon Lucey, profesor asociado de investigación en el Robotics Institute. "Incluso pequeñas anomalías en las reconstrucciones pueden hacer que el resultado final parezca poco realista".
Escáneres láser, Las configuraciones de estudio de luz estructurada y multicámara pueden producir escaneos altamente precisos de la cara, pero estos sensores especializados son prohibitivamente caros para la mayoría de las aplicaciones. El método recientemente desarrollado por CMU, sin embargo, solo requiere un teléfono inteligente.
El método, que Lucey desarrolló con los estudiantes de maestría Shubham Agrawal y Anuj Pahuja, se presentó a principios de marzo en la Conferencia de invierno de IEEE sobre aplicaciones de visión por computadora (WACV) en Snowmass, Colorado. Comienza con la grabación de 15-20 segundos de video. En este caso, los investigadores utilizaron un iPhone X en cámara lenta.
"La alta velocidad de fotogramas de la cámara lenta es una de las claves de nuestro método porque genera una nube de puntos densa, "Dijo Lucey.
Luego, los investigadores emplean una técnica comúnmente utilizada llamada localización y mapeo visual simultáneo (SLAM). Visual SLAM triangula puntos en una superficie para calcular su forma, mientras que al mismo tiempo usa esa información para determinar la posición de la cámara. Esto crea una geometría inicial de la cara, pero los datos faltantes dejan vacíos en el modelo.
En el segundo paso de este proceso, los investigadores trabajan para llenar esos vacíos, primero mediante el uso de algoritmos de aprendizaje profundo. El aprendizaje profundo se utiliza de forma limitada, sin embargo:identifica el perfil de la persona y puntos de referencia como orejas, ojos y nariz. Luego, se utilizan técnicas clásicas de visión por computadora para llenar los vacíos.
"El aprendizaje profundo es una herramienta poderosa que usamos todos los días, ", Dijo Lucey." Pero el aprendizaje profundo tiene una tendencia a memorizar soluciones, "que va en contra de los esfuerzos por incluir detalles distintivos de la cara". Si usa estos algoritmos solo para encontrar los puntos de referencia, puede utilizar métodos clásicos para llenar los vacíos mucho más fácilmente ".
El método no es necesariamente rápido; tomó 30-40 minutos de tiempo de procesamiento. Pero todo el proceso se puede realizar en un teléfono inteligente.
Además de las reconstrucciones faciales, Los métodos del equipo de CMU también podrían emplearse para capturar la geometría de casi cualquier objeto, Dijo Lucey. Las reconstrucciones digitales de esos objetos pueden luego incorporarse en animaciones o tal vez transmitirse a través de Internet a sitios donde los objetos podrían duplicarse con impresoras 3-D.














