
Cuando el futuro es incierto La recompensa futura se puede representar como una distribución de probabilidad. algunos futuros posibles son buenos (verde azulado), otros son malos (rojo). El aprendizaje por refuerzo distributivo puede aprender sobre esta distribución sobre las recompensas previstas a través de una variante del algoritmo TD. Crédito: Naturaleza (2020). DOI:10.1038 / s41586-019-1924-6
Un equipo de investigadores de DeepMind, University College y la Universidad de Harvard han descubierto que las lecciones aprendidas en la aplicación de técnicas de aprendizaje a los sistemas de inteligencia artificial pueden ayudar a explicar cómo funcionan las vías de recompensa en el cerebro. En su artículo publicado en la revista Naturaleza , el grupo describe comparar el aprendizaje por refuerzo distributivo en una computadora con el procesamiento de dopamina en el cerebro del ratón, y lo que aprendieron de él.
Investigaciones anteriores han demostrado que la dopamina producida en el cerebro está involucrada en el procesamiento de la recompensa:se produce cuando sucede algo bueno, y su expresión da como resultado sensaciones de placer. Algunos estudios también han sugerido que las neuronas del cerebro que responden a la presencia de dopamina responden todas de la misma manera:un evento hace que una persona o un ratón se sientan bien o mal. Otros estudios han sugerido que la respuesta neuronal es más un gradiente. En este nuevo esfuerzo, los investigadores han encontrado evidencia que apoya esta última teoría.
El aprendizaje por refuerzo distributivo es un tipo de aprendizaje automático basado en el refuerzo. Se utiliza a menudo al diseñar juegos como Starcraft II o Go. Realiza un seguimiento de los buenos movimientos frente a los malos y aprende a reducir el número de malos movimientos. mejorando su rendimiento cuanto más juega. Pero estos sistemas no tratan todos los movimientos buenos y malos de la misma manera:cada movimiento se pondera a medida que se registra y los pesos son parte de los cálculos que se utilizan al realizar elecciones de movimientos futuros.
Los investigadores han notado que los humanos parecen usar una estrategia similar para mejorar su nivel de juego, así como. Los investigadores en Londres sospecharon que las similitudes entre los sistemas de inteligencia artificial y la forma en que el cerebro lleva a cabo el procesamiento de recompensas probablemente fueran similares. así como. Para saber si eran correctos, llevaron a cabo experimentos con ratones. Insertaron dispositivos en sus cerebros que eran capaces de registrar respuestas de neuronas de dopamina individuales. Luego, los ratones fueron entrenados para realizar una tarea en la que recibieron recompensas por responder de la manera deseada.
Las respuestas de las neuronas del ratón revelaron que no todas respondían de la misma manera, como había predicho la teoría anterior. En lugar de, respondieron de maneras diferentes y confiables, una indicación de que los niveles de placer que experimentaban los ratones eran más un gradiente, como había predicho el equipo.
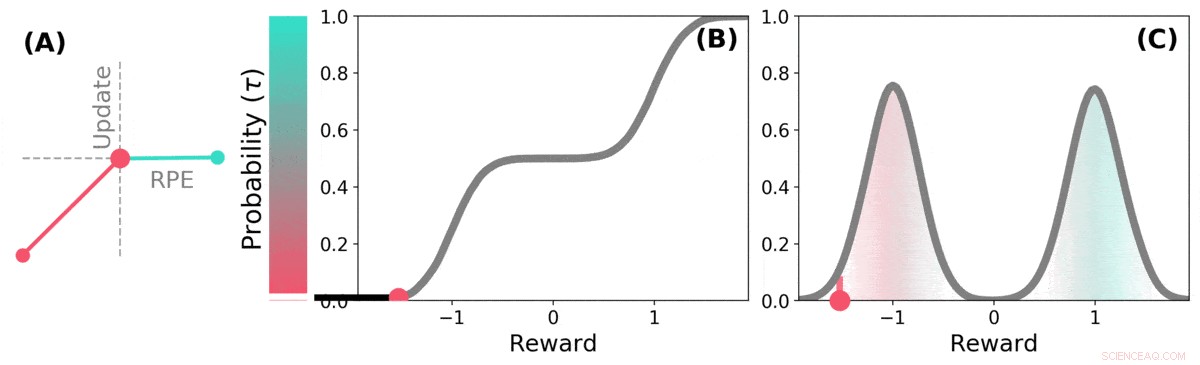
El TD distributivo aprende estimaciones de valor para muchas partes diferentes de la distribución de recompensas. la parte que cubre una estimación en particular está determinada por el tipo de actualización asimétrica aplicada a esa estimación. (a) Una celda "pesimista" amplificaría las actualizaciones negativas e ignoraría las actualizaciones positivas, una celda "optimista" amplificaría las actualizaciones positivas e ignoraría las actualizaciones negativas. (b) Esto da como resultado una diversidad de estimaciones de valor pesimistas u optimistas, se muestran aquí como puntos a lo largo de la distribución acumulativa de recompensas, que capturan (c) La distribución completa de recompensas. Crédito: Naturaleza (2020). DOI:10.1038 / s41586-019-1924-6
© 2020 Science X Network














