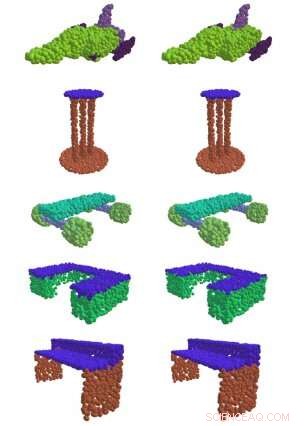
A la izquierda EdgeConv, un método desarrollado en el MIT, encuentra con éxito partes significativas de formas 3D, como la superficie de una mesa, alas de un avion, y ruedas de un monopatín. A la derecha está la comparación de la verdad fundamental. Crédito:Instituto de Tecnología de Massachusetts
Si alguna vez ha visto un automóvil autónomo en la naturaleza, tal vez te preguntes acerca de ese cilindro giratorio que tiene encima.
Es un "sensor lidar, "y es lo que permite que el automóvil navegue por el mundo. Al enviar pulsos de luz infrarroja y medir el tiempo que tardan en rebotar en los objetos, el sensor crea una "nube de puntos" que crea una instantánea tridimensional de los alrededores del automóvil.
Dar sentido a los datos sin procesar de la nube de puntos es difícil, y antes de la era del aprendizaje automático, tradicionalmente se requería que ingenieros altamente capacitados especificaran tediosamente qué cualidades querían capturar a mano. Pero en una nueva serie de artículos del Laboratorio de Ciencias de la Computación e Inteligencia Artificial del MIT (CSAIL), Los investigadores demuestran que pueden utilizar el aprendizaje profundo para procesar automáticamente nubes de puntos para una amplia gama de aplicaciones de imágenes 3D.
"En la visión por computadora y el aprendizaje automático en la actualidad, El 90 por ciento de los avances tratan solo con imágenes bidimensionales, "dice el profesor del MIT Justin Solomon, quien fue el autor principal de la nueva serie de artículos encabezados por Ph.D. estudiante Yue Wang. "Nuestro trabajo tiene como objetivo abordar una necesidad fundamental de representar mejor el mundo 3-D, con aplicación no solo en conducción autónoma, pero cualquier campo que requiera comprender las formas tridimensionales ".
La mayoría de los enfoques anteriores no han tenido mucho éxito en capturar los patrones de los datos necesarios para obtener información significativa de un montón de puntos 3D en el espacio. Pero en uno de los documentos del equipo, demostraron que su método "EdgeConv" de analizar nubes de puntos utilizando un tipo de red neuronal llamada red neuronal convolucional de gráfico dinámico les permitió clasificar y segmentar objetos individuales.
"Al crear 'gráficos' de puntos vecinos, el algoritmo puede capturar patrones jerárquicos y, por lo tanto, inferir múltiples tipos de información genérica que puede ser utilizada por una miríada de tareas posteriores, "dice Wadim Kehl, un científico de aprendizaje automático en el Toyota Research Institute que no participó en el trabajo.
Además de desarrollar EdgeConv, el equipo también exploró otros aspectos específicos del procesamiento de nubes de puntos. Por ejemplo, un desafío es que la mayoría de los sensores cambian de perspectiva a medida que se mueven por el mundo tridimensional; cada vez que hacemos un nuevo escaneo del mismo objeto, su posición puede ser diferente a la última vez que lo vimos. Para fusionar varias nubes de puntos en una sola vista detallada del mundo, necesita alinear varios puntos 3-D en un proceso llamado "registro".
El registro es vital para muchas formas de imágenes, desde datos satelitales hasta procedimientos médicos. Por ejemplo, cuando un médico tiene que realizar varias exploraciones por resonancia magnética de un paciente a lo largo del tiempo, el registro es lo que hace posible alinear los escaneos para ver qué ha cambiado.
"El registro es lo que nos permite integrar datos 3D de diferentes fuentes en un sistema de coordenadas común, "dice Wang." Sin él, en realidad, no podríamos obtener información tan significativa de todos estos métodos que se han desarrollado ".
El segundo artículo de Solomon y Wang demuestra un nuevo algoritmo de registro llamado "Punto más cercano profundo" (DCP) que demostró encontrar mejor los patrones distintivos de una nube de puntos. puntos, y bordes (conocidos como "entidades locales") para alinearlo con otras nubes de puntos. Esto es especialmente importante para tareas como permitir que los coches autónomos se sitúen en una escena ("localización"), así como manos robóticas para localizar y agarrar objetos individuales.
Una limitación de DCP es que asume que podemos ver una forma completa en lugar de solo un lado. Esto significa que no puede manejar la tarea más difícil de alinear vistas parciales de formas (conocido como "registro parcial a parcial"). Como resultado, en un tercer artículo, los investigadores presentaron un algoritmo mejorado para esta tarea que denominan Red de Registro Parcial (PRNet).
Solomon dice que los datos tridimensionales existentes tienden a ser "bastante desordenados y desestructurados en comparación con las imágenes y fotografías bidimensionales". Su equipo trató de descubrir cómo obtener información significativa de todos esos datos tridimensionales desorganizados sin el entorno controlado que ahora requieren muchas tecnologías de aprendizaje automático.
Una observación clave detrás del éxito de DCP y PRNet es la idea de que un aspecto crítico del procesamiento de nubes de puntos es el contexto. Las características geométricas de la nube de puntos A que sugieren las mejores formas de alinearla con la nube de puntos B pueden ser diferentes de las características necesarias para alinearla con la nube de puntos C. Por ejemplo, en registro parcial, una parte interesante de una forma en una nube de puntos puede no ser visible en la otra, lo que la hace inútil para el registro.
Wang dice que las herramientas del equipo ya han sido implementadas por muchos investigadores en la comunidad de visión por computadora y más allá. Incluso los físicos los están utilizando para una aplicación que el equipo de CSAIL nunca había considerado:la física de partículas.
Avanzando los investigadores esperan utilizar los algoritmos en datos del mundo real, incluidos los datos recopilados de vehículos autónomos. Wang dice que también planean explorar el potencial de entrenar sus sistemas mediante el aprendizaje auto-supervisado. para minimizar la cantidad de anotaciones humanas necesarias.
Esta historia se vuelve a publicar por cortesía de MIT News (web.mit.edu/newsoffice/), un sitio popular que cubre noticias sobre la investigación del MIT, innovación y docencia.