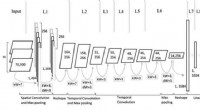
El letrero ha sido modificado para cambiar su significado a los sistemas que se basan en la visión por computadora de "Alto" a "Trabajos en la carretera". Crédito:David Kelly Crow
La capacidad de las máquinas para aprender procesando los datos obtenidos de los sensores es la base de los vehículos automatizados, dispositivos médicos y una serie de otras tecnologías emergentes. Pero esa capacidad de aprendizaje deja los sistemas vulnerables a los piratas informáticos de formas inesperadas, investigadores de la Universidad de Princeton.
En una serie de artículos recientes, un equipo de investigación ha explorado cómo las tácticas adversarias aplicadas a la inteligencia artificial (IA) podrían, por ejemplo, engañar a un sistema de eficiencia del tráfico para que provoque un atasco o manipular una aplicación de inteligencia artificial relacionada con la salud para revelar el historial médico privado de los pacientes. Como ejemplo de uno de esos ataques, el equipo alteró la percepción de un robot conductor de una señal de tráfico de un límite de velocidad a una señal de "Alto", lo que podría hacer que el vehículo golpeara peligrosamente los frenos a velocidades de autopista; en otros ejemplos, alteraron las señales de alto para que se percibieran como una variedad de otras instrucciones de tráfico.
"Si el aprendizaje automático es el software del futuro, estamos en un punto de partida muy básico para asegurarlo, "dijo Prateek Mittal, el investigador principal y profesor asociado en el Departamento de Ingeniería Eléctrica de Princeton. "Para que las tecnologías de aprendizaje automático alcancen su máximo potencial, tenemos que entender cómo funciona el aprendizaje automático en presencia de adversarios. Ahí es donde tenemos un gran desafío.
Así como el software es propenso a ser pirateado e infectado por virus informáticos, o sus usuarios atacados por estafadores a través de suplantación de identidad y otras tácticas que vulneran la seguridad, Las aplicaciones impulsadas por IA tienen sus propias vulnerabilidades. Sin embargo, el despliegue de las salvaguardias adecuadas se ha retrasado. Hasta aquí, la mayor parte del desarrollo del aprendizaje automático se ha producido de forma benigna, entornos cerrados:un escenario radicalmente diferente al del mundo real.
Mittal es un pionero en comprender una vulnerabilidad emergente conocida como aprendizaje automático adversario. En esencia, este tipo de ataque hace que los sistemas de IA produzcan de forma no intencionada, resultados posiblemente peligrosos al corromper el proceso de aprendizaje. En su reciente serie de artículos, El grupo de Mittal describió y demostró tres tipos amplios de ataques de aprendizaje automático adversarios.
Envenenando bien los datos
El primer ataque involucra a un agente malévolo que inserta información falsa en el flujo de datos que un sistema de IA está usando para aprender, un enfoque conocido como envenenamiento de datos. Un ejemplo común es una gran cantidad de teléfonos de usuarios que informan sobre las condiciones del tráfico. Estos datos de fuentes colaborativas se pueden utilizar para entrenar un sistema de inteligencia artificial a fin de desarrollar modelos para un mejor enrutamiento colectivo de automóviles autónomos. reducir la congestión y el desperdicio de combustible.
"Un adversario puede simplemente inyectar datos falsos en la comunicación entre el teléfono y entidades como Apple y Google, y ahora sus modelos podrían verse potencialmente comprometidos, ", dijo Mittal." Todo lo que aprenda de los datos corruptos será sospechoso ".
El grupo de Mittal demostró recientemente una especie de siguiente nivel a partir de este simple envenenamiento de datos, un enfoque que ellos llaman "modelo de envenenamiento". En IA, un "modelo" puede ser un conjunto de ideas que ha formado una máquina, basado en su análisis de datos, sobre cómo funciona alguna parte del mundo. Debido a problemas de privacidad, el teléfono celular de una persona puede generar su propio modelo localizado, permitiendo que los datos de la persona se mantengan confidenciales. Luego, los modelos anónimos se comparten y se combinan con los modelos de otros usuarios. "Cada vez más, las empresas se están moviendo hacia el aprendizaje distribuido donde los usuarios no comparten sus datos directamente, sino entrenar modelos locales con sus datos, "dijo Arjun Nitin Bhagoji, un doctorado estudiante en el laboratorio de Mittal.
Pero los adversarios pueden poner el pulgar en la balanza. Una persona o empresa interesada en el resultado podría engañar a los servidores de una empresa para que sopesen las actualizaciones de su modelo sobre los modelos de otros usuarios. "El objetivo del adversario es asegurarse de que los datos de su elección se clasifiquen en la clase que desean, y no la verdadera clase, "dijo Bhagoji.
En junio, Bhagoji presentó un documento sobre este tema en la Conferencia Internacional sobre Aprendizaje Automático (ICML) de 2019 en Long Beach, California, en colaboración con dos investigadores de IBM Research. El documento exploró un modelo de prueba que se basa en el reconocimiento de imágenes para clasificar si las personas en las imágenes usan sandalias o zapatillas de deporte. Si bien una clasificación errónea inducida de esa naturaleza suena inofensiva, es el tipo de subterfugio injusto en el que podría participar una corporación sin escrúpulos para promocionar su producto sobre el de un rival.
"Los tipos de adversarios que debemos tener en cuenta en la investigación de la IA contradictoria van desde piratas informáticos individuales que intentan extorsionar a personas o empresas por dinero, a las corporaciones que intentan obtener ventajas comerciales, a adversarios a nivel de estado-nación que buscan ventajas estratégicas, "dijo Mittal, quien también está asociado con el Centro de Política de Tecnología de la Información de Princeton.
Usar el aprendizaje automático contra sí mismo
Una segunda amenaza amplia se denomina ataque de evasión. Se asume que un modelo de aprendizaje automático se ha entrenado con éxito con datos genuinos y ha logrado una alta precisión en cualquiera que sea su tarea. Un adversario podría darle la vuelta a ese éxito, aunque, manipulando las entradas que recibe el sistema una vez que comienza a aplicar su aprendizaje a las decisiones del mundo real.
Por ejemplo, la IA para vehículos autónomos ha sido entrenada para reconocer el límite de velocidad y las señales de alto, mientras ignora las señales de los restaurantes de comida rápida, gasolineras, etcétera. El grupo de Mittal ha explorado una laguna jurídica por la cual las señales pueden clasificarse erróneamente si están marcadas de una manera que un humano podría no notar. Los investigadores hicieron letreros de restaurantes falsos con un color adicional similar al graffiti o manchas de paintball. Los cambios engañaron a la inteligencia artificial del automóvil para que confundiera las señales del restaurante con las señales de alto.
"Agregamos pequeñas modificaciones que podrían engañar a este sistema de reconocimiento de señales de tráfico, ", dijo Mittal. Se presentó un documento sobre los resultados en el 1er Taller de aprendizaje profundo y seguridad (DLS), celebrada en mayo de 2018 en San Francisco por el Instituto de Ingenieros Eléctricos y Electrónicos (IEEE).
Aunque sea menor y solo con fines de demostración, la perfidia de la señalización revela nuevamente una forma en que el aprendizaje automático puede ser secuestrado para fines nefastos.
No respetar la privacidad
La tercera gran amenaza son los ataques a la privacidad, que tienen como objetivo inferir datos sensibles utilizados en el proceso de aprendizaje. En la sociedad actual constantemente conectada a Internet, hay mucho de eso chapoteando. Los adversarios pueden intentar aprovechar los modelos de aprendizaje automático mientras absorben datos, obtener acceso a información protegida, como números de tarjetas de crédito, registros de salud y ubicaciones físicas de los usuarios.
Un ejemplo de esta mala conducta, estudió en Princeton, es el "ataque de inferencia de pertenencia". Funciona al medir si un punto de datos en particular se encuentra dentro del conjunto de entrenamiento de aprendizaje automático de un objetivo. Por ejemplo, en caso de que un adversario se apodere de los datos de un usuario mientras selecciona el conjunto de entrenamiento de una aplicación de IA relacionada con la salud, esa información sugeriría fuertemente que el usuario alguna vez fue un paciente en el hospital. Conectar los puntos en varios de esos puntos puede revelar detalles de identificación sobre un usuario y sus vidas.
Proteger la privacidad es posible, pero en este punto implica una compensación de seguridad:las defensas que protegen los modelos de IA de la manipulación a través de ataques de evasión pueden hacerlos más vulnerables a los ataques de inferencia de membresía. Esa es una conclusión clave de un nuevo documento aceptado para la 26a Conferencia de ACM sobre seguridad informática y de comunicaciones (CCS), que se celebrará en Londres en noviembre de 2019, dirigido por Liwei Song, estudiante de posgrado de Mittal. Las tácticas defensivas que se utilizan para protegerse contra los ataques de evasión dependen en gran medida de los datos confidenciales del conjunto de entrenamiento. lo que hace que esos datos sean más vulnerables a los ataques a la privacidad.
Es el clásico debate entre seguridad y privacidad, esta vez con un giro de aprendizaje automático. Song enfatiza, al igual que Mittal, que los investigadores tendrán que empezar a tratar los dos dominios como inextricablemente vinculados, en lugar de centrarse en uno sin tener en cuenta su impacto en el otro.
"En nuestro periódico, mostrando la mayor filtración de privacidad introducida por las defensas contra los ataques de evasión, hemos destacado la importancia de pensar juntos en la seguridad y la privacidad, "dijo Song,
Aún son los primeros días para el aprendizaje automático y la IA adversa, tal vez lo suficientemente temprano como para que las amenazas que inevitablemente se materializan no tengan la ventaja.
"Estamos entrando en una nueva era en la que el aprendizaje automático se integrará cada vez más en casi todo lo que hacemos, ", dijo Mittal." Es imperativo que reconozcamos las amenazas y desarrollemos contramedidas contra ellas ".