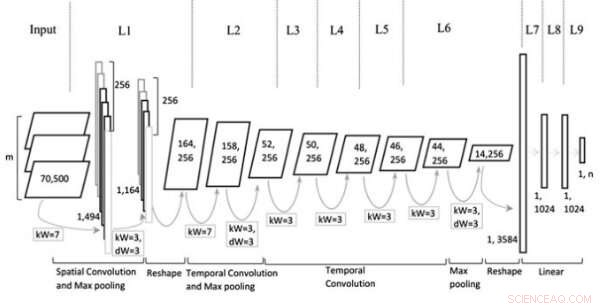
Arquitectura modelo. Crédito:Jin et al, Revista Wiley Computational Intelligence.
Durante la última década más o menos, Las redes neuronales convolucionales (CNN) han demostrado ser muy efectivas para abordar una variedad de tareas, incluidas las tareas de procesamiento del lenguaje natural (PNL). La PNL implica el uso de técnicas computacionales para analizar o sintetizar el lenguaje, tanto en forma escrita como hablada. Los investigadores han aplicado con éxito las CNN a varias tareas de PNL, incluido el análisis semántico, Recuperación de consultas de búsqueda y clasificación de texto.
Típicamente, Las CNN capacitadas para tareas de clasificación de texto procesan oraciones a nivel de palabra, representar palabras individuales como vectores. Aunque este enfoque puede parecer coherente con la forma en que los humanos procesan el lenguaje, Estudios recientes han demostrado que las CNN que procesan oraciones a nivel de personaje también pueden lograr resultados notables.
Una ventaja clave de los análisis a nivel de personaje es que no requieren conocimientos previos de palabras. Esto facilita que las CNN se adapten a diferentes idiomas y adquieran palabras anormales causadas por errores ortográficos.
Estudios anteriores sugieren que diferentes niveles de inserción de texto (es decir, caracteres, palabra-, o nivel de documento) son más eficaces para diferentes tipos de tareas, pero todavía no hay una guía clara sobre cómo elegir la inserción correcta o cuándo cambiar a otra. Teniendo esto en cuenta, Un equipo de investigadores de la Universidad Politécnica de Tianjin en China ha desarrollado recientemente una nueva arquitectura de CNN basada en los tipos de representación que se utilizan normalmente en las tareas de clasificación de textos.
"Proponemos una nueva arquitectura de CNN basada en múltiples representaciones para la clasificación de texto mediante la construcción de múltiples planos para que se pueda verter más información en las redes, como diferentes partes de texto obtenidas a través de un reconocedor de entidad con nombre o herramientas de etiquetado de parte de la voz, diferentes niveles de inserción de texto u oraciones contextuales, "escribieron los investigadores en su artículo.
El modelo CNN multi-representacional (Mr-CNN) ideado por los investigadores se basa en el supuesto de que todas las partes del texto escrito (por ejemplo, sustantivos, verbos etc.) juegan un papel clave en las tareas de clasificación y que diferentes incrustaciones de texto son más efectivas para diferentes propósitos. Su modelo combina dos herramientas clave, el reconocedor de entidad con nombre de Stanford (NER) y el etiquetador de parte del discurso (POS). El primero es un método para etiquetar roles semánticos de cosas en textos (por ejemplo, persona, empresa, etc.); la última es una técnica que se utiliza para asignar etiquetas de parte del habla a cada bloque de texto (por ejemplo, sustantivo o verbo).
Los investigadores utilizaron estas herramientas para preprocesar oraciones, obtener varios subconjuntos de la oración original, cada uno de los cuales contiene tipos específicos de palabras en el texto. Luego usaron los subconjuntos y la oración completa como múltiples representaciones para su modelo Mr-CNN.
Cuando se evalúa en tareas de clasificación de texto con texto de varios conjuntos de datos a gran escala y específicos de dominio, el modelo Mr-CNN logró un desempeño notable, con una mejora máxima de la tasa de error del 13 por ciento en un conjunto de datos y una mejora del 8 por ciento en otro. Esto sugiere que múltiples representaciones de texto permiten a la red enfocar su atención de manera adaptativa en la información más relevante, mejorando sus capacidades de clasificación.
"Varios a gran escala, Se utilizaron conjuntos de datos específicos del dominio para validar la arquitectura propuesta, "escribieron los investigadores." Las tareas analizadas incluyen la clasificación de documentos de ontología, categorización de eventos biomédicos, y análisis de sentimientos, mostrando que las CNN de múltiples representaciones, que aprenden a centrar la atención en representaciones específicas del texto, puede obtener mayores ganancias en el rendimiento sobre los modelos de redes neuronales profundas de última generación ".
En su trabajo futuro, los investigadores planean investigar si las características detalladas pueden ayudar a prevenir el sobreajuste del conjunto de datos de entrenamiento. También quieren explorar otros métodos que podrían mejorar el análisis de partes específicas de oraciones, potencialmente mejorando aún más el rendimiento del modelo.
© 2019 Science X Network