Crédito:Petr Kratochvil / dominio público
En un mundo de Deep Fakes y una IA de lenguaje natural demasiado humana, Investigadores de la Escuela de Ingeniería y Ciencias Aplicadas (SEAS) de Harvard John A. Paulson e IBM Research preguntaron:¿Existe una mejor manera de ayudar a las personas a detectar texto generado por IA?
Esa pregunta llevó a Sebastian Gehrmann, un doctorado candidato a SEAS, y Hendrik Strobelt, investigador de IBM, para desarrollar un método estadístico, junto con una herramienta interactiva de acceso abierto, para detectar texto generado por IA.
Los generadores de lenguaje natural están entrenados en decenas de millones de textos en línea e imitan el lenguaje humano al predecir las palabras que con mayor frecuencia se suceden. Por ejemplo, las palabras "tengo", "soy" y "era" tienen más probabilidades estáticas de ir después de la palabra "yo".
Usando esa idea, Gehrmann y Strobelt desarrollaron un método que, en lugar de identificar errores en el texto, identifica texto que es demasiado predecible.
"La idea que teníamos es que a medida que los modelos mejoran cada vez más, van desde definitivamente peor que los humanos, que es detectable, tan bueno o mejor que los humanos, que puede ser difícil de detectar con enfoques convencionales, "dijo Gehrmann.
"Antes, por todos los errores se podía decir que el texto fue generado por una máquina, "dijo Strobelt." Ahora, ya no son los errores, sino el uso de palabras muy probables (y algo aburridas) que llaman al texto generado por la máquina. Con esta herramienta, los humanos y la IA pueden trabajar juntos para detectar texto falso ".
Gehrmann y Strobelt presentarán su investigación, que fue coautor de Alexander Rush, Asociado en Ciencias de la Computación en SEAS, en la conferencia de la Asociación de Lingüística Computacional (ACL) del 28 de julio al 2 de agosto.
Método de Gehrmann y Strobelt, conocido como GLTR, se basa en un modelo formado en 45 millones de textos de sitios web, la versión pública del modelo OpenAI, GPT-2. Debido a que usa GPT-2 para detectar texto generado, GLTR funciona mejor contra GPT-2, pero también le va bien frente a otros modelos.
Así es como funciona:
Si introduce un pasaje de texto en la herramienta, resalta el texto en verde, amarillo, rojo o morado, cada color significa la previsibilidad de la palabra en el contexto de la palabra anterior. Verde significa que la palabra era muy predecible, amarillo, moderadamente predecible, el rojo no es muy predecible y el violeta significa que el modelo no habría predicho la palabra en absoluto.
Entonces, un párrafo de texto generado por GPT-2 se verá así:

Crédito:Universidad de Harvard
Comparar, esto es real New York Times artículo:
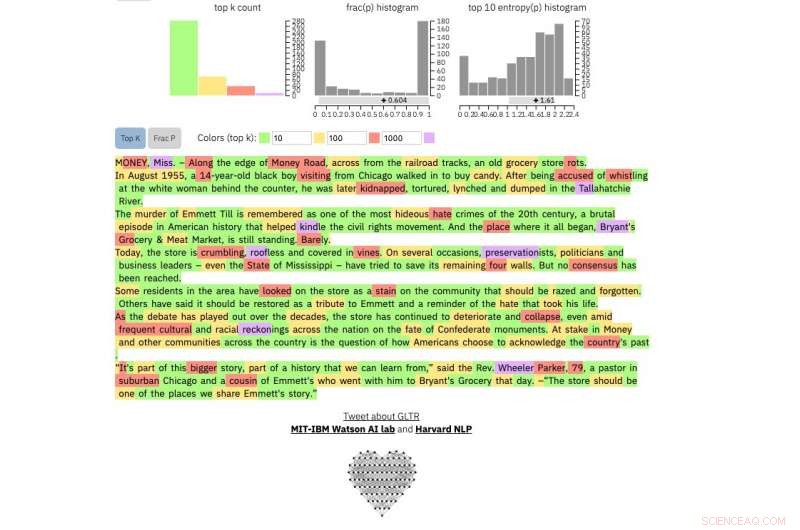
Crédito:Universidad de Harvard
Y este es un extracto de posiblemente el texto humano más impredecible jamás escrito, De James Joyce Finnegans Wake :
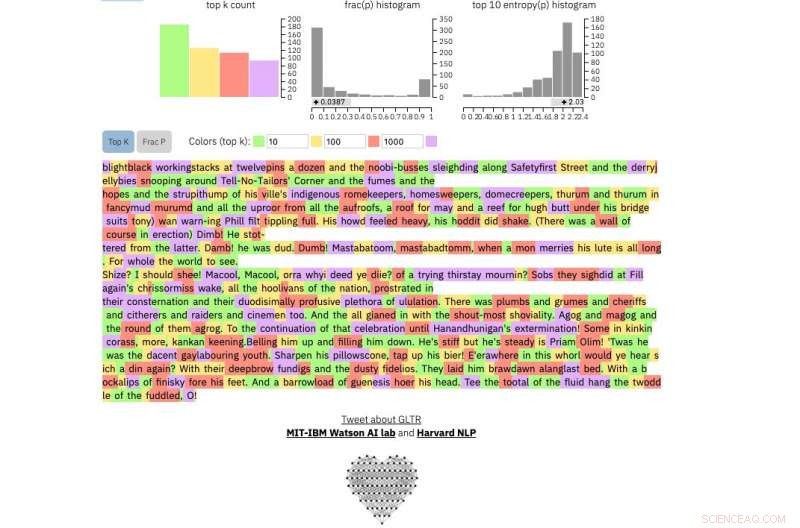
Crédito:Universidad de Harvard
El método no está destinado a reemplazar a los humanos en la identificación de textos falsos, sino a apoyar la intuición y la comprensión humanas. Los investigadores probaron el modelo con un grupo de estudiantes universitarios en una clase de Ciencias de la Computación de SEAS.
Sin el modelo, los estudiantes pudieron identificar alrededor del 50 por ciento del texto generado por IA. Con la superposición de colores, los estudiantes pudieron identificar el 72 por ciento.
Gehrmann y Strobelt dicen que con un poco de capacitación y experiencia con el programa, el número podría mejorar aún más.
"Nuestro objetivo es crear sistemas de colaboración humana y de inteligencia artificial, ", dijo Gehrmann." Esta investigación tiene como objetivo brindar a los humanos más información para que puedan tomar una decisión informada sobre lo que es real y lo que es falso ".