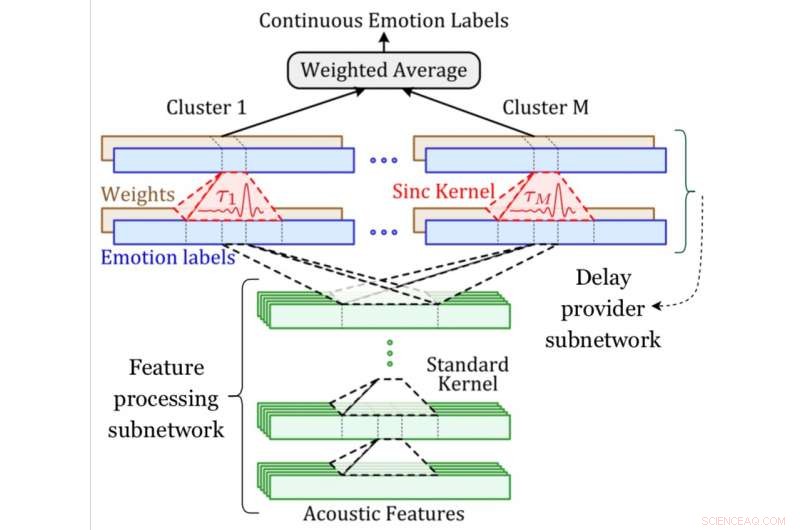
Un diagrama de sistema de la red MDS. Crédito:Khorram, McInnis y Provost.
Los modelos de aprendizaje automático que pueden reconocer y predecir las emociones humanas se han vuelto cada vez más populares en los últimos años. Para que la mayoría de estas técnicas funcionen bien, sin embargo, los datos utilizados para entrenarlos son anotados primero por sujetos humanos. Es más, las emociones cambian continuamente con el tiempo, lo que hace que la anotación de videos o grabaciones de voz sea particularmente desafiante, a menudo resulta en discrepancias entre etiquetas y grabaciones.
Para abordar esta limitación, Investigadores de la Universidad de Michigan han desarrollado recientemente una nueva red neuronal convolucional que puede alinear y predecir simultáneamente las anotaciones emocionales de un extremo a otro. Presentaron su técnica, llamada red de sincronización de retardo múltiple (MDS), en un artículo publicado en Transacciones IEEE sobre computación afectiva .
"La emoción varía continuamente en el tiempo; refluye y fluye en nuestras conversaciones" Emily Mower Provost, uno de los investigadores que realizó el estudio, dijo a TechXplore. "En Ingeniería, a menudo usamos descripciones continuas de la emoción para medir cómo varía la emoción. Entonces, nuestro objetivo es predecir estas medidas continuas a partir del habla. Pero hay una trampa. Uno de los mayores desafíos al trabajar con descripciones continuas de emociones es que requiere que tengamos etiquetas que varíen continuamente en el tiempo. Esto lo hacen equipos de anotadores humanos. Sin embargo, las personas no son máquinas ".
Como continúa explicando Mower Provost, Los anotadores humanos a veces pueden estar más sintonizados con señales emocionales particulares (por ejemplo, la risa), pero pierdo el significado detrás de otras señales (por ejemplo, un suspiro exasperado). Además de esto, los humanos pueden tardar algún tiempo en procesar una grabación, y por lo tanto, sus reacciones a las señales emocionales a veces se retrasan. Como resultado, Las etiquetas de emociones continuas pueden presentar mucha variación y, a veces, están desalineadas con el habla en los datos.
En su estudio, Mower Provost y sus colegas abordaron directamente estos desafíos, centrándose en dos medidas continuas de emoción:positividad (valencia) y energía (activación / excitación). Introdujeron la red de sincronización de retardo múltiple, un nuevo método para manejar la desalineación entre el habla y las anotaciones continuas que reacciona de manera diferente a diferentes tipos de señales acústicas.
"Descripciones dimensionales continuas en el tiempo de las emociones (p. Ej., excitación, valencia) proporcionan información detallada sobre los cambios a corto plazo y las tendencias a largo plazo en la expresión de las emociones, "Soheil Khorram, otro investigador involucrado en el estudio, dijo a TechXplore. "El objetivo principal de nuestro estudio fue desarrollar un sistema de reconocimiento automático de emociones que sea capaz de estimar las emociones dimensionales continuas en el tiempo a partir de señales de voz. Este sistema podría tener una serie de aplicaciones del mundo real en diferentes campos, incluida la interacción humano-computadora, e-learning, márketing, cuidado de la salud, entretenimiento y derecho ".
La red convolucional desarrollada por Mower Provost, Khorram y sus colegas tienen dos componentes clave, uno para la predicción de emociones y otro para la alineación. El componente de predicción de emociones es una arquitectura convolucional común entrenada para identificar la relación entre las características acústicas y las etiquetas de las emociones.
El componente de alineación, por otra parte, es la nueva capa introducida por los investigadores (es decir, la capa de sincronización retardada), que aplica un cambio de tiempo que se puede aprender a una señal acústica. Los investigadores compensaron la variación en los retrasos incorporando varias de estas capas.
"Un desafío importante en el desarrollo de sistemas automáticos para predecir etiquetas de emociones continuas en el tiempo a partir del habla es que estas etiquetas generalmente no están sincronizadas con el habla de entrada, ", Explicó Khorram." Esto se debe principalmente a los retrasos causados por el tiempo de reacción, que es inherente a las evaluaciones humanas. En contraste con otros enfoques, nuestra red neuronal convolucional es capaz de alinear y predecir etiquetas simultáneamente de un extremo a otro. La red de sincronización de retardo múltiple aprovecha los conceptos tradicionales de procesamiento de señales (es decir, filtrado de sincronización) en las arquitecturas modernas de aprendizaje profundo para abordar el problema del retardo de reacción ".
Los investigadores evaluaron su técnica en una serie de experimentos utilizando dos conjuntos de datos disponibles públicamente, a saber, los conjuntos de datos RECOLA y SEWA. Descubrieron que compensar los retrasos en la reacción de los anotadores mientras entrenaban su modelo de reconocimiento de emociones conducía a mejoras significativas en la precisión del reconocimiento de emociones del modelo.
También observaron que los retrasos en la reacción de los anotadores al definir etiquetas de emociones continuas no suelen superar los 7,5 segundos. Finalmente, sus hallazgos sugieren que las partes del habla que incluyen la risa generalmente requieren componentes de retraso más pequeños en comparación con las marcadas por otras señales emocionales. En otras palabras, A menudo, es más fácil para los anotadores definir etiquetas de emoción en segmentos del discurso que incluyen la risa.
"La emoción está en todas partes y es fundamental para nuestra comunicación, ", Dijo Mower Provost." Estamos construyendo sistemas de reconocimiento de emociones robustos y generalizables para que las personas puedan acceder y utilizar fácilmente esta información. Parte de este objetivo se logra mediante la creación de algoritmos que puedan utilizar de forma eficaz grandes fuentes de datos externas, ambos etiquetados y no, y modelando eficazmente las dinámicas naturales que forman parte de cómo nos comunicamos emocionalmente. La otra parte se logra al dar sentido a toda la complejidad inherente a las propias etiquetas ".
Aunque Mower Provost, Khorram y sus colegas aplicaron su técnica a tareas de reconocimiento de emociones, También podría usarse para mejorar otras aplicaciones de aprendizaje automático en las que las entradas y salidas no están perfectamente alineadas. En su trabajo futuro, los investigadores planean continuar investigando formas en las que las etiquetas de emociones producidas por los anotadores humanos se pueden integrar de manera eficiente en los datos.
"Usamos un filtro de sincronización para aproximar la función delta de Dirac y compensar los retrasos. Sin embargo, otras funciones, como gaussiano y triangular, también se puede utilizar en lugar del kernel de sincronización, ", Dijo Khorram." Nuestro trabajo futuro explorará el efecto de usar diferentes tipos de núcleos que pueden aproximarse a la función delta de Dirac. Adicionalmente, En este artículo nos centramos en la modalidad del habla para predecir las anotaciones emocionales continuas, mientras que la red de sincronización de retardo múltiple propuesta también es una técnica de modelado razonable para otras modalidades de entrada. Otro plan futuro es evaluar el desempeño de la red propuesta sobre otras modalidades fisiológicas y conductuales como:video, lenguaje corporal y electroencefalograma ".
© 2019 Science X Network