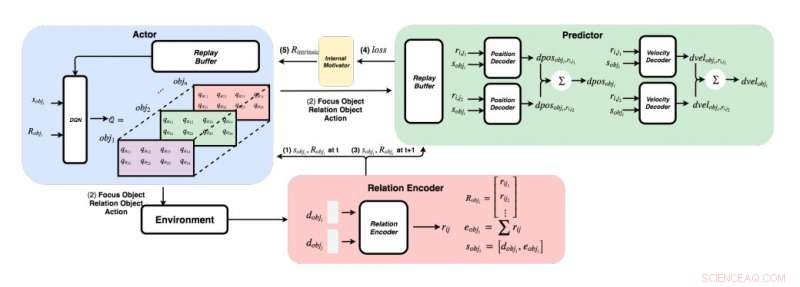
Un diagrama detallado del enfoque desarrollado por los investigadores. (Abajo a la derecha) Para cada par de objetos, los investigadores introducen sus características en un codificador de relaciones para obtener la relación rij y el estado sobji del objeto i. (Arriba a la izquierda) Usando el método codicioso, para cada objeto, encuentran el valor máximo de Q para obtener nuestro objeto de enfoque, objeto de relación, y acción. (Arriba a la derecha) Una vez que reunieron su objeto de enfoque y su objeto de relación, alimentan sus estados y todas sus relaciones a sus decodificadores para predecir el cambio de posición y el cambio de velocidad. Crédito:Choi &Yoon.
Desde sus primeros años de vida, los seres humanos tienen la capacidad innata de aprender continuamente y construir modelos mentales del mundo, simplemente observando e interactuando con cosas o personas en su entorno. Los estudios de psicología cognitiva sugieren que los seres humanos hacen un uso extensivo de este conocimiento previamente adquirido, particularmente cuando se encuentran con situaciones nuevas o cuando toman decisiones.
A pesar de los importantes avances recientes en el campo de la inteligencia artificial (IA), la mayoría de los agentes virtuales aún requieren cientos de horas de capacitación para lograr un desempeño a nivel humano en varias tareas, mientras que los humanos pueden aprender a completar estas tareas en unas pocas horas o menos. Estudios recientes han destacado dos contribuyentes clave a la capacidad de los seres humanos para adquirir conocimientos con tanta rapidez, a saber, física intuitiva y psicología intuitiva.
Estos modelos de intuición, que se han observado en humanos desde las primeras etapas de desarrollo, podrían ser los facilitadores centrales del aprendizaje futuro. Basado en esta idea, Los investigadores del Instituto Avanzado de Ciencia y Tecnología de Corea (KAIST) han desarrollado recientemente un método de normalización de recompensa intrínseca que permite a los agentes de IA seleccionar las acciones que más mejoran sus modelos de intuición. En su papel prepublicado en arXiv, Los investigadores propusieron específicamente una red de física gráfica integrada con un aprendizaje de refuerzo profundo inspirado en el comportamiento de aprendizaje observado en los bebés humanos.
"Imagínese bebés humanos en una habitación con juguetes tirados a una distancia accesible, "explican los investigadores en su artículo." Están constantemente agarrando, lanzar y realizar acciones sobre objetos; algunas veces, observan las secuelas de sus acciones, pero a veces, pierden interés y pasan a un objeto diferente. El punto de vista del `` niño como científico '' sugiere que los bebés humanos están intrínsecamente motivados para realizar sus propios experimentos, descubrir más información, y eventualmente aprender a distinguir diferentes objetos y crear representaciones internas más ricas de ellos ".
Los estudios de psicología sugieren que en sus primeros años de vida, los humanos están experimentando continuamente con su entorno, y esto les permite formar una comprensión clave del mundo. Es más, cuando los niños observan resultados que no cumplen con sus expectativas previas, que se conoce como violación de expectativas, a menudo se les anima a experimentar más para lograr una mejor comprensión de la situación en la que se encuentran.
El equipo de investigadores de KAIST intentó reproducir estos comportamientos en agentes de inteligencia artificial utilizando un enfoque de aprendizaje por refuerzo. En su estudio, Primero introdujeron una red de física gráfica que puede extraer relaciones físicas entre objetos y predecir sus comportamientos posteriores en un entorno 3-D. Después, integraron esta red con un modelo de aprendizaje de refuerzo profundo, introduciendo una técnica de normalización de recompensa intrínseca que alienta a un agente de IA a explorar e identificar acciones que mejorarán continuamente su modelo de intuición.
Usando un motor de física 3-D, los investigadores demostraron que su red de física gráfica puede inferir de manera eficiente las posiciones y velocidades de diferentes objetos. También encontraron que su enfoque permitió que la red de aprendizaje por refuerzo profundo mejorara continuamente su modelo de intuición, animarlo a interactuar con objetos basándose únicamente en la motivación intrínseca.
En una serie de evaluaciones, la nueva técnica ideada por este equipo de investigadores logró una precisión notable, con el agente de IA realizando un mayor número de acciones exploratorias diferentes. En el futuro, podría informar el desarrollo de herramientas de aprendizaje automático que pueden aprender de sus experiencias pasadas de forma más rápida y eficaz.
"Hemos probado nuestra red en problemas estacionarios y no estacionarios en varias escenas con objetos esféricos con masas y radios variables, ", explican los investigadores en su artículo. Nuestra esperanza es que estos modelos de intuición pre-entrenados se utilicen más adelante como conocimiento previo para otras tareas orientadas a objetivos, como los juegos ATARI o la predicción de video".
© 2019 Science X Network