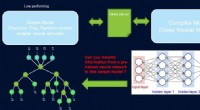
Los investigadores de Berkeley Lab descubrieron que la extracción de textos de resúmenes de ciencia de materiales podría generar nuevos materiales termoeléctricos. Crédito:Berkeley Lab
Seguro, Las computadoras se pueden usar para jugar ajedrez de nivel de gran maestro (chess_computer), pero ¿pueden hacer descubrimientos científicos? Investigadores del Laboratorio Nacional Lawrence Berkeley (Berkeley Lab) del Departamento de Energía de EE. UU. Han demostrado que un algoritmo sin formación en ciencia de materiales puede escanear el texto de millones de artículos y descubrir nuevos conocimientos científicos.
Un equipo dirigido por Anubhav Jain, un científico de la División de Recursos Distribuidos y Almacenamiento de Energía de Berkeley Lab, recopiló 3,3 millones de resúmenes de artículos científicos de materiales publicados y los introdujo en un algoritmo llamado Word2vec. Al analizar las relaciones entre palabras, el algoritmo pudo predecir los descubrimientos de nuevos materiales termoeléctricos con años de anticipación y sugerir materiales aún desconocidos como candidatos para materiales termoeléctricos.
"Sin decirle nada sobre la ciencia de los materiales, aprendió conceptos como la tabla periódica y la estructura cristalina de los metales, "dijo Jain." Eso insinuó el potencial de la técnica. Pero probablemente lo más interesante que descubrimos es, puede utilizar este algoritmo para abordar las lagunas en la investigación de materiales, cosas que la gente debería estudiar pero que no ha estudiado hasta ahora ".
Los hallazgos aparecen en la edición del 3 de julio de la revista Naturaleza . El autor principal del estudio, "Las incrustaciones de palabras no supervisadas capturan el conocimiento latente de la literatura de ciencia de materiales, "es Vahe Tshitoyan, becario postdoctoral de Berkeley Lab que ahora trabaja en Google. Junto con Jain, Los científicos de Berkeley Lab, Kristin Persson y Gerbrand Ceder, ayudaron a dirigir el estudio.
"El documento establece que la extracción de textos de la literatura científica puede descubrir conocimientos ocultos, y que la extracción pura basada en texto puede establecer conocimientos científicos básicos, "dijo Ceder, quien también tiene una cita en el Departamento de Ciencia e Ingeniería de Materiales de UC Berkeley.
Tshitoyan dijo que el proyecto fue motivado por la dificultad de dar sentido a la abrumadora cantidad de estudios publicados. "En cada campo de investigación hay 100 años de literatura de investigación anterior, y cada semana salen decenas de estudios más, ", dijo." Un investigador sólo puede acceder a una fracción de eso. Pensamos ¿Puede el aprendizaje automático hacer algo para hacer uso de todo este conocimiento colectivo de manera no supervisada, sin necesidad de la orientación de investigadores humanos? "
'Rey-reina + hombre =?'
El equipo recopiló los 3,3 millones de resúmenes de artículos publicados en más de 1, 000 revistas entre 1922 y 2018. Word2vec tomó cada una de las aproximadamente 500, 000 palabras distintas en esos resúmenes y convirtieron cada una en un vector de 200 dimensiones, o una matriz de 200 números.
"Lo importante no es cada número, pero usando los números para ver cómo se relacionan las palabras entre sí, "dijo Jain, quien dirige un grupo que trabaja en el descubrimiento y diseño de nuevos materiales para aplicaciones energéticas utilizando una combinación de teoría, cálculo, y minería de datos. "Por ejemplo, puede restar vectores usando matemáticas vectoriales estándar. Otros investigadores han demostrado que si entrena el algoritmo en fuentes de texto no científicas y toma el vector que resulta de 'rey menos reina, 'obtienes el mismo resultado que' hombre menos mujer '. Se da cuenta de la relación sin que le digas nada ".
Similar, cuando se capacita en textos de ciencia de materiales, el algoritmo pudo aprender el significado de términos y conceptos científicos tales como la estructura cristalina de los metales basándose simplemente en las posiciones de las palabras en los resúmenes y su co-ocurrencia con otras palabras. Por ejemplo, al igual que podría resolver la ecuación "rey-reina + hombre, "podría darse cuenta de que para la ecuación" ferromagnético — NiFe + IrMn "la respuesta sería" antiferromagnético ".
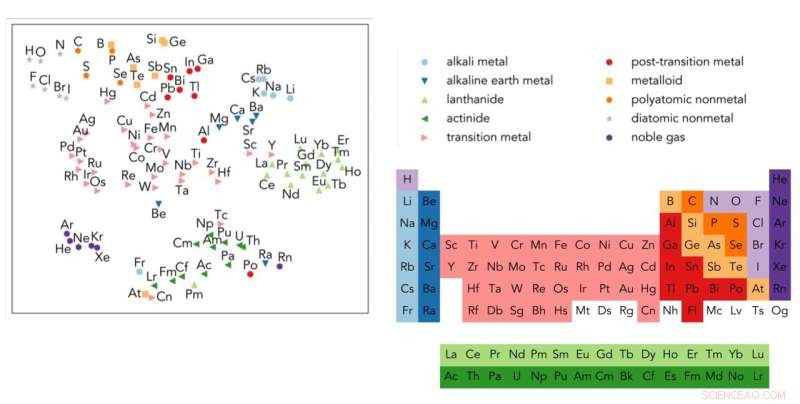
La tabla periódica de Mendeleev está a la derecha. Representación de Word2vec de los elementos, proyectado en dos dimensiones, está a la izquierda. Crédito:Berkeley Lab
Word2vec incluso pudo aprender las relaciones entre los elementos de la tabla periódica cuando el vector de cada elemento químico se proyectaba en dos dimensiones.
Predecir descubrimientos con años de anticipación
Entonces, si Word2vec es tan inteligente, ¿Podría predecir nuevos materiales termoeléctricos? Un buen material termoeléctrico puede convertir eficientemente el calor en electricidad y está hecho de materiales que son seguros. abundante y fácil de producir.
El equipo de Berkeley Lab tomó los mejores candidatos termoeléctricos sugeridos por el algoritmo, que clasificaba cada compuesto por la similitud de su vector de palabra con el de la palabra "termoeléctrico". Luego realizaron cálculos para verificar las predicciones del algoritmo.
De las 10 predicciones principales, encontraron que todos habían calculado factores de potencia ligeramente más altos que el promedio de los termoeléctricos conocidos; los tres primeros candidatos tenían factores de potencia por encima del percentil 95 de las termoeléctricas conocidas.
A continuación, probaron si el algoritmo podía realizar experimentos "en el pasado" dándole resúmenes solo hasta, decir, el año 2000. Una vez más, de las principales predicciones, un número significativo apareció en estudios posteriores, cuatro veces más que si los materiales se hubieran elegido al azar. Por ejemplo, Desde entonces se han descubierto tres de las cinco predicciones principales entrenadas con datos hasta el año 2008 y las dos restantes contienen elementos raros o tóxicos.
Los resultados fueron sorprendentes. "Honestamente, no esperaba que el algoritmo fuera tan predictivo de resultados futuros, "Dijo Jain." Había pensado que tal vez el algoritmo podría ser descriptivo de lo que la gente había hecho antes, pero no llegar a estas conexiones diferentes. Me sorprendió bastante cuando vi no solo las predicciones, sino también el razonamiento detrás de las predicciones, cosas como la estructura de medio Heusler, que es una estructura cristalina realmente caliente para termoeléctricas en estos días ".
Añadió:"Este estudio muestra que si este algoritmo se hubiera implementado antes, algunos materiales podrían haberse descubierto con años de anticipación ". Junto con el estudio, los investigadores están lanzando los 50 materiales termoeléctricos principales predichos por el algoritmo. También lanzarán las incrustaciones de palabras necesarias para que las personas hagan sus propias aplicaciones si lo desean para buscar decir, un mejor material aislante topológico.
Hasta la próxima, Jain dijo que el equipo está trabajando en una motor de búsqueda más potente, permitiendo a los investigadores buscar resúmenes de una manera más útil.
El estudio fue financiado por Toyota Research Institute. Otros coautores del estudio son los investigadores de Berkeley Lab, John Dagdelen, Leigh Weston, Alexander Dunn, y Ziqin Rong, y la investigadora de UC Berkeley Olga Kononova.