Crédito:IBM
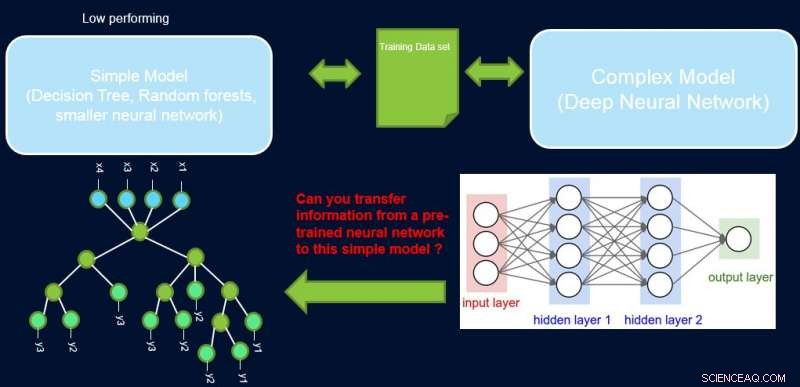
La interpretabilidad y el rendimiento de un sistema suelen estar en desacuerdo entre sí, ya que muchos de los modelos de mejor rendimiento (es decir, redes neuronales profundas) son de caja negra por naturaleza. En nuestro trabajo, Mejora de modelos simples con perfiles de confianza, intentamos cerrar esta brecha proponiendo un método para transferir información desde una red neuronal de alto rendimiento a otro modelo que el experto en el dominio o la aplicación puedan exigir. Por ejemplo, en biología y economía computacional, a menudo se prefieren los modelos lineales dispersos, mientras que en dominios instrumentados complejos como la fabricación de semiconductores, los ingenieros pueden preferir utilizar árboles de decisión. Estos modelos interpretables más simples pueden generar confianza con el experto y proporcionar información útil que lleve al descubrimiento de hechos nuevos y previamente desconocidos. Nuestro objetivo se muestra gráficamente a continuación, para un caso específico en el que intentamos mejorar el rendimiento de un árbol de decisiones.
El supuesto es que nuestra red es un profesor de alto rendimiento, y podemos usar parte de su información para enseñar lo simple, interpretable, pero, en general, modelo de estudiante de bajo rendimiento. La ponderación de las muestras por su dificultad puede ayudar al modelo simple a centrarse en muestras más sencillas que puede modelar con éxito durante el entrenamiento. y así lograr un mejor rendimiento general. Nuestra configuración es diferente de impulsar:en ese enfoque, Se destacan ejemplos difíciles con respecto a un alumno "débil" anterior para la formación posterior a fin de crear diversidad. Aquí, son ejemplos difíciles con respecto a un modelo complejo preciso. Esto significa que estas etiquetas son casi aleatorias. Es más, si un modelo complejo no puede resolverlos, hay pocas esperanzas para el modelo simple de complejidad fija. Por eso, Es importante en nuestra configuración resaltar ejemplos sencillos que el modelo simple puede resolver.
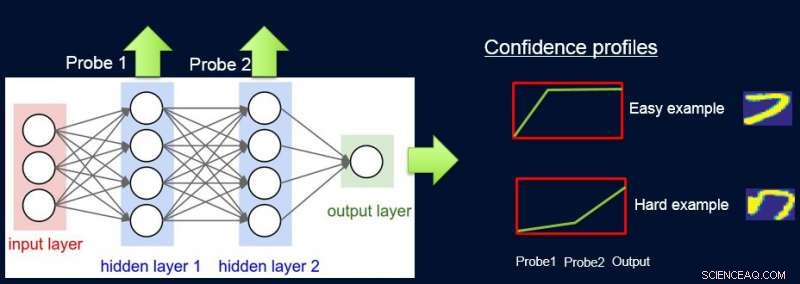
Para hacer esto, asignamos pesos a las muestras según la dificultad de la red para clasificarlas, y lo hacemos introduciendo sondas. Cada sonda toma su información de una de las capas ocultas. Cada sonda tiene una única capa completamente conectada con una capa softmax del tamaño de la salida de red adjunta. La sonda en la capa i sirve como clasificador que solo usa el prefijo de la red hasta la capa i. El supuesto es que las instancias fáciles se clasificarán correctamente con alta confianza incluso con sondas de primera capa, y así obtenemos niveles de confianza p I de todas las sondas para cada una de las instancias. Usamos todo p I para calcular la dificultad de la instancia w I , p.ej. como el área bajo la curva (AUC) de p I 's.
Ahora podemos usar las ponderaciones para volver a entrenar el modelo simple en el conjunto de datos ponderado final. Llamamos a esta tubería de sondeo, obtener ponderaciones de confianza, y reentrenamiento de ProfWeight.
Crédito:IBM
Presentamos dos alternativas sobre cómo calculamos los pesos de los ejemplos en el conjunto de datos. En el enfoque AUC mencionado anteriormente, notamos el error de validación / precisión del modelo simple cuando se entrena en el conjunto de entrenamiento original. Seleccionamos sondas que tienen una precisión de al menos α (> 0) mayor que el modelo simple. Cada ejemplo se pondera en función de la puntuación de confianza promedio para la etiqueta verdadera que se calcula utilizando las predicciones suaves individuales de las sondas.
Una segunda alternativa implica la optimización mediante una red neuronal. Aquí aprendemos los pesos óptimos para el conjunto de entrenamiento optimizando el siguiente objetivo:
S * =min w min β E [λ (Swβ (x), y)], sub. para. E [w] =1
donde w son los pesos que se encontrarán para cada instancia, β denota el espacio de parámetros del modelo simple S, y λ es su función de pérdida. Necesitamos restringir los pesos, ya que de lo contrario la solución trivial de todos los pesos que van a cero será óptima para el objetivo anterior. Mostramos en el artículo que nuestra restricción de E [w] =1 tiene una conexión para encontrar el muestreo de importancia óptimo.
Crédito:IBM
De manera más general, ProfWeight se puede usar para transferir a modelos aún más simples pero opacos, como redes neuronales más pequeñas, que puede ser útil en dominios con graves limitaciones de memoria y energía. Estas limitaciones se experimentan al implementar modelos en dispositivos de borde en sistemas de IoT o en dispositivos móviles o en vehículos aéreos no tripulados.
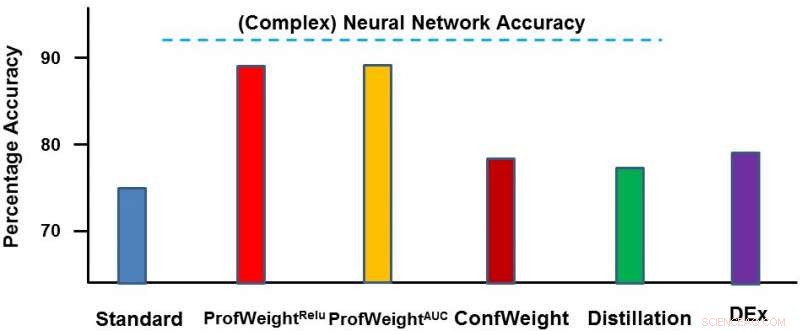
Probamos nuestro método en dos dominios:un conjunto de datos de imágenes públicas CIFAR-10 y un conjunto de datos de fabricación patentado. En el primer conjunto de datos, Nuestros modelos simples eran redes neuronales más pequeñas que cumplirían con estrictas restricciones de memoria y energía y donde vimos una mejora del 3 al 4 por ciento. En el segundo conjunto de datos, nuestro modelo simple era un árbol de decisiones y lo mejoramos significativamente en aproximadamente un 13 por ciento, lo que condujo a resultados procesables por parte del ingeniero. A continuación, mostramos ProfWeight en comparación con los otros métodos de este conjunto de datos. Observamos aquí que superamos a los otros métodos por bastante margen.
En el futuro, nos gustaría encontrar las condiciones necesarias / suficientes cuando la transferencia mediante nuestra estrategia daría como resultado la mejora de modelos simples. También nos gustaría desarrollar métodos más sofisticados para la transferencia de información que los que ya hemos logrado.
Presentaremos este trabajo en un artículo titulado "Mejora de modelos simples con perfiles de confianza" en la Conferencia de 2018 sobre sistemas de procesamiento de información neuronal, El miércoles, 5 de diciembre durante la sesión de carteles de la tarde de 5:00 a 7:00 pm en las salas 210 y 230 AB (# 90).
Esta historia se vuelve a publicar por cortesía de IBM Research. Lea la historia original aquí.