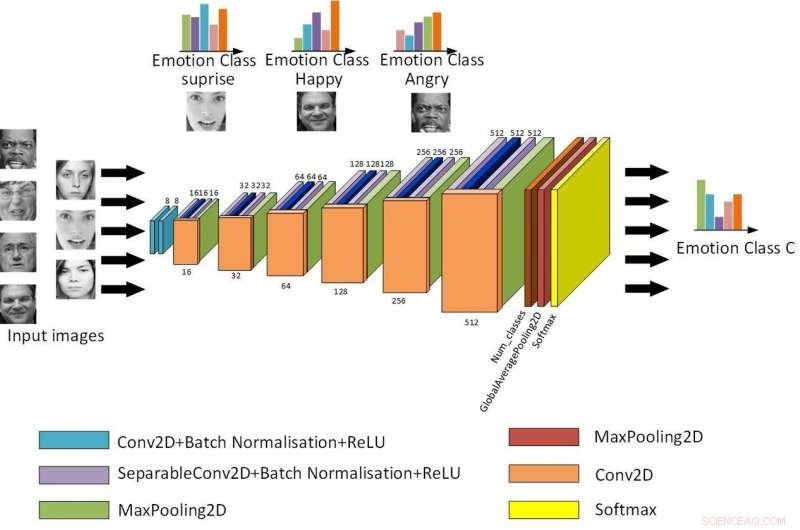
La estructura básica de Light-CNN. Crédito:Jie y Yongsheng.
Dos investigadores de la Universidad de Energía Eléctrica de Shanghai han desarrollado y evaluado recientemente nuevos modelos de redes neuronales para el reconocimiento de expresiones faciales (FER) en la naturaleza. Su estudio, publicado en la revista Neurocomputing de Elsevier, presenta tres modelos de redes neuronales convolucionales (CNN):un Light-CNN, una CNN de doble rama y una CNN previamente capacitada.
"Debido a la falta de información sobre caras no frontales, FER en la naturaleza es un punto difícil en la visión por computadora, "Qian Yongsheng, uno de los investigadores que realizó el estudio, dijo a TechXplore. "Los métodos de reconocimiento de expresiones faciales naturales existentes basados en redes neuronales convolucionales profundas (CNN) presentan varios problemas, incluido el sobreajuste, alta complejidad computacional, característica única y muestras limitadas ".
Aunque muchos investigadores han desarrollado enfoques de CNN para FER, hasta aquí, muy pocos de ellos han intentado determinar qué tipo de red es más adecuada para esta tarea en particular. Consciente de esta brecha en la literatura, Yongsheng y su colega Shao Jie desarrollaron tres CNN diferentes para FER y llevaron a cabo una serie de evaluaciones para identificar sus fortalezas y debilidades.
"Nuestro primer modelo es un CNN de luz superficial que introduce un módulo separable en profundidad con el módulo de red residual, reducir los parámetros de la red cambiando el método de convolución, ", Dijo Yongsheng." La segunda es una CNN de doble rama, que combina características globales y características de textura locales, tratando de obtener características más ricas y compensar la falta de invariancia de rotación de la convolución. La tercera CNN preentrenada utiliza pesos entrenados en la misma base de datos grande distribuida para volver a capacitarse en su propia base de datos pequeña, reduciendo el tiempo de formación y mejorando la tasa de reconocimiento ".
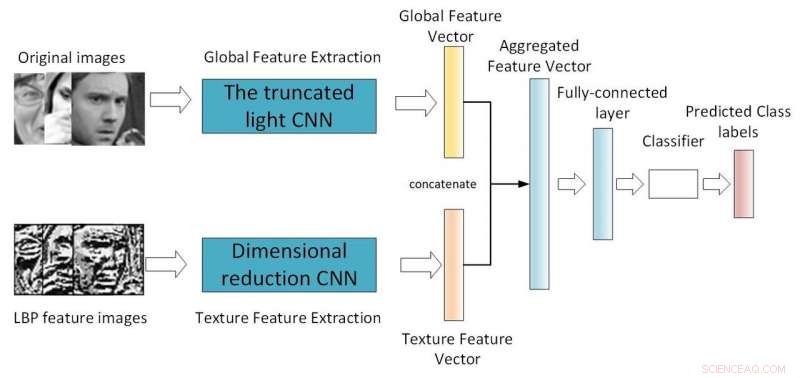
Marco de la CNN de doble rama. Crédito:Jie y Yongsheng.
Los investigadores llevaron a cabo evaluaciones exhaustivas de sus modelos de CNN en tres conjuntos de datos que se utilizan comúnmente para FER:el público CK +, conjuntos de datos de múltiples vistas BU-3DEF y FER2013. Aunque los tres modelos de CNN presentaron diferencias en el rendimiento, todos lograron resultados prometedores, superando varios enfoques de vanguardia para FER.
"En el presente, los tres modelos de CNN se utilizan por separado, "Explicó Yongsheng." La red de poca profundidad es más adecuada para hardware integrado. La CNN previamente entrenada puede lograr mejores resultados, pero requiere pesas previamente entrenadas. La red de doble rama no es muy eficaz. Por supuesto, también se podría intentar utilizar los tres modelos juntos ".
En sus evaluaciones, los investigadores observaron que al combinar el módulo de red residual y el módulo separable en profundidad, como hicieron con su primer modelo de CNN, los parámetros de la red podrían reducirse. En última instancia, esto podría resolver algunas de las deficiencias del hardware informático. Además, encontraron que el modelo de CNN previamente entrenado transfería una gran base de datos a su propia base de datos y, por lo tanto, podía entrenarse con muestras limitadas.
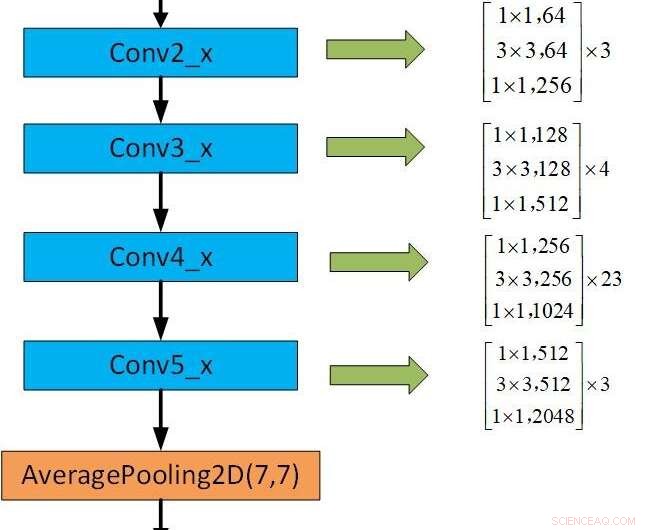
El marco de la CNN preentrenada. Crédito:Jie y Yongsheng.
Las tres CNN para FER propuestas por Yongsheng y Jie podrían tener numerosas aplicaciones, por ejemplo, ayudando al desarrollo de robots que puedan identificar las expresiones faciales de los humanos con los que están interactuando. Los investigadores ahora planean hacer ajustes adicionales a sus modelos, con el fin de mejorar aún más su rendimiento.
"En nuestro trabajo futuro, Intentaremos agregar diferentes funciones manuales tradicionales para unirnos a la CNN de doble rama y cambiar el modo de fusión, Yongsheng dijo:"También usaremos parámetros de red de entrenamiento de bases de datos cruzadas para obtener mejores capacidades de generalización y adoptar un enfoque de aprendizaje de transferencia profunda más efectivo".
© 2019 Science X Network