Crédito:Liu et al.
Investigadores de la Universidad de Leiden y la Universidad Nacional de Tecnología de Defensa (NUDT), en China, han desarrollado recientemente un nuevo enfoque para la coincidencia de texto e imagen, llamado CycleMatch. Su enfoque presentado en un artículo publicado en Elsevier's Reconocimiento de patrones diario, se basa en un aprendizaje consistente en un ciclo, una técnica que a veces se utiliza para entrenar redes neuronales artificiales en tareas de traducción de imagen a imagen. La idea general detrás de la consistencia del ciclo es que cuando se transforman los datos de origen en datos de destino y luego viceversa, finalmente se deben obtener las muestras originales.
Cuando se trata de desarrollar herramientas de inteligencia artificial (IA) que funcionen bien en tareas multimodales o basadas en multimedia, encontrar formas de unir imágenes y representaciones de texto es de crucial importancia. Los estudios anteriores han intentado lograr esto descubriendo la semántica o características que son relevantes tanto para la visión como para el lenguaje.
Al entrenar algoritmos sobre correlaciones entre diferentes modalidades, sin embargo, Estos estudios a menudo han descuidado o no han abordado la coherencia semántica intramodal, que es la consistencia de la semántica para las modalidades individuales (es decir, visión y lenguaje). Para abordar esta deficiencia, El equipo de investigadores de la Universidad de Leiden y NUDT propuso un enfoque que aplica incrustaciones consistentes en ciclos a una red neuronal profunda para hacer coincidir representaciones visuales y textuales.
"Nuestro enfoque, llamado CycleMatch, puede mantener tanto las correlaciones intermodales como la consistencia intramodal mediante la asignación de asignaciones duales en cascada y las asignaciones reconstruidas de forma cíclica, "escribieron los investigadores en su artículo". Además, para lograr una inferencia robusta, proponemos emplear dos enfoques de fusión tardía:fusión media y fusión adaptativa ".
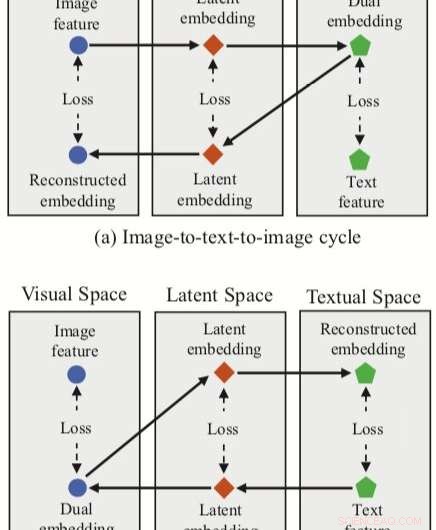
El enfoque ideado por los investigadores integra tres incorporaciones de características (dual, incrustaciones reconstruidas y latentes) con una red neuronal para la coincidencia de texto e imagen. El método tiene dos ramas de ciclo, uno a partir de una característica de imagen en el espacio visual y otro a partir de una característica de texto en el espacio textual.
Para cada uno de estos ciclos, su enfoque logra un mapeo dual, traducir una característica de entrada en el espacio de origen en una incrustación dual en el espacio de destino. Luego, los investigadores aplican el mapeo reconstruido, tratando de traducir esta incrustación dual al espacio fuente.
Su enfoque también permite a los investigadores adquirir un 'espacio latente' durante mapeos duales y reconstruidos, y posteriormente correlacionar las incrustaciones latentes. A diferencia de otras técnicas para la coincidencia de imágenes y texto, por lo tanto, su método puede aprender tanto mapeos intermodales (es decir, imagen a texto y texto a imagen) como mapeos intramodales (imagen a imagen y texto a texto).
Para evaluar su enfoque, los investigadores llevaron a cabo una serie de experimentos utilizando dos conjuntos de datos multimodales de renombre, Flickr30K y MSCOCO. Su método logró resultados de vanguardia, superando los enfoques tradicionales y conduciendo a mejoras significativas en la recuperación transmodal.
Estos hallazgos sugieren que las incrustaciones coherentes con el ciclo podrían mejorar el rendimiento de las redes neuronales en tareas multimodales, como la coincidencia de texto e imagen, permitiéndoles adquirir mapeos intermodales e intramodales. En su trabajo futuro, los investigadores planean desarrollar aún más su enfoque, teniendo en cuenta las relaciones locales al hacer coincidir imágenes y texto (por ejemplo, correlaciones semánticas entre regiones visuales y frases).
© 2019 Science X Network