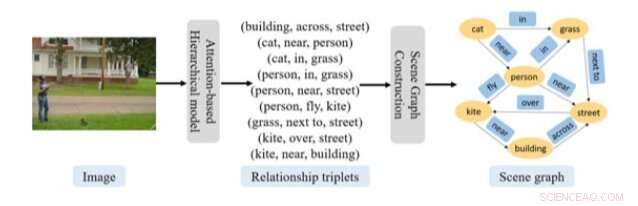
Procedimiento general de predicción del escenario gráfico propuesto en el artículo reciente. Crédito:Gao et al.
Investigadores de la Universidad de Shanghai han desarrollado recientemente un nuevo enfoque basado en redes neuronales recurrentes (RNN) para predecir gráficos de escenas a partir de imágenes. Su enfoque incluye un modelo compuesto por dos enfermeras registradas basadas en la atención, así como un componente de localización de entidades.
Durante la última década más o menos, Los investigadores en el campo de la inteligencia artificial (IA) han desarrollado una variedad de herramientas automáticas para gestionar, analizar y recuperar imágenes digitales. Para representar el contenido de las imágenes, Los enfoques tradicionales suelen utilizar palabras clave o funciones de múltiples vistas. Sin embargo, confiar en funciones o palabras clave a menudo conduce a una comprensión limitada de las imágenes, no proporcionar un conocimiento completo sobre ellos.
Para abordar estas deficiencias, Hace unos pocos años, un equipo de investigadores de la Universidad de Stanford, Instituto Max Planck de Informática, Yahoo Labs y Snapchat propusieron el uso de un 'escenario gráfico, 'un tipo de estructura de datos para describir conceptos visuales en una imagen. Los gráficos de escena pueden almacenar la descripción de una escena representada en imágenes como un gráfico estructurado en el que los nodos representan información del objeto y los bordes proporcionan predicciones entre dos nodos.
Estas representaciones estructuradas pueden ayudar a los usuarios a administrar imágenes digitales. Sin embargo, predecir un gráfico de escena suele ser un desafío, ya que requiere herramientas efectivas para reconocer objetos, así como sus atributos e interacciones entre ellos.
Si bien existen varios enfoques para predecir gráficos de escena, la mayoría de estos tienen limitaciones sustanciales. En su estudio, Los investigadores de la Universidad de Shangai se propusieron desarrollar un modelo basado en redes neuronales para predecir gráficos de escenas desde una perspectiva visual orientada a la atención.
"Un gráfico de escena proporciona una poderosa estructura de conocimiento intermedio para diversas tareas visuales, incluida la recuperación de imágenes semánticas, subtítulos de imágenes, y respuesta visual a preguntas, "escribieron los investigadores en su artículo, que se publicó en Wiley Online Library. "En este papel, la tarea de predecir un escenario gráfico para una imagen se formula como dos problemas conectados, es decir, reconocer la relación de trillizos, estructurado como, y construir el escenario gráfico a partir de los tríos de relaciones reconocidos ".
El enfoque ideado por este equipo de investigadores tiene dos componentes clave, uno dirigido a reconocer lo que ellos llaman "tríos de relaciones" y el otro a construir un escenario gráfico. Para reconocer trillizos de relaciones, los investigadores utilizaron un modelo compuesto por dos enfermeras registradas basadas en la atención en una organización jerárquica.
"La primera red genera un vector de tema para cada triplete de relaciones, mientras que la segunda red predice cada palabra en ese triplete de relación dado el vector de tema, ", explicaron los investigadores en su artículo." Este enfoque captura con éxito la estructura compositiva y la dependencia contextual de una imagen y los tripletes de relaciones que describen su escena ".
Una vez que este modelo basado en RNN ha extraído información relevante de una imagen, el segundo componente de su enfoque utiliza estos datos para construir gráficos de escena. Para este paso, los investigadores utilizaron un enfoque de localización de entidades, que puede determinar la estructura del gráfico utilizando la información de atención disponible. Además de estos dos componentes, los investigadores utilizaron un algoritmo para aclarar el proceso mediante el cual su enfoque convierte la información del triplete de relaciones generada en un gráfico de escena.
Su enfoque se evaluó utilizando el popular conjunto de datos del genoma visual (VG) y el conjunto de datos de relación visual (VRD). Para el propósito de su estudio, los investigadores anotaron las imágenes en estos conjuntos de datos con un conjunto de tripletes, etiquetar cada par de sujeto y objeto con información de ubicación.
"Los resultados de los experimentos en dos conjuntos de datos populares demuestran que el enfoque jerárquico recurrente desde la perspectiva orientada a la atención visual dentro de nuestro modelo tiene una clara mejora en los resultados con respecto a los modelos de referencia, "escribieron los investigadores." En trabajos futuros, planeamos enriquecer el gráfico de escena con semántica de alto nivel y atributos más diversificados ".
© 2019 Science X Network














