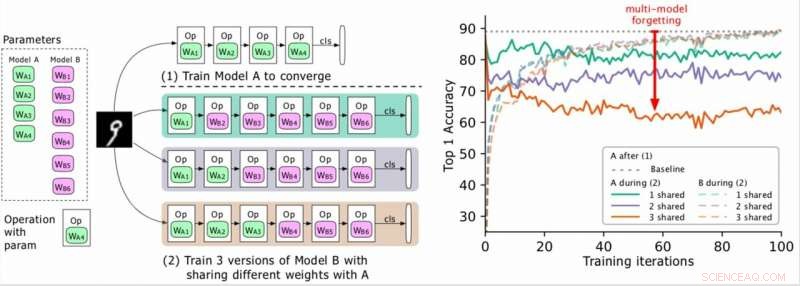
(Izquierda) Dos modelos a entrenar (A, B), donde los parámetros de A están en verde y los de B en violeta, y B comparte algunos parámetros con A (indicado en verde durante la fase 2). Los investigadores primero entrenan a A para la convergencia y luego entrenan a B. (Derecha) Precisión del modelo A a medida que avanza el entrenamiento de B. Los diferentes colores corresponden a diferentes números de capas compartidas. La precisión de A disminuye drásticamente, especialmente cuando se comparten más capas, y los investigadores se refieren a la gota (la flecha roja) como olvido de modelos múltiples. Crédito:Benyahia, Yu y col.
En años recientes, Los investigadores han desarrollado redes neuronales profundas que pueden realizar una variedad de tareas, incluyendo tareas de reconocimiento visual y procesamiento del lenguaje natural (PNL). Aunque muchos de estos modelos lograron resultados notables, por lo general, solo se desempeñan bien en una tarea en particular debido a lo que se conoce como "olvido catastrófico".
Esencialmente, El olvido catastrófico significa que cuando un modelo que se entrenó inicialmente en la tarea A se entrena más tarde en la tarea B, su desempeño en la tarea A disminuirá significativamente. En un artículo publicado previamente en arXiv, Los investigadores de Swisscom y EPFL identificaron un nuevo tipo de olvido y propusieron un nuevo enfoque que podría ayudar a superarlo a través de una pérdida de plasticidad de peso estadísticamente justificada.
"Cuando empezamos a trabajar en nuestro proyecto, diseñar arquitecturas neuronales automáticamente era computacionalmente costoso e inviable para la mayoría de las empresas, "Yassine Benyahia y Kaicheng Yu, los investigadores principales del estudio, dijo a TechXplore por correo electrónico. "El objetivo original de nuestro estudio era identificar nuevos métodos para reducir este gasto. Cuando comenzó el proyecto, un documento de Google afirmó haber reducido drásticamente el tiempo y los recursos necesarios para construir arquitecturas neuronales utilizando un nuevo método llamado peso compartido. Esto hizo que autoML fuera factible para investigadores sin grandes grupos de GPU, animándonos a estudiar este tema más a fondo ".
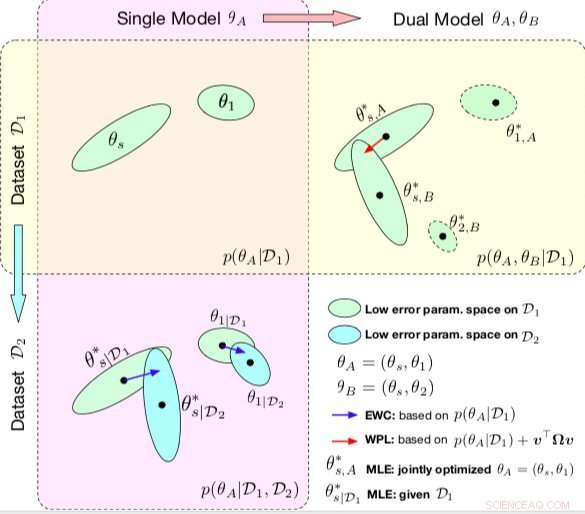
Comparación entre EWC y WPL. Las elipses en cada subparcela representan regiones de parámetros correspondientes a un error bajo. (Arriba a la izquierda) Ambos métodos comienzan con un solo modelo, con parámetros θA ={θs, θ1}, entrenado en un solo conjunto de datos D1. (Abajo a la izquierda) EWC regulariza todos los parámetros basados en p (θA | D1) para entrenar el mismo modelo inicial en un nuevo conjunto de datos D2. (Arriba a la derecha) Por el contrario, WPL hace uso del conjunto de datos inicial D1 y regulariza solo los parámetros compartidos θs basados tanto en p (θA | D1) como en v> Ωv, mientras que los parámetros θ2 pueden moverse libremente. Crédito:Benyahia, Yu y col.
Durante su investigación sobre modelos basados en redes neuronales, Benyahia, Yu y sus colegas notaron un problema con el peso compartido. Cuando entrenaron dos modelos (por ejemplo, A y B) secuencialmente, el rendimiento del modelo A disminuyó, mientras que el rendimiento del modelo B aumentó, o viceversa. Demostraron que este fenómeno, que llamaron "olvido de varios modelos, "puede obstaculizar el rendimiento de varios enfoques de auto-mL, incluida la búsqueda eficiente de arquitectura neuronal (ENAS) de Google.
"Nos dimos cuenta de que compartir el peso estaba provocando que los modelos se impactaran entre sí de forma negativa, lo que provocaba que el proceso de búsqueda de arquitectura fuera más aleatorio, "Benyahia y Yu explicaron." También teníamos nuestras reservas en la búsqueda de arquitectura, donde solo se arrojan a la luz los resultados finales y donde no existe un buen marco para evaluar la calidad de la búsqueda de arquitectura de manera justa. Nuestro enfoque podría ayudar a solucionar este problema de olvido, ya que está relacionado con un método central del que se basan casi todos los artículos recientes de autoML, y consideramos que ese impacto es enorme para la comunidad ".
En su estudio, los investigadores modelaron matemáticamente el olvido multimodelo y obtuvieron una pérdida novedosa, llamado pérdida de plasticidad de peso. Esta pérdida podría reducir sustancialmente el olvido de múltiples modelos al regularizar el aprendizaje de los parámetros compartidos de un modelo de acuerdo con su importancia para los modelos anteriores.
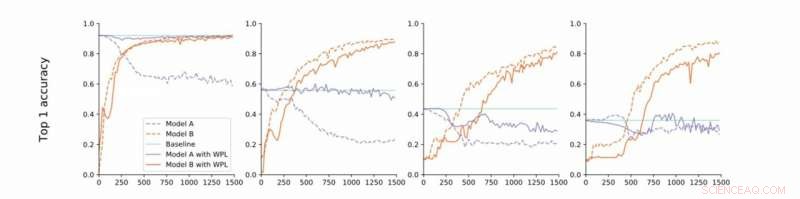
De la convergencia estricta a la flexible. Los investigadores realizan experimentos en MNIST con los modelos A y B con parámetros compartidos e informan la precisión del Modelo A antes de entrenar el Modelo B (línea de base, verde) y la precisión de los Modelos A y B durante el entrenamiento del Modelo B con (naranja) o sin (azul) WPL. En (a) muestran los resultados para la convergencia estricta:A se entrena inicialmente para la convergencia. Luego relajan esta suposición y entrenan a A a alrededor del 55% (b), 43% (c), y 38% (d) de su precisión óptima. WPL es muy eficaz cuando A se entrena al menos al 40% de la optimalidad; debajo, la información de Fisher se vuelve demasiado inexacta para proporcionar ponderaciones de importancia confiables. Por lo tanto, WPL ayuda a reducir el olvido de múltiples modelos, incluso cuando los pesos no son óptimos. WPL redujo el olvido hasta en un 99,99% para (a) y (b), y hasta un 2% para (c). Crédito:Benyahia, Yu y col.
"Básicamente, debido a la parametrización excesiva de las redes neuronales, nuestra pérdida disminuye los parámetros que son 'menos importantes' para la pérdida final primero, y mantiene los más importantes sin cambios, "Benyahia y Yu dijeron." El rendimiento del Model A no se ve afectado, mientras que el rendimiento del modelo B sigue aumentando. En pequeños conjuntos de datos, nuestro modelo puede reducir el olvido hasta en un 99 por ciento, y en los métodos autoML, hasta un 80 por ciento en medio del entrenamiento ".
En una serie de pruebas, los investigadores demostraron la efectividad de su enfoque para disminuir el olvido de modelos múltiples, tanto en casos en los que dos modelos se entrenan secuencialmente como para la búsqueda de arquitectura neuronal. Sus hallazgos sugieren que agregar plasticidad de peso en la búsqueda de arquitectura neuronal puede mejorar significativamente el rendimiento de múltiples modelos en tareas de visión artificial y PNL.
El estudio realizado por Benyahia, Yu y sus colegas arrojan luz sobre la cuestión del olvido catastrófico, particularmente lo que ocurre cuando varios modelos se entrenan secuencialmente. Después de modelar matemáticamente este problema, los investigadores introdujeron una solución que podría superarlo, o al menos reducir drásticamente su impacto.
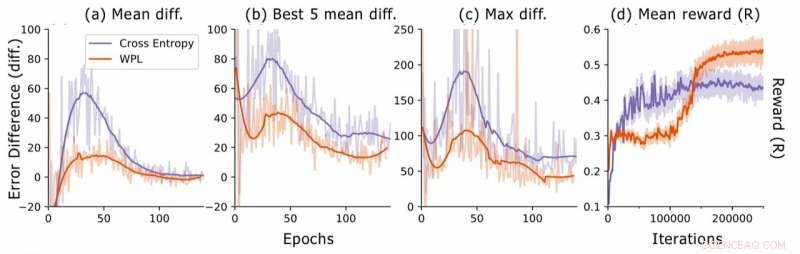
Diferencia de error durante la búsqueda de arquitectura neuronal. Para cada arquitectura, los investigadores calculan las diferencias de error RNN err2 − err1, donde err1 es el error justo después de entrenar esta arquitectura y err2 el que aparece después de que todas las arquitecturas se entrenan en la época actual. Trazan (a) la diferencia media entre todos los modelos muestreados, (b) la diferencia media entre los 5 modelos con menor err1, y (c) la máxima diferencia entre todos los modelos. En (d), trazan la recompensa promedio de las arquitecturas muestreadas en función de las iteraciones de entrenamiento. Aunque WPL inicialmente conduce a recompensas más bajas, debido a un gran peso α en la ecuación (8), al reducir el olvido, permite que el controlador muestree mejores arquitecturas, como lo indica la recompensa más alta en la segunda mitad. Crédito:Benyahia, Yu y col.
"En el olvido de varios modelos, Nuestro principio rector era pensar en fórmulas y no solo por simple intuición o heurística, Benyahia y Yu dijeron. Creemos firmemente que este 'pensar en fórmulas' puede llevar a los investigadores a grandes descubrimientos. Es por eso que para futuras investigaciones, Nuestro objetivo es aplicar este enfoque a otros campos del aprendizaje automático. Además, planeamos adaptar nuestra pérdida a los métodos de autoML de última generación para demostrar su eficacia en la solución del problema de reparto de peso observado por nosotros ".
© 2019 Science X Network