Crédito:CC0 Public Domain
Un equipo de investigadores de la UC Santa Cruz ha desarrollado recientemente un nuevo enfoque de aprendizaje automático para caracterizar la felicidad, llamado CruzAffect. Su enfoque presentado en un artículo publicado previamente en arXiv, se puede aplicar a diferentes modelos de clasificación de contenido afectivo, incluyendo clasificadores tradicionales y redes neuronales convolucionales de aprendizaje profundo (CNN).
Este estudio reciente se basa en investigaciones anteriores que exploraron cómo las personas transmiten afecto y felicidad en primera persona. En un estudio, los mismos investigadores encontraron que las personas tienden a describir situaciones, como 'mi amigo me compró flores', o 'tengo una multa de estacionamiento', de lo que otros humanos pueden inferir fácilmente sus reacciones afectivas implícitas. Llegaron a la conclusión de que la semántica composicional puede proporcionar una fuerte evidencia del sentimiento asociado con un evento dado.

Crédito:Wu et al.
En otro estudio, los investigadores intentaron basar las descripciones lingüísticas de los acontecimientos de las personas en las teorías del bienestar y la felicidad. Al analizar un corpus de microblogs privados extraídos de una aplicación llamada Echo, examinaron hasta qué punto diferentes explicaciones teóricas podrían explicar la variación en las puntuaciones de felicidad que los usuarios de Echo otorgaron a los eventos diarios de sus vidas.
"Es un desafío generalizar un evento afectivo y asociarlo con teorías del bienestar, "Jiaqi Wu, uno de los investigadores que realizó el estudio, dijo a TechXplore. "En nuestra investigación anterior, notamos que no existe una sola teoría que pueda predecir el sentimiento de todos los eventos afectivos. El objetivo de nuestro trabajo reciente fue identificar semánticas compositivas específicas que caracterizan el sentimiento de los eventos e intentan modelar la felicidad en un nivel superior de generalización. Sin embargo, encontrar características genéricas para modelar el bienestar sigue siendo un desafío ".
El objetivo principal del estudio reciente llevado a cabo por Wu y sus colegas fue investigar la efectividad de los métodos tradicionales de aprendizaje automático ricos en funciones y los métodos de aprendizaje profundo para la clasificación de contenido afectivo. Lograr esto, identificaron una serie de rasgos que caracterizan la felicidad en el contenido afectivo y los aplicaron a un clasificador tradicional, Bosque boscoso, y una CNN.
"Nuestro proyecto, llamado CruzAffect, incluye el desarrollo de dos modelos diferentes:un método de aprendizaje automático tradicional (es decir, bosque XGBoosted) y una CNN de aprendizaje profundo con incrustación de GloVe, ", Dijo Wu." Utilizamos funciones sintácticas, rasgos emocionales, y características de perfil, y su desempeño es estable para diferentes tareas de clasificación de contenido afectivo ".
Esencialmente, los investigadores evaluaron el rendimiento de dos modelos de aprendizaje automático diferentes para la clasificación de contenido afectivo (bosque XGBoosted y CNN), ambos analizaron el contenido en función de las características que habían identificado previamente. Éstos incluyen:
Estas características permitieron a los investigadores descubrir indicadores esenciales de participación social y control que diferentes personas podrían ejercer durante los momentos felices. En su estudio, entrenaron el modelo XGBoosted y CNN con aprendizaje supervisado en un conjunto de datos de 10, 000 fragmentos de texto etiquetados. También entrenaron los modelos para generar pseudo-etiquetas para 70, 000 fragmentos de código sin etiquetar utilizando un enfoque semi-supervisado por arranque, ya que esto les permitió ampliar su conjunto de datos. Todos estos fragmentos de texto se extrajeron de la base de datos HappyDB.

Arquitectura de CNN. Crédito:Wu et al.
"Los hallazgos significativos de nuestro estudio incluyen patrones sintácticos interesantes que se repiten en diferentes dominios, ", Dijo Wu." Es probable que tales patrones lingüísticos estén asociados con las teorías del bienestar. También encontramos que las características que incluyen conocimiento experto, como el diccionario LIWC puede mejorar el rendimiento del modelo tradicional, así como el modelo de aprendizaje profundo en las tareas de clasificación de contenido afectivo ".
Los investigadores evaluaron los modelos XGBoosted forest y CNN en la clasificación binaria de etiquetas de agencia y sociales, así como en la predicción multiclase de etiquetas de concepto. Sus evaluaciones arrojaron resultados prometedores, sugiriendo que las características identificadas por ellos son particularmente efectivas para clasificar el contenido afectivo. Aunque el modelo basado en CNN funcionó mejor en tareas de clasificación de clases múltiples, el modelo tradicional de aprendizaje automático logró resultados comparables utilizando las características que habían identificado previamente.
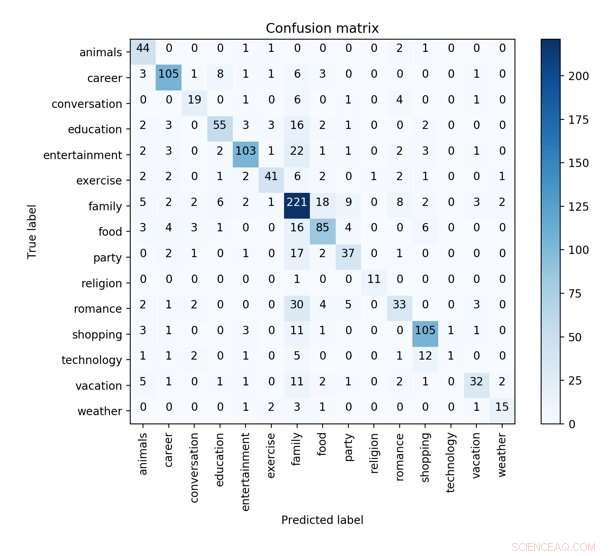
La matriz de confusión del mejor modelo de CNN con sintáctico, características emocionales y de perfil en una validación cruzada de 10 veces para predecir las características de los conceptos. Crédito:Wu et al.
El estudio realizado por Wu y sus colegas descubrió temas generales que son recurrentes en las descripciones de las personas de los momentos felices. En el futuro, sus hallazgos podrían informar el desarrollo de nuevos modelos para tareas de clasificación afectiva, permitiendo a los investigadores predecir de manera efectiva el bienestar y la felicidad mediante el análisis del contenido de fragmentos de texto.
"Ahora exploraré el análisis de eventos afectivos multidominio, e investigar un modelo mejor para fundamentar las descripciones lingüísticas de los eventos que experimentan los usuarios en teorías del bienestar y la felicidad, ", Dijo Wu." Después de comprender la relación entre el contenido afectivo y las teorías del bienestar, podríamos recolectar eventos afectivos generales que están altamente relacionados con el bienestar ".

El equipo de investigadores que realizó el estudio. Crédito:Wu et al.
© 2019 Science X Network














