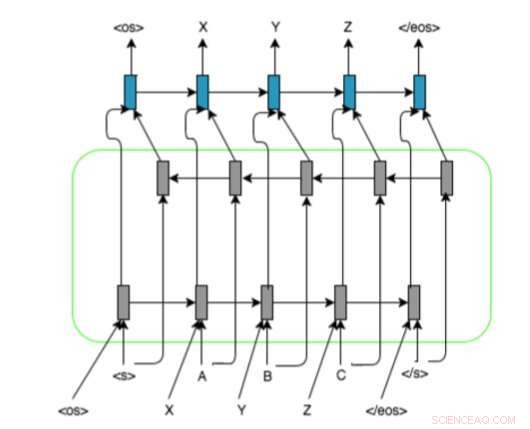
Arquitectura de modelo basada en RNN de los investigadores con codificador-decodificador LSTM bidireccional y representación de alineación en secuencias de entrada. Usan y, , y marcadores para rellenar las secuencias de grafemas / fonemas a una longitud fija. Crédito:Ngoc Tan Le et al.
Un equipo de investigadores de la Universidad de Quebec en Montreal y de la Universidad Nacional de Vietnam en Ho Chi Minh (VNU-HCM) ha desarrollado recientemente un enfoque para la transliteración automática basado en redes neuronales recurrentes (RNN). La transliteración implica la traducción fonética de palabras en un idioma de origen determinado (por ejemplo, francés) a palabras equivalentes en un idioma de destino (por ejemplo, vietnamita).
Vía transliteración, una palabra individual se transforma en una palabra fonéticamente equivalente en otro sistema de escritura. Esta transformación generalmente se basa en un gran conjunto de reglas definidas por lingüistas, que determinan cómo se alinean los fonemas, teniendo en cuenta el origen de una palabra y el sistema fonológico de la lengua de destino.
En años recientes, Los investigadores han desarrollado varios enfoques de aprendizaje profundo para la traducción automática, que han resultado ser una alternativa valiosa a los enfoques estadísticos existentes. Estos resultados prometedores motivaron al equipo de investigadores de la Universite du Quebec a Montreal y VNU-HCM a desarrollar un enfoque de aprendizaje profundo para la transliteración automática.
Su enfoque utiliza redes neuronales recurrentes (RNN), ya que se ha encontrado que son particularmente útiles para tratar problemas similares. Los investigadores observaron que la mayoría de los métodos de última generación de grafema a fonema se basaban principalmente en el uso de asignaciones de grafema-fonema, mientras que los RNN no requieren ninguna información de alineación.
"Los modelos de grafema a fonema son componentes clave en el reconocimiento automático de voz y los sistemas de texto a voz, "explicaron los investigadores en su artículo, que se publicó en la Biblioteca digital ACM. "Con pares de idiomas de bajos recursos que no tienen léxicos de pronunciación disponibles y bien desarrollados, Los modelos de grafema a fonema son particularmente útiles. Estos modelos se basan en alineaciones iniciales entre la fuente del grafema y las secuencias objetivo del fonema ".
En su estudio, los investigadores introdujeron un nuevo método para lograr la transliteración de máquinas de bajos recursos, que utiliza modelos basados en RNN e información de alineación para las secuencias de entrada. Dada una palabra en un idioma determinado que no está presente en el diccionario de pronunciación bilingüe, su sistema puede predecir automáticamente su representación fonémica en el idioma de destino.
"Inspirado por métodos de traducción basados en redes neuronales recurrentes secuencia a secuencia, La investigación actual presenta un enfoque que aplica una representación de alineación para las secuencias de entrada y las incrustaciones de origen y destino entrenadas previamente para superar el problema de transliteración para un par de idiomas de bajos recursos. ", explicaron los investigadores en su artículo.
Este nuevo enfoque combina varias técnicas basadas en redes neuronales y aprendizaje profundo, incluidos codificadores-decodificadores, mecanismos de atención, Representación de alineación para secuencias de entrada e incrustaciones de origen y destino previamente entrenadas. Los investigadores evaluaron su método en una tarea de transliteración que involucró pares de idiomas de bajos recursos francés-vietnamita, obteniendo resultados muy prometedores.
"La evaluación y los experimentos con francés y vietnamita mostraron que con solo un pequeño diccionario de pronunciación bilingüe disponible para entrenar los modelos de transliteración, se obtuvieron resultados prometedores, "escribieron los investigadores.
Según los investigadores, su estudio fue uno de los primeros en analizar el idioma vietnamita en una tarea de transliteración utilizando RNN. Su método obtuvo resultados notables, superando a otros enfoques de última generación basados en estadísticas y basados en secuencias de múltiples articulaciones.
El nuevo sistema ideado por los investigadores puede aprender de manera efectiva y automática las regularidades lingüísticas de pequeños diccionarios de pronunciación bilingües. Aunque su estudio lo aplicó específicamente a las tareas de transliteración franco-vietnamita, también podría extenderse a cualquier otro par de idiomas de escasos recursos para el que se disponga de un diccionario de pronunciación bilingüe.
"En el trabajo futuro, tenemos la intención de probar nuestro enfoque propuesto con un diccionario de pronunciación bilingüe más grande, así como estudiar otros enfoques, como semi-supervisado o no supervisado, "Los investigadores escribieron en su artículo." También tenemos la intención de investigar la transferencia de aprendizaje utilizando otras tareas o lenguajes de PNL en entornos de bajos recursos ".
© 2019 Science X Network