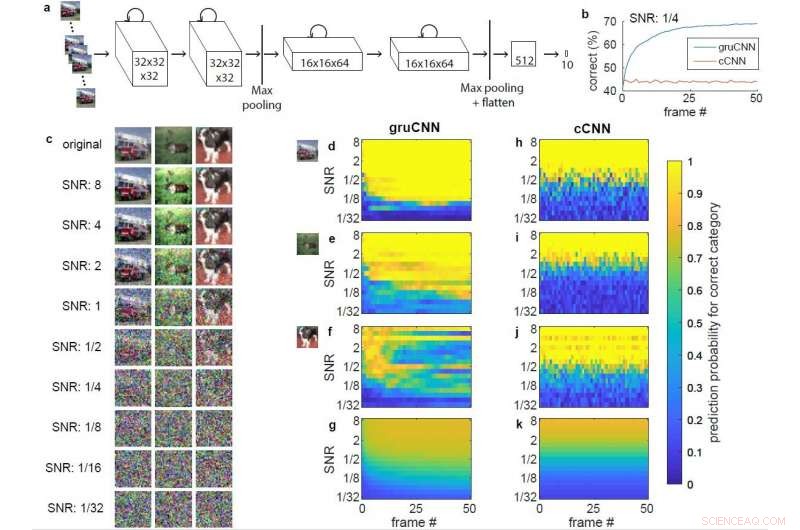
Arquitectura y datos de ejemplo. a) Arquitectura de gruCNN. La actividad de cada canal depende tanto de la entrada actual como del estado anterior. b) Rendimiento de clasificación del ejemplo gruCNN y cCNN cuando todas las secuencias de prueba tenían una SNR de 1/4. c) Imagen original e imagen con diferentes SNR para un camión de bomberos (categoría camión) un reno (categoría ciervo), y un perro, se muestra sin jitter. d – k) Probabilidades predichas codificadas por colores (salida de softmax) de la categoría de imagen correcta (positiva) para gruCNN (d – g) y cCNN (h – k). Los ejes horizontales muestran probabilidades predichas sobre 51 fotogramas, ejes verticales en un rango de SNR. d) &h) ye) &i) corresponden al desempeño en los ejemplos de camiones de bomberos y renos, respectivamente. La probabilidad predictiva en SNRs bajas continúa mejorando sobre los marcos para las predicciones gruCNN, pero son relativamente constantes para el cCNN. f) &j) Datos para el tercer ejemplo (el perro), en el que el gruCNN falla (lo cual es raro) mientras que el cCNN predice la categoría correctamente en la mayoría de las SNR. La probabilidad promedio predicha para la categoría de imagen correcta (positiva) para los 10, Se muestran 000 imágenes de prueba en g) &k). Crédito:Till S. Hartmann / arXiv:1811.08537 [cs.CV].
En los ultimos años, Las redes neuronales convolucionales clásicas (cCNN) han dado lugar a avances notables en la visión por computadora. Muchos de estos algoritmos ahora pueden categorizar objetos en imágenes de buena calidad con alta precisión.
Sin embargo, en aplicaciones del mundo real, como la conducción autónoma o la robótica, Los datos de imágenes rara vez incluyen imágenes tomadas en condiciones ideales de iluminación. A menudo, las imágenes que las CNN necesitarían para procesar presentan objetos ocluidos, distorsión de movimiento, o baja relación señal / ruido (SNR), ya sea como resultado de una calidad de imagen deficiente o niveles de luz bajos.
Aunque las cCNN también se han utilizado con éxito para eliminar el ruido de las imágenes y mejorar su calidad, estas redes no pueden combinar información de múltiples cuadros o secuencias de video y, por lo tanto, los humanos las superan fácilmente en imágenes de baja calidad. Hasta S. Hartmann, un investigador de neurociencia en la Escuela de Medicina de Harvard, ha realizado recientemente un estudio que aborda estas limitaciones, introduciendo un nuevo enfoque de CNN para analizar imágenes ruidosas.
Hartmann, que tiene experiencia en neurociencia, ha pasado más de una década estudiando cómo los humanos perciben y procesan la información visual. En años recientes, se sintió cada vez más fascinado por las similitudes entre las CNN profundas utilizadas en la visión por computadora y el sistema visual del cerebro.
En la corteza visual, área del cerebro especializada en procesar información visual, la mayoría de las conexiones neuronales se realizan en direcciones laterales y de retroalimentación. Esto sugiere que hay mucho más en el procesamiento visual que las técnicas empleadas por las cCNN. Esto motivó a Hartmann a probar capas convolucionales que incorporan procesamiento recurrente, que es vital para el procesamiento de la información visual del cerebro humano.
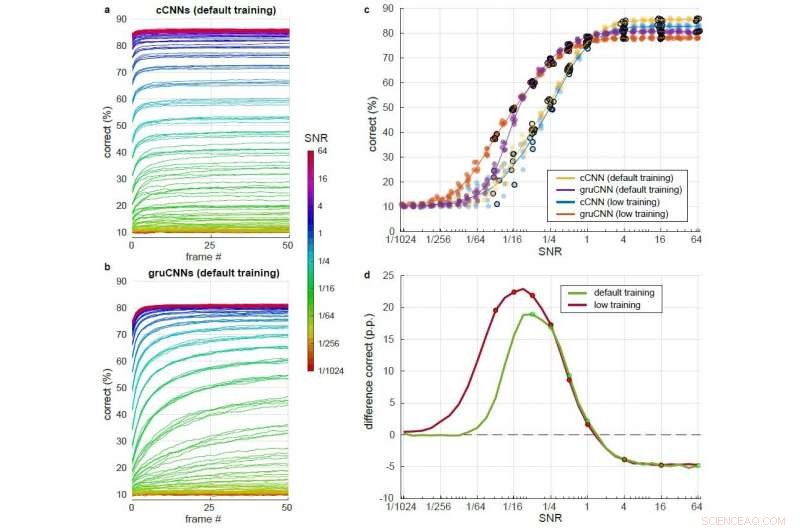
Comparación detallada de cCNN con inferencia bayesiana y rendimiento gruCNN en una amplia gama de niveles de SNR. Cada arquitectura de modelo se probó después del entrenamiento con SNR ligeramente más altas (entrenamiento predeterminado) y después del entrenamiento con SNR ligeramente más bajas (entrenamiento bajo). a) &b) Porcentaje correcto en el transcurso de 51 fotogramas para diferentes SNR (codificadas por colores) utilizando el entrenamiento predeterminado para a) el cCNN (con inferencia bayesiana) yb) el gruCNN. c) Puntos:clasificación correcta de las arquitecturas modelo en el último fotograma. Se agregó jitter en los valores de SNR para aumentar la legibilidad de los gráficos, pero no estaba en los datos. Líneas:rendimiento medio de los cinco modelos por arquitectura. d) Rendimiento medio de las gruCNN menos el rendimiento medio de las cCNN para modelos entrenados con SNR por defecto y más bajas (verde y rojo, respectivamente). Los niveles de SNR utilizados durante el entrenamiento se indican mediante puntos. Crédito:Till S. Hartmann / arXiv:1811.08537 [cs.CV].
Usando conexiones recurrentes dentro de las capas convolucionales de CNN, El enfoque de Hartmann garantiza que las redes estén mejor equipadas para procesar el ruido de píxeles, como el presente en imágenes tomadas en condiciones de poca luz. Cuando se prueba en secuencias de video ruidosas simuladas, Las CNN recurrentes (gruCNN) funcionaron mucho mejor que los enfoques clásicos, clasificar con éxito objetos en videos simulados de baja calidad, como las que se toman por la noche.
Agregar conexiones recurrentes a una capa convolucional finalmente agrega memoria espacialmente limitada, permitiendo que la red aprenda a integrar información a lo largo del tiempo antes de que la señal sea demasiado abstracta. Esta función puede resultar especialmente útil cuando la calidad de la señal es baja, como en imágenes ruidosas o tomadas en condiciones de poca luz.
En su estudio, Hartmann descubrió que las cCNN funcionaban bien en imágenes con SNR altas, gruCNNs, los superó en imágenes de baja SNR. Incluso agregando integraciones temporales óptimas de Bayes, que permiten que las cCNN integren múltiples marcos de imagen, no coincidió con el rendimiento de gruCNN. Hartmann también observó que a bajas SNR, Las predicciones de las gruCNN tenían niveles de confianza más altos que las producidas por las cCNN.
Mientras que el cerebro humano ha evolucionado para ver en la oscuridad, la mayoría de las CNN existentes aún no están equipadas para procesar imágenes borrosas o ruidosas. Al proporcionar a las redes la capacidad de integrar imágenes a lo largo del tiempo, el enfoque ideado por Hartmann podría eventualmente mejorar la visión por computadora hasta el punto en que coincida, o incluso excede, rendimiento humano. Esto podría ser enorme para aplicaciones como vehículos autónomos y drones, así como en otras situaciones en las que una máquina necesita "ver" en condiciones de iluminación no ideales.
El estudio realizado por Hartmann podría allanar el camino para el desarrollo de CNN más avanzadas que puedan analizar imágenes tomadas en condiciones de poca luz. El uso de conexiones recurrentes en las primeras etapas del procesamiento de redes neuronales podría mejorar enormemente las herramientas de visión por computadora, superando las limitaciones de los enfoques clásicos de CNN en el procesamiento de imágenes o secuencias de video ruidosas.
Como siguiente paso, Hartmann podría ampliar el alcance de su investigación explorando aplicaciones de la vida real de las gruCNN, probándolos en una amplia gama de escenarios del mundo real. Potencialmente, Este enfoque también podría usarse para mejorar la calidad de videos caseros de aficionados o inestables.
© 2018 Science X Network