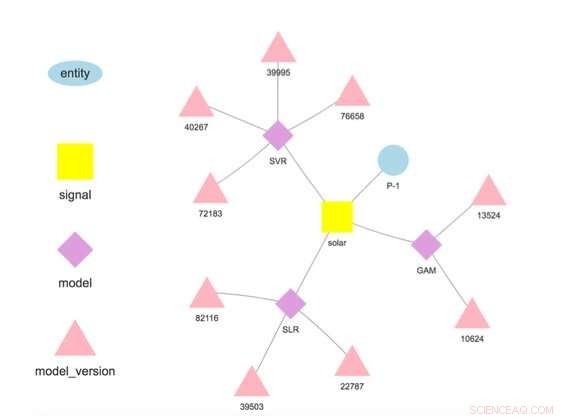
Figura 1. Jerarquía del modelo para una entidad y una señal seleccionadas. Crédito:IBM
Esta semana en la Conferencia Internacional sobre Minería de Datos, El científico de IBM Research-Ireland Francesco Fusco demostró IBM Research Castor, un sistema para administrar modelos y datos de series de tiempo a escala y en la nube. Las empresas de hoy funcionan según las previsiones. Ya sea una corazonada de lo que creemos que va a suceder o el producto de un análisis cuidadosamente perfeccionado, tenemos una imagen de lo que va a suceder y actuamos en consecuencia. IBM Research Castor es para empresas impulsadas por IoT que necesitan cientos o miles de pronósticos diferentes para series de tiempo. Aunque el modelo para un pronóstico individual puede ser pequeño, mantenerse al día con la procedencia y el rendimiento de este número de modelos puede ser un desafío. A diferencia de los casos impulsados por IA que utilizan una pequeña cantidad de grandes modelos para el procesamiento de imágenes o el lenguaje natural, este trabajo tiene como objetivo las aplicaciones de IoT que necesitan una gran cantidad de modelos más pequeños.
Nuestro sistema proporciona un conjunto rico pero selectivo de capacidades para modelos y datos de series de tiempo. Ingesta datos de dispositivos IoT u otras fuentes. Proporciona acceso a los datos mediante semántica, permitiendo a los usuarios recuperar datos como este:getTimeseries (myServer, "Tienda1234", "ingresos por hora").
Almacena modelos escritos en R o Python para entrenamiento y puntuación. Cada modelo está asociado con una entidad que describe dónde se originan los datos, como "Store1234" arriba, y una señal que describe lo que se mide, como "ingresos por hora". Los modelos se entrenan y puntúan en frecuencias definidas por el usuario, y a diferencia de muchas otras ofertas, las previsiones se almacenan automáticamente.
Los científicos de datos implementan modelos mediante la implementación de un flujo de trabajo de cuatro pasos:
Una vez implementado el modelo, el sistema realiza el entrenamiento y la puntuación, almacenar automáticamente el modelo entrenado y los resultados de la previsión. Los datos utilizados en la formación y la puntuación no necesitan originarse en la plataforma, permitiendo que los modelos usen datos de múltiples fuentes. De hecho, esta es una motivación clave para nuestro trabajo:hacer pronósticos de valor agregado basados en múltiples fuentes de datos. Por ejemplo, una empresa puede combinar algunos de sus propios datos con datos adquiridos de un tercero, como las previsiones meteorológicas, para predecir una cantidad de interés.
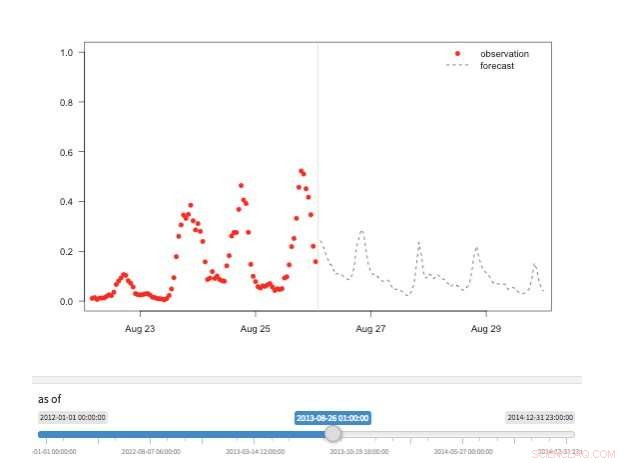
Figura 2. Vista de la “máquina del tiempo” que muestra las observaciones y pronósticos disponibles para diferentes puntos de la historia. Crédito:IBM
Nuestro sistema almacena modelos separados de los parámetros de configuración y tiempo de ejecución. Esta separación permite cambiar algunos detalles de un modelo, como la clave API para acceder a datos de terceros o la frecuencia de puntuación, sin redespliegue. Se admiten y fomentan varios modelos para la misma variable objetivo para permitir comparaciones de pronósticos de diferentes algoritmos. Los modelos se pueden encadenar entre sí para que la salida de un modelo forme la entrada a otro como en un conjunto. Un modelo entrenado en un conjunto de datos específico representa una versión del modelo, que también se rastrea. Así es posible establecer la procedencia de modelos y pronósticos (Figura 1).
Hay varias vistas disponibles para explorar los valores de pronóstico. Por supuesto, los valores mismos pueden recuperarse y visualizarse. También admitimos una vista de "máquina del tiempo" que muestra los últimos pronósticos y las últimas observaciones (Figura 2). En esta vista interactiva, el usuario puede seleccionar diferentes puntos del historial y ver qué información estaba disponible en ese momento. También apoyamos una vista de la evolución del pronóstico que muestre pronósticos sucesivos para el mismo punto en el tiempo (Figura 3). De esta manera, los usuarios pueden ver cómo cambiaron los pronósticos a medida que se acercaba el tiempo objetivo.
Bajo el capó, IBM Research Castor hace un uso intensivo de la computación sin servidor para proporcionar elasticidad de recursos y control de costos. Las implementaciones típicas ven modelos entrenados cada semana o cada mes y puntuados cada hora. En el momento de entrenar o anotar, se crea una función sin servidor para cada modelo, permitiendo que cientos de modelos entrenen o puntúen en paralelo en el momento deseado. Después de que termine este trabajo, el recurso informático desaparece hasta que se vuelve a necesitar. En un flujo de trabajo más convencional, Las máquinas virtuales o los contenedores en la nube están inactivos cuando no están en uso, pero siguen generando costos.
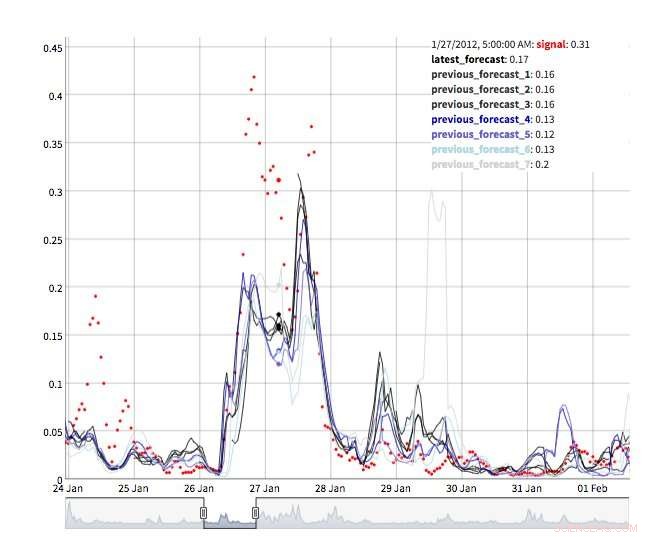
Figura 3. Evolución del pronóstico. Crédito:IBM
IBM Research Castor se despliega de forma nativa en IBM Cloud utilizando los últimos servicios como DashDB de IBM, Componer, Funciones en la nube, y Kubernetes para proporcionar un sistema robusto y confiable. Con una cuenta autorizada en IBM Cloud, IBM Research Castor se implementa en cuestión de minutos, haciéndolo ideal para pruebas de concepto, así como para proyectos de ejecución más larga. Los paquetes de cliente / SDK para Python y R se proporcionan para que los científicos de datos puedan comenzar a trabajar rápidamente en un entorno familiar y los equipos de visualización puedan aprovechar los marcos familiares como Django y Shiny. Si no se ajustan a su aplicación, la API de mensajería basada en JSON también está disponible.
Esta historia se vuelve a publicar por cortesía de IBM Research. Lea la historia original aquí.